- 学习教案:https://zhuanlan.zhihu.com/p/364367221
- 作者:Kissrabbit
- 作者书籍:《YOLO目标检测》
今天大盘压制得好厉害,港股没想到也这鬼样子,算了,还是学习YOLO吧!!!
小白真的是好多都不懂,原作精湛简短BLOG,在我的阅读啰嗦笔记后,长度x6!!!
一、YOLOv1的网络架构
作为One-stage工作的开山之祖,YOLOv1以其简洁的网络结构和GPU实时检测速度而一鸣惊人,打破了R-CNN的“垄断”地位,为目标检测领域带来巨大的变革。
以现在的眼光来看待YOLOv1,会发现其中很多弊端,不过,在当年,YOLOv1可是炙手可热,为后来许多one-stage工作提供了框架基础。其里程碑意义不可磨灭。
YOLO-v1最大的特点就在于:仅使用一个卷积神经网络端到端地实现检测物体的目的。其网络整体的结构如下图所示:
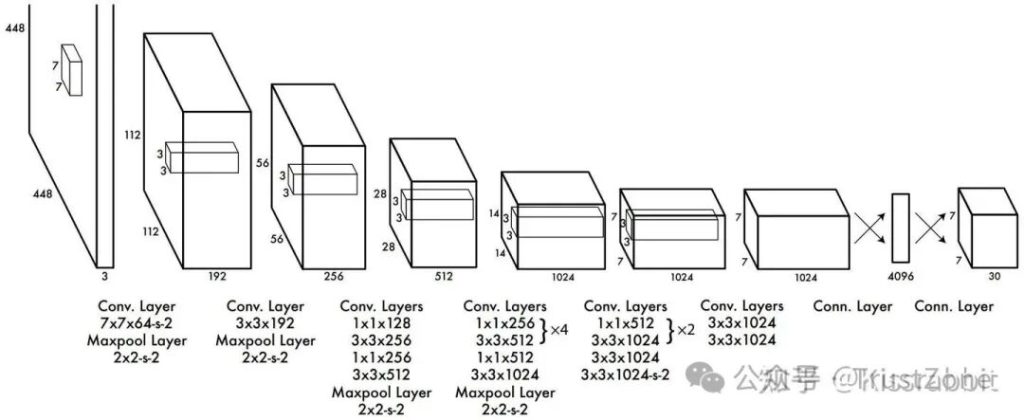
这个分拣中心(YOLO网络)的任务非常明确:收到一张图片(一个包裹),就要立刻判断出这张图片里有什么物体(包裹里是什么东西)、以及它们的位置(东西放在包裹的哪个位置)。最终,它需要输出 30个 最终信息。这30个信息就包含了“有什么”和“在哪里”的答案。
详解分拣流水线(图片)
我们现在就从左到右,跟着包裹(图片)走一遍这个流水线:
1. 入口 - 原始包裹 (Input)
- 尺寸:448 x 448 x 3
- 解读: 一个固定的、标准化大小的包裹。
448x448是包裹的尺寸,3代表这个包裹有3种不同的信息单(对应颜色的RGB三通道)。
2. 初级分拣 - 粗看 (前面的卷积和池化层)
- 包裹进入流水线,先经过几个大的、快速的分拣机器。
- 例如:
Conv 7x7/2, 64:第一台机器。它用一个7x7的大篮子,一次看一大片区域,快速分出64种最明显的特征(比如是硬的还是软的,是什么颜色的)。Maxpool 2x2/2:一台压缩打包机。它把刚才分拣出的信息进行压缩,只保留每个区域里最最重要的那条信息,扔掉次要细节。这样包裹体积就变小了(尺寸减半),方便后续精细处理。
- 这个过程会重复几次(看图中有好几组
Conv和Maxpool),每经过一次,包裹就被压缩得更小(尺寸从448->224->112->56...),但贴在上面的“信息标签”种类却越来越多(通道数从3->64->192->256...)。这意味着我们对包裹的观察从“整体粗看”进入了“局部细看”。
3. 精细分拣 - 细看 (后面的卷积层)
- 包裹变得很小了(比如到了
14x14,7x7),现在开始进行极度精细的检查。 - 例如:
Conv 3x3, 1024:工人拿着3x3的小放大镜,在每一个小格子上仔细检查,找出1024种极其细微的特征(比如是不是有轮子、有没有玻璃、是不是有纹理)。这个时候,7x7的尺寸意味着我们把原始图片划分成了7x7=49个网格,每个网格都负责检测自己区域内的物体。
- 最终,包裹变成了一个
7x7 x 1024的“信息块”。 你可以理解为:一个7x7的网格,每个网格里都有1024条关于这个网格的详细描述信息。
4. 决策中心 - 开会得出结论 (全连接层)
- 现在,这49个网格的1024条信息(总共
7*7*1024 = 49,984条信息)要一起开会,商量出最终结果。 - 如果让5万条信息直接一起吵,会乱套(参数爆炸)。所以需要一个高效的会议流程:
- 第一场小会 (FC 256): 让5万条信息先内部讨论,选举出256个最有代表性的“意见领袖”(即降维到256个值)。这一步大大减少了混乱。
- 第二场大会 (FC 4096): 这256个意见领袖再和4096个“专家评委” 开会,进行深入分析和辩论。
- 最终裁决 (FC 30): 最后,这4096个专家综合意见,投票得出最终的30个结论。这30个结论就是整个系统的输出,包含了每个网格预测的物体类别和位置坐标。
整个图片描绘的过程就是:
原始图片→ 不断压缩尺寸、增加信息深度(卷积池化)→ 得到每个网格的丰富特征→ 高效地开会讨论(全连接层)→ 输出最终预测结果(30个值)
为什么最后要用全连接层?因为物体在哪、是什么,需要综合整个图片的所有信息来判断。比如判断一个格子里的东西是不是“车”,可能需要看它旁边有没有“轮子”的格子。全连接层让所有网格的信息都能相互沟通,做出最全局、最准确的判断。
不着急,我是小白,卷积池化我是第一次听说。卷积和池化是卷积神经网络(CNN)中两个非常核心的操作,它们就像一位“特征提取师”和一位“数据压缩师”,协同工作让计算机能够“看懂”图像。
🎯 打个比方:看图说话
想象一下,你拿到一张复杂的照片,需要向别人描述它:
- 卷积就像你拿出放大镜,仔细扫描图像的每一个小区域,寻找并勾勒出基础的线条、棱角、色块和纹理。比如,“这里有一条斜线”、“那里有个蓝色块”。
- 池化就像你看完细节后,退后一步,忽略那些细微的位置差异,总结出更大、更显著的特征。比如,“不管这条线具体在左边还是右边一点点,总之这个区域有一个明显的向右的斜线趋势”。
✨ 核心概念通俗解读
- 卷积:特征提取的“放大镜”
卷积操作的核心目的是从原始图像中提取出有用的特征,比如边缘、角点、纹理等。
- 它是什么:卷积通过一个称为卷积核(或滤波器)的小矩阵(比如3x3或5x5),在输入图像上滑动。在每个位置,卷积核与图像对应的局部区域进行对应元素相乘再求和的运算,得到一个数值输出。这个过程生成的新矩阵称为特征图,它记录了原图中特定特征的出现情况和位置。
- 为什么需要它:直接处理原始图像像素数据量太大,且像素本身不代表高级语义。卷积核通过其内部的权重,充当了特征检测器的角色。不同的卷积核可以检测不同的特征(如边缘、锐化、模糊)。
- 关键特性:
- 局部连接:每个神经元只与输入数据的一个局部区域相连,这大大减少了参数数量。
- 权值共享:同一个卷积核在整个输入数据上滑动并使用相同的参数,这不仅进一步减少了参数数量,还使得网络具有平移不变性的雏形——无论特征出现在图像的哪个位置,都能被相同的卷积核检测到。
- 池化:特征降维的“摘要员”
池化操作通常紧跟在卷积层之后,其主要目的是对卷积提取到的特征进行压缩和聚合,保留最显著的信息,同时降低数据维度。
- 它是什么:池化也是在特征图上用一个窗口(如2x2)滑动,但操作比卷积更简单:没有需要学习的参数,只是对窗口内的值进行一个简单的聚合统计。
- 为什么需要它:
- 降低计算量和内存消耗:减少特征图的尺寸,从而显著减少后续操作的参数和计算量。
- 防止过拟合:通过减少参数数量,降低了模型的复杂度,有助于提高泛化能力。
- 增强平移不变性:池化能够帮助输入的表征近似不变。当我们对输入进行少量平移时,经过池化函数后的大多数输出并不会发生改变。当我们关心某个特征是否出现而不关心它出现的具体位置时,这个性质非常有用。
- 常见类型:
- 最大池化:取窗口内的最大值。这能更好地保留纹理等显著特征。
- 平均池化:取窗口内的平均值。这能更好地保留背景的整体信息。
📊 卷积与池化的对比
为了让你更清晰地理解它们的区别和联系,我准备了一个表格:
| 特性 | 卷积 | 池化 |
|---|---|---|
| 核心作用 | 特征提取:从数据中检测和抽取局部特征(如边缘、角点) | 特征降维/压缩:减少数据尺寸,保留主要信息,降低计算复杂度 |
| 操作方式 | 卷积核与输入局部区域进行加权求和(线性运算) | 对输入局部区域进行聚合统计(如取最大、平均值) |
| 主要参数 | 卷积核大小、步长、填充、卷积核数量(决定输出通道数) | 池化窗口大小、步长(通常等于窗口大小以实现不重叠) |
| 是否可学习 | 是(卷积核权重通过训练优化) | 否(没有参数,是固定操作) |
| 输出结果 | 特征图(通常尺寸变化,通道数可能增加) | 降采样后的特征图(尺寸减小,通道数通常不变) |
| 核心价值 | 通过局部连接和权值共享高效提取特征,是CNN的核心 | 压缩数据、扩大感受野、增强模型泛化能力和平移不变性 |
💎 简单总结
可以把卷积神经网络理解成一个多层的信息提炼工厂:
- 卷积层负责抽取原材料(原始图像)中的有价值成分(特征)。
- 池化层负责浓缩这些提取物,剔除冗余和杂质,保留精华以便后续进一步加工或直接使用。
它们俩配合,使得CNN能够高效地从图像中学习到从简单到复杂的层次化特征。
好了咱们继续
YOLO-v1的backbone网络是仿照GoogLeNet搭建的,但并没有采用Inception模块,而是使用 1x1 和 3x3 卷积层来堆砌的,所以网络的结构是非常简单的。基本上,照葫芦画瓢,我们就能搭建出整体的网络。
在那个年代,图像分类任务中,网络最后会将卷积输出的特征图拉平(flatten),得到一个一维向量,然后再接若干全连接层做预测。
YOLO-v1继承了这个思想,最后的 7 x 7 x 1024 (维度顺序: H x W x C )的特征图成 7 x 7 x 1024 大小的向量,这个一维向量再接一层全连接层。但是,这里我们需要注意一点,如果只看图中的结构,是只有一个4096的全连接层,我们不妨算一下这里的参数量:
仅仅这一层全连接,参数的量级就已经是8个0了,过于巨大。
因此,原文作者实际是先用了一个256的全连接先缓一缓,然后再连接4096,从而避免参数爆炸,这样我们再算一下:
少了一个数量级,似乎也没有好到哪去。当然,参数多并不意味着模型推理速度就一定会很慢,这些多的参数主要集中在全连接层,而全连接层的运算可以变换成普通的矩阵乘法,这种普通运算对GPU来说,连塞牙缝的资格都没有。但是,从资源占用的角度来看,过大的参数量还是会让研究者头疼的。
尽管如此,YOLOv1还是以其优越的检测性能惊艳全场。
白话啰嗦版本
你可以把YOLO-v1的检测过程想象成一个 “快递分拣中心”:
🏭 第一步:Backbone网络 - 流水线分拣(卷积与池化)
Backbone(主干网络)就像是快递分拣中心的自动化流水线。它的任务是对原始图像进行初步加工和特征提取。
- 输入图像(448x448x3):就像是一个巨大的、未经分拣的快递包裹堆,里面包含了各种信息(颜色、纹理、形状等)。
- 卷积层 (Conv):就像是一组专业的分拣工人,他们拿着特定大小的模板(卷积核,如3x3, 1x1)在包裹堆上扫描,提取出有用的特征。有的工人专门识别边缘(像是包裹的棱角),有的专门识别纹理(像是包裹的表面图案)。这些工人团队(滤波器)越多,能提取的特征种类就越丰富。
- 池化层 (Pooling):就像一个压缩打包机。它把工人提取到的特征图进行压缩(比如从224x224压缩到112x112),只保留最显著、最重要的信息,扔掉一些次要的细节。这样做的好处是减少数据量,让后续处理更高效,并且能让网络更关注于那些最明显的特征。
经过这一系列“工人”和“打包机”的交替工作(卷积和池化层交替),原始的“包裹堆”被加工成了一个非常浓缩、信息密度极高的 “特征包裹” :尺寸为 7x7,但有 1024 个通道(7x7x1024)。你可以把它想象成一个 7x7 的格子铺,每个小格子里都塞了1024种不同的特征信息。
🗺️ 第二步:理解 7x7x1024 的特征图
这个 7x7x1024 的特征图,是理解一切的关键:
- 7x7:意味着原始图像被划分成了 7x7=49个网格(grid cells)。每个网格负责预测其内部可能存在的物体。
- 1024:每个网格都包含了 1024 种不同的特征信息(这些信息是前面的卷积层提取出来的),这些特征可以用来判断这个网格里有什么物体、位置在哪。
这就好比一张地图被划分成了7x7的网格,而每个网格都附带着一本非常详细的、1024页的特征手册。
📦 第三步:Flatten (拉平) - 把立体地图“铺平”
在进入最终决策之前,需要将这个三维的“地图手册”(7x7x1024)转换成一个格式,以便后续的“全连接层”进行处理。
- Flatten操作:就是将这个三维结构 “拉平”成一个一维的长条清单。
- 想象一下,你把这49个网格(7x7)每个网格的1024条特征信息,从头到尾、一丝不苟地抄写在一张极长的纸条上。
- 这个纸条的长度就是
7 * 7 * 1024 = 49,984个数字。这个过程就是Flatten。
为什么要这么做?因为后面的全连接层传统上期望接收一维的向量输入,而不是三维的块状数据。这是一种历史遗留的设计习惯。
🧠 第四步:全连接层 - 最终决策大会
现在,我们有了这张记录了所有网格所有特征的“长纸条”(一维向量)。全连接层就像是公司的高层决策会议,它的任务是分析这份清单,并做出最终判断:每个网格里有没有物体?是什么物体?位置在哪?
- 全连接层的作用:纸条上的每一个信息(那49,984个数字中的每一个)都可以和最终决策的每一个因素(比如“是猫的概率”、“框的宽度”等)进行交互和加权计算。这允许网络综合全局信息来做判断。
- 参数量的例子:
- 如果第一个全连接层有4096个神经元,那么连接这49,984个输入和4096个输出,就需要
49,984 * 4096 ≈ 2.04亿个连接权重(参数)。这就是你提到的“参数量巨大”。 - 为了缓解这个问题,作者在实际设计中加入了一个中间的256维的全连接层(
49,984 -> 256 -> 4096),这样参数量会减少不少,但依然庞大。
- 如果第一个全连接层有4096个神经元,那么连接这49,984个输入和4096个输出,就需要
经过全连接层的分析和计算,网络最终会输出一个 7x7x30 的张量,这49个网格的预测结果(每个网格预测2个边界框和20个类别概率)就都在里面了。
🌟 总结与类比回顾
简单总结一下这个过程:
- 特征提取 (Backbone):像分拣流水线,逐步提取并浓缩图像特征,输出
7x7x1024的“特征块”。 - Flatten (拉平):像把立体地图铺平成一张长长的清单,将三维特征块转化为一维向量(
49,984维)。 - 全连接层:像高层决策会议,分析长清单上的所有信息,综合判断每个网格的物体类别和位置,最终输出检测结果。
YOLO-v1之后的版本也看到了全连接层参数过多的问题,所以在新设计中(如YOLOv2及之后)普遍抛弃了全连接层,采用了其他更高效的技术(如全卷积网络),这使得模型更轻量、更快,并且能适应不同尺寸的输入图像。
事实上,YOLOv1本身最大的弊端就在于“flatten”这种方式本身。
基本上,对于“flatten方式会破坏特征的空间结构信息”的这一观点已经成为业界共识。现在几乎看不到还有哪个one-stage检测模型还会用全连接层来做检测了。
另外,我们注意到,YOLOv1中并没有使用BatchNormalization(BN),这是因为在那个时候,BN还没有兴起。
接着来
🗺️ 1. 为什么说“Flatten破坏空间结构”?
想象一下,YOLOv1的Backbone(主干网络)就像一位细心勘察图像的“侦探”。它通过卷积和池化层,将原始的输入图像(比如448x448像素)浓缩成了一张更有信息量的“特征地图”。这张地图的尺寸是7x7,但每个小格子里(我们称之为“网格”)却存储了1024条不同的特征信息(通道数),相当于每个网格都有一本厚厚的、记录了1024条特征的“档案”。
现在,为了连接传统的全连接层做预测,需要将这张三维的(7(高)x 7(宽)x 1024(通道))“特征地图”拉平(Flatten)成一个一维的长向量(就像把一本书的书页全部撕下来,按顺序排成一条长长的纸条)。
这样做的主要问题在于:
- 空间关系丢失:在原来的“特征地图”上,每个网格的位置关系(上下左右、中心或边缘)是非常明确且重要的,这直接关系到物体在图像中的实际位置。Flatten操作破坏了这个二维的空间结构,全连接层在处理这个一维向量时,很难再有效利用这些位置信息。
- 参数量巨大:如你之前所知,拉平后的向量维度很高(771024=49,984维),直接连接大尺寸的全连接层会导致参数量的急剧膨胀,增加了计算量和过拟合的风险。
正因为这些弊端,后来的YOLO版本(如v2、v3等)及大多数单阶段(one-stage)检测模型都抛弃了这种“Flatten + 全连接层”的设计,转而采用全卷积网络(FCN) 的结构,直接在特征图上进行预测,完美保留了空间结构信息,也更加高效。
⚖️ 2. 为什么YOLOv1没有使用BatchNormalization(BN)?
这主要是一个技术发展时序的问题。
- BN技术出现稍晚:YOLOv1论文发表于2015年。而BatchNormalization(批量归一化)这篇开创性的论文由Sergey Ioffe和Christian Szegedy在2015年才提出,并逐渐被广泛认可和采用。在YOLOv1设计和发表的时期,BN还没有成为深度学习模型尤其是卷积神经网络中的标准配置。
- BN的好处后来才凸显:BN层通过规范化每一层的输入,可以加速模型收敛、允许使用更大的学习率,并有一定的正则化效果(减少过拟合)。但这些好处是在其被提出后,经过大量实践才得到充分验证的。
因此,YOLOv1的作者在当时没有使用BN层,主要是因为它还没有成为那个时候的常见做法。在YOLOv1之后的版本(如YOLOv2)中,BN层就被立刻引入并证明了其有效性,为模型性能带来了显著提升。
📊 核心概念对比
为了让你更清晰地理解它们的区别和背景,我准备了一个简单的表格:
| 特性 | Flatten + 全连接层 (YOLOv1方式) | 全卷积网络 (FCN, 后期YOLO等方式) | BatchNormalization (BN) |
|---|---|---|---|
| 核心作用 | 将卷积提取的空间特征转换成一维向量,以便用全连接层进行预测 | 直接在特征图上进行预测,保持空间结构 | 规范化网络中间层的输入,加速训练并提升稳定性 |
| 主要问题 | 破坏空间结构,参数量巨大,不够灵活 | 保留空间信息,参数更高效,能适应不同输入尺寸 | 在YOLOv1时代尚未兴起和普及 |
| 现状 | 在目标检测中已基本被弃用 | 当前主流的架构设计 | 现代深度学习模型中几乎不可或缺的标准组件 |
💎 简单总结
- Flatten问题:好比把一张城市规划地图(具有明确区域和位置关系)剪碎,再按固定顺序粘成一条长纸带。虽然信息都在,但想快速查某个地方在哪儿、和周围的关系,就变得非常困难了。YOLOv1之后的改进就是直接在地图上做标记,不再需要剪碎。
- BN层缺失:就像YOLOv1这位“老侦探”在破案时,还没有一套标准化的工作流程(BN) 来保证每次勘察的稳定性。后来出现的YOLOv2等“年轻侦探”都学会了这套流程,所以工作起来(训练起来)更快、更稳。
关于BatchNormalization的概念
BN就像是深度学习网络中的一位 “标准化教练”。它的核心工作是在数据进入每一层之前,主动调整数据的分布,使其保持稳定,从而让整个网络的训练过程更快速、更平稳。
你可以把它想象成在一条流水线上,为了保证每个工位(网络中的每一层)的处理效率和质量,都有一个专门的员工负责将上游送来的半成品(数据)进行整理和标准化,然后再交给下游工位。这样下游工位就不需要总是适应变化无常的输入,从而能更专注地完成自己的本职工作。
⚙️ BN是如何工作的?
BN层的工作流程通常紧随在一个卷积层或全连接层之后,在激活函数(如ReLU)之前。它的操作可以概括为以下三个步骤:
- 计算批次统计量:针对当前这一小批(mini-batch)训练数据,BN会计算每个特征通道的均值(mean) 和方差(variance)。
- 标准化:使用第一步计算出的均值和方差,将数据标准化为均值为0、方差为1的分布。具体公式是:
(X - mean) / sqrt(variance + ε),其中ε是一个很小的常数,防止除以零。 - 缩放与平移:这是BN的点睛之笔。上一步的强制标准化可能会改变数据原本有价值的分布,因此BN引入了两个可学习的参数(γ 和 β),对标准化后的数据进行缩放(scaling)和平移(shifting):
Output = γ * X_normalized + β。这使得网络有能力自行决定是否要恢复数据原来的分布,或是保留部分标准化后的特性,从而保持了模型的表达能力。
🎯 为什么需要BN?它带来了哪些好处?
BN的提出主要是为了解决深度神经网络训练中的内部协变量偏移(Internal Covariate Shift) 问题。简单来说,就是网络底层参数的微小更新,会随着网络深度的增加而逐渐放大,导致后面层的输入分布发生剧烈变化,这会让训练变得困难。
BN通过固定每一层输入的分布,带来了诸多好处:
| 好处 | 通俗解释 |
|---|---|
| 加速训练收敛 | 稳定了学习过程。数据分布稳定,使得梯度更新更有意义,网络能更快找到最优解。 |
| 允许使用更大的学习率 | 训练更“大胆”。BN减少了训练对参数尺度的敏感性,使用更大的学习率也不易导致梯度爆炸或消失,从而进一步加速训练。 |
| 缓解梯度消失 | 保证梯度“活力”。它将激活函数的输入值稳定在对其输入敏感的区域(例如对于Sigmoid函数,就是接近0的区域),使得梯度更大,缓解了梯度消失问题。 |
| 有一定的正则化效果 | 减少过拟合。BN在训练时使用小批量的统计量而非全局统计量,会给网络带来一些噪声,类似于Dropout的效果,可以轻微减少过拟合,对其他正则化手段的依赖也降低了。 |
🔄 训练和预测时的区别
这一点非常重要:
- 训练阶段:BN使用当前小批量(mini-batch)数据的均值和方差来进行标准化。
- 预测阶段(推理阶段):此时我们可能只有一个样本或很少的样本,无法计算有意义的批次统计量。因此,BN会使用在整个训练集上预先计算好的移动平均(running mean)和移动方差(running variance) 来进行标准化。
💎 总结
总而言之,BatchNormalization是一个在深度神经网络中用于稳定数据分布、加速训练并提升模型泛化能力的重要技术。它通过标准化每一层的输入,并引入可学习参数来保持模型的表达能力,使得训练更深、更强大的神经网络成为可能。
啰嗦,咱们继续学习!
二、YOLOv1的检测原理
太棒了!这三张截图组合在一起,非常完整地解释了YOLOv1最核心的思想。你觉得不理解非常正常,因为这个设计思路确实非常巧妙,和人的直觉不太一样。
别担心,我们用一个超简单的比喻,把这三张图的内容串起来,你一定能懂。
🧠 核心思想一句话总结
YOLOv1的做法就像是:你有一张照片,然后拿一张透明的、画着7x7格子的网格纸盖在上面,然后你对着每一个小格子问:“这个格子的中心点,是不是某个东西(比如狗、自行车)的中心?如果是,请把这个东西的框画出来,并告诉我是什么东西。”
为什么是 7x7x30?
1. 为什么是 7x7 个格子? (S = 7)
- 原始图片尺寸是
448 x 448像素。 - 网络(Backbone)就像是一个“压缩机”,会把图片不断地缩小、提炼。这个压缩的倍数叫做
stride(步长/降采样率),这里是64倍。 - 所以,最终得到的“压缩后的精华信息图”的尺寸就是:
448 / 64 = 7。所以这张“信息图”有7x7个位置点。 - 每个点,就负责原图中对应的那一片区域(即一个格子)! 这就对应了第三张图里说的
S = 输入尺寸 / 最大stride。
2. 为什么每个格子有30个信息? (5B + C = 30)这是最关键的部分!网络在每个格子(每个点)上,都要输出一大堆预测信息。这些信息主要包括两大部分:
- Bounding Box (bbox) 预测:负责“画框”
- YOLOv1规定,每个格子可以预测
B=2个可能存在的框(因为一个格子里可能重叠多个物体,多一个框就多一次机会)。 - 每个框需要用5个参数来描述:
- 所以,光是“画框”这件事,一个格子就需要
5个参数/框 * 2个框 = 10个参数。
- 置信度 (C / objectness):这个框里到底有没有物体?有多少把握?这个值在0到1之间。可以理解为“框的可信度分数”。
- 框的中心点坐标 (cₓ, cᵧ):这个框的中心点在这个格子内部的相对位置。
- 框的宽和高 (w, h):这个框相对于整个图片的宽度和高度。
- YOLOv1规定,每个格子可以预测
- 类别预测:负责“取名”
- 不管这个格子预测了几个框,这个格子只做一次类别判断(假设一个格子里通常只有一个物体)。
- 使用的数据集是PASCAL VOC,里面有
C=20个类别(比如人、鸟、猫、狗、自行车...)。 - 网络需要输出这20个类别的概率。比如,它可能输出
[0.1, 0.8, 0.05, ...],表示有80%的概率是“狗”。 - 所以,分类需要
20个参数。
- 总和:
画框的参数(10个) + 分类的参数(20个) = 30个参数。- 这就是公式
5B + C(5*2 + 20 = 30)的由来。 - 整个网络的输出就是
7个点 * 7个点 * 30个参数/点 = 一个 7x7x30 的特征图。
- 这就是公式

来看看这个图片
- 网格划分:图片上的黑色网格线,就是把图片划分成了很多个小格子(在YOLOv1里是7x7,这张图划分得更密一些)。
- 逐网格检测:现在,想象YOLOv1算法正在处理这张图。
- 它会注意到左下角的一些格子(比如哈士奇脸部中心的那个格子)。这些格子会给出很高的“置信度”(C),同时输出一个框的参数(cₓ, cᵧ, w, h),这个框会完美地框住这只哈士奇,并且它们的“类别参数”会在“狗”这一项上给出很高的概率(比如0.9)。
- 同样,自行车中间的格子也会做同样的事情:高置信度、输出框住自行车的参数、在“自行车”类别上给出高概率。
所以,YOLOv1的整个过程就是:让每个小格子自己独立地思考,报告它那里有没有物体的中心、物体有多大、是什么东西。最后,我们把所有格子的报告汇总起来,就得到了图片中所有物体的检测结果。
再来
因此,YOLOv1就是在每个网格上去做预测,理想情况下,包含了物体中心点的网格会有很高的置信度输出,而不包含中心点的网格的置信度输出应该十分接近0。https://wxa.wxs.qq.com/tmpl/oc/base_tmpl.html
总的来说,YOLOv1一共有三部分输出,分别是objectness、class以及bbox:
- objectness就是上面所说的框的置信度,用于表征该网格是否有物体;
- class就是类别预测;
- 而bbox就是边界框(bounding box)。
明确了网络的检测基本原理后,接下来就应该考虑如何使得网络学习到这一能力,换言之,或者说,为了训练这个YOLO-v1,到底应该如何去设计groundtruth呢?
继续用那个“网格纸”的比喻,来彻底讲清楚YOLOv1是如何被训练出来的。
🧠 核心思想回顾:网络的输出是什么?
首先,我们再次明确,YOLOv1网络的最终输出是一个 7 x 7 x 30 的张量。 这代表它将图片分成了 7x7=49个格子,每个格子负责预测一些信息,这些信息被包装在一个有 30个数字 的“数据包”里。
这个“数据包”里具体装了三种东西(对应你提到的三部分输出):
- Objectness (置信度):
2个数字。表示这个格子预测的两个边界框中,各自含有物体的可信度是多少(0到1之间)。 - Bbox (边界框):
8个数字(2个框 * 4个坐标 = 8)。每个框需要4个数字来描述其位置和大小:中心点坐标(x, y) 和 宽高(w, h)。 - Class (类别概率):
20个数字。表示这个格子里的物体属于各个类别的概率(比如第1个数字代表“人”的概率,第2个代表“车”的概率...)。
所以,2 (Objectness) + 8 (Bbox) + 20 (Class) = 30。完美!
🎯 如何训练?关键在于“制造标准答案”
训练一个网络,就是让它学会输出正确的“30个数字的数据包”。怎么学呢?我们需要给它提供成千上万张图片,并且每一张图片都要配好一个“标准答案”。这个“标准答案”就是 Ground Truth(真实值)。
Ground Truth 就是一个和网络输出尺寸一模一样的张量:7 x 7 x 30。 我们的任务就是根据图片中物体的真实位置和类别,人工制造出这个“标准答案”张量。
制作Ground Truth的步骤(超级重要!):
我们假设训练图片里有一只狗和一辆自行车,就像你第二张图那样。
第1步:划分网格 & 确定责任格
- 将图片划分为7x7的网格。
- 找出每个物体的中心点落在哪个格子里。
- 比如,狗的中心点落在了第(3, 4)个格子里(第3行第4列)。
- 自行车的中心点落在了第(5, 2)个格子里。
- 核心规则:一个格子最多只负责预测一个物体! 只有包含了物体中心点的那个格子,才需要产生积极的预测。其他格子产生的框,理想情况下置信度都应该为0。
第2步:填充“标准答案”张量现在,我们开始填写那个巨大的、空的 7x7x30 的“标准答案”表格。
- 对于 (3,4) 号格子(有狗):
- 这是一个20分类的问题。狗在PASCAL VOC数据集里对应第几个类别,我们就在那个位置填上
1,其他所有类别位置都填上0。 - 例如,如果“狗”是第5类,那么这个格子的类别部分就是
[0, 0, 0, 0, 1, 0, 0, ..., 0](共20位)。
- 我们将狗的真实边界框(由人工标注好的)换算成YOLO需要的格式(中心点相对于该格子的偏移量,宽高相对于整个图片的比例),然后把这个值同时作为两个预测框的学习目标。
- 这个格子预测了两个边界框(B=2)。但只有一个框是“负责”的。
- 我们事先不知道哪个框形状会更好,所以在Ground Truth里,我们让这两个框都去学习拟合同一个真正的狗框。
- 但是,最终计算置信度误差时,只让与真实框重合度更高(IoU更大)的那个框的“置信度”目标为1,另一个框的置信度目标为0。这样网络就会学会:“哦,我这个格子里的两个框,要有一个非常自信地报告这里有物体,另一个就当备胎好了。”
- Objectness (置信度):
- Bbox (边界框):
- Class (类别):
- 这是一个20分类的问题。狗在PASCAL VOC数据集里对应第几个类别,我们就在那个位置填上
- 对于 (5,2) 号格子(有自行车):
- 重复上述过程,但把“狗”换成“自行车”。
- 对于其他所有格子(没有物体中心点):
- Objectness (置信度):两个框的置信度学习目标都是0。
- Bbox (边界框):不计算损失。因为让网络去学习“没有框”应该长什么样是没有意义的,我们只关心它能不能把“有框”预测对。
- Class (类别):不计算损失。同样,我们不强迫网络去学习“这里没有东西”时该输出什么类别。
⚖️ 网络的学习过程:不断比较和修正
训练开始后:
- 网络收到一张图片,输出一个
7x7x30的“预测值”。 - 我们将这个“预测值”和我们手工制作好的“标准答案(Ground Truth)”进行对比,计算差距(损失Loss)。
- 根据差距,通过反向传播算法来调整网络内部的所有参数(比如卷积核的权重),让网络下一次的预测能更接近“标准答案”。
- 重复几百万次这个过程,网络就学会了如何从图片中提取特征,并最终在正确的格子上,输出正确的30个数字。
💎 总结
总结一下,训练YOLOv1时设计Ground Truth的核心思想:
- 网格负责制:图片被分成SxS网格,只有包含物体中心点的网格才需要做出积极预测。
- GT的构造:Ground Truth是一个
S x S x (5B+C)的张量。 - 有物体网格:
- 置信度:让与真实框最匹配的那个预测框的置信度目标为
1,另一个为0。 - 边界框:所有预测框都去学习拟合同一个真实框的位置。
- 类别:采用one-hot编码,物体真实类别位置为
1,其余为0。
- 置信度:让与真实框最匹配的那个预测框的置信度目标为
- 无物体网格:
- 核心目标是让它们的置信度尽可能接近0,这是优化的大头。
这个过程巧妙地将复杂的物体检测问题,转化为了每个格子上的回归(预测框坐标) 和分类(预测类别) 问题,这就是YOLO系列算法强大且高效的根源。
当然这只是个概念,我们还得深入一下,毕竟要实操。
三、YOLOv1的正样本制作方法
我们已经知道,YOLOv1最后输出一个 7 x 7 的网格,每个网格会给出30个参数,包括两个bbox的5个参数(框的置信度+框的坐标参数)和20个类别置信度。首先,先说一下每个bbox的5个参数的含义。
由于YOLOv1是去预测物体的中心点,并给出矩形框,因此,包含中心点的网格,我们认为这里是有物体的,即这一网格的objectness的概率为1: ,如下图所示:

黄颜色代表这个网格有物体, 也就意味着,物体的中心点落在了这个网格中,那么,这个网格就会被标记为一个“正样本候选区域”,即这个标签的正样本只会来源于这个网格。
在这里暂停一下,根据一些读着的反馈,大家都会问测试阶段怎么知道Pr(objectness)是0还是1。这里需要做个解释:
论文中所说的Pr(objectness)=1,以现在的技术角度来看,就是指“正样本候选区域”。
首先要清楚一点,YOLO一共有三个预测:objectness、class、bbox。
- 其中,objectness是一个二分类,即有物体还是无物体,也就是“边界框的置信度”,对应loss函数中的那个“C”,没物体的标签显然就是0,而有物体的标签可以直接给1,也可以计算当前预测的bbox与gt之间的IoU作为有物体的标签,这一点也是YOLOv1所采取的策略,也是后来的所谓的“IoU-aware”技术;
- class就是类别预测,只有正样本候选区域中的预测框才有可能会被训练,也就是Pr(objectness)=1的地方,注意,这个Pr(objectness)=1就是指正样本候选区域,和IoU没关,和YOLO没关,只和label有关,因为gt box的中心点落在哪个grid,哪个grid就是正样本候选区域,也就是Pr(objectness)=1。
- 正样本候选区域的作用就是告知我们:该标签的正样本只会来源于此。
继续白话
简单来说,可以把 YOLOv1 的工作方式想象成:让一张网格纸去“看图说话”。下面我们一步步拆解这个过程。
🧠 一、核心思想:网格纸游戏
YOLOv1 会将一张输入图片划分成 7×7 的网格(就像一张网格纸)。每个小格子(Grid Cell)都是一个“小侦探”,它的任务是汇报三件事情:
- Objectness(有没有东西?):我这个格子里有没有一个物体的中心点?
- Class(是什么东西?):如果有个东西,那它最可能是20类物体中的哪一类(比如狗、车、人)?
- Bbox(东西在哪,多大?):如果有个东西,那我预测的框应该画在哪才能把它框准?
每个“小侦探”(网格)都会输出一个包含30个数字的报告,这30个数字就封装了以上三方面的信息。
🎯 二、谁是“天选之子”?——正样本候选区域
这是你最关心的核心。“正样本候选区域”是一个非常“霸道”的规则,它完全由人工标注的真实框(Ground Truth, GT) 决定:
- 规则:只要某个物体的中心点落在了某个格子里,那么这个格子就被标记为“正样本候选区域”。
- 标志:对于这个格子来说,
Pr(Objectness) = 1。这不是一个预测值,而是一个铁律,是训练时我们告诉网络的:“嘿,这个格子必须有点东西,你给我好好学!” - 责任:被选中的“正样本”格子责任重大,它需要努力地去预测出正确的类别(Class)和准确的边界框(Bbox)。
非常重要的一点:Pr(Objectness)=1 这个标签和网络预测得准不准、框的IoU高不高,在此时完全没有关系。它仅仅是一个“责任分配”的开关,告诉你哪个格子需要被重点关照。

⚖️ 三、Objectness 的“双重人格”
这是最容易混淆的地方。Objectness 在训练和推理时,扮演的角色完全不同。
- 训练阶段(老师教学生)
在训练时,我们有标准答案(GT框)。对于“正样本候选区域”(Pr(Objectness)=1 的格子):
- 网络会预测出2个边界框(Bbox)。
- 老师会计算这两个预测框和真实框的IoU(交并比)。
- 与真实框IoU更大的那个预测框,会被选中作为“负责”的框。
- 接着,老师不会简单地把这个框的Objectness标签设为1,而是设为其预测框与真实框的IoU值(比如0.9、0.8)。这就是所谓的 “IoU-aware”技术。
- 这样做的妙处:让网络预测的置信度不仅能反映“有没有物体”,还能自我评价框的质量好坏。预测得越准,置信度就应该越高。
简单说:训练时,正样本的Objectness标签 = 预测框与真实框的IoU值。
- 推理阶段(学生自己考试)
在检测新图片时,没有标准答案了。
- 网络会直接输出一个0到1之间的值,作为
Objectness的预测值。 - 这个值同时蕴含了“有无物体”和“框的质量”两层信息(因为在训练时它就被如此教导)。
- 我们会用这个预测值去判断一个框是否可靠。
📦 四、三者如何协同工作?
最后,我们来看看在推理时,YOLOv1 如何给出一个最终的、带置信度的检测结果:
最终置信度分数 = Objectness预测值 × 最大类别概率
举个例子:
- 某个格子预测:
Objectness = 0.9(很有把握这里有个东西且框得准) - 它的类别概率分别是:
[狗: 0.8, 猫: 0.1, 车: 0.1] - 那么这个边界框的最终得分就是:
0.9 × 0.8 = 0.72 - 这个0.72就代表模型综合判断“这里有一只狗”的总体置信度。
💎 总结与类比
做一个最终的总结对比:
| 预测输出 | 通俗解释 | 与“正样本”的关系 | 在训练和推理中的角色 |
|---|---|---|---|
| Objectness (置信度) | “框的质量报告” | 正样本的标签是1,但学习目标是IoU值。 | 训练:学习目标(标签是IoU)。 推理:预测结果(用于筛选框)。 |
| Class (类别) | “物品识别报告” | 只有正样本才需要学习和预测类别。 | 训练:学习目标(标签是one-hot)。 推理:预测结果(是什么东西)。 |
| Bbox (边界框) | “画框方案” | 正样本中IoU最大的那个框负责学习画框。 | 训练:学习目标(标签是框坐标)。 推理:预测结果(框的位置)。 |
在推理(inference)阶段,YOLO一共输出三个预测,是否有物体的objectness预测、class预测和bbox预测。
首先,我们根据预测的计算score=objectness * class 作为每个边界框的得分score,这个score也就是边界框的置信度confidence,论文中给出的计算公式如下:
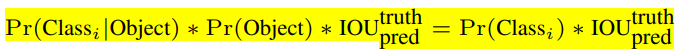
先来说说这个公式:如何综合评价一个预测框的好坏
🧠 公式的直观理解
这个公式的目的是计算YOLOv1输出的每个边界框(Bounding Box)的最终置信度分数(Final Confidence Score)。这个分数同时衡量了 “是什么” 和 “框得有多准” 两个方面。
我们可以把它拆解成三部分来理解:
Pr(Object):这是“物体存在概率”。它只回答一个简单的问题:这个框里有没有物体? 它是一个0到1之间的值,值越高,表示网络越确信这里有个东西。IOU_pred^truth:这是“定位精度”。它计算的是预测的框和真实的框之间的交并比(IoU)。IoU越高,说明你预测的框和真实位置重合得越好,框得越准。它的值也在0到1之间。Pr(Class_i | Object):这是“条件类别概率”。它的意思是:在已经确定这里有物体的前提下,这个物体是第i类(比如“狗”或“自行车”)的概率是多少?
公式的妙处在于:它将这三者相乘。一个完美的预测框应该同时满足:
- 确信有物体 (
Pr(Object) ≈ 1) - 框得非常准 (
IOU_pred^truth ≈ 1) - 类别判断准确 (
Pr(Class_i | Object) ≈ 1)
三者相乘,最终得分就接近 1。反之,任何一项得分低,都会导致最终得分很低。这非常符合我们的直觉。
⚖️ 训练 vs. 推理:公式的不同角色
- 训练阶段(有参考答案)
在训练时,我们有标注好的真实框(Ground Truth),所以我们可以计算出 IOU_pred^truth。
- 对于正样本(包含物体中心的格子):
Pr(Object)的标签被固定为1。IOU_pred^truth是计算出来的(预测框和真实框的IoU)。- 因此,
Pr(Object) * IOU_pred^truth整体作为一个明确的学习目标,告诉网络:“你预测的这个框,置信度应该向这个IoU值看齐。” - 这迫使网络学习到:置信度不仅要反映“有没有物体”,还要反映“框的质量好不好”。这就是所谓的“IoU-aware”。
- 对于负样本(不包含物体的格子):
- 学习目标直接是
0。
- 学习目标直接是
- 推理阶段(没有参考答案)
在推理时,没有真实框给我们计算 IOU_pred^truth。
- 此时,公式左边的
Pr(Object) * IOU_pred^truth这个整体,不再是一个计算目标,而是网络直接预测出的一个值——即Objectness分支的输出值。 - 网络在训练阶段已经学会了如何预测一个既能代表“有无物体”又能代表“框的质量”的综合置信度。
- 所以我们直接使用网络预测的
Pr(Object) * IOU_pred^truth值,再乘上类别概率Pr(Class_i | Object),就得到了最终的置信度分数,用于筛选和排序预测框。
💎 总结
| 训练阶段 (Training) | 推理阶段 (Inference) | |
|---|---|---|
IOU_pred^truth | 一个已知的计算值(根据预测框和真实框算出),用作训练目标。 | 一个未知的量,但其作用已融入网络的预测能力中。 |
Pr(Object) * IOU_pred^truth | 一个标签(目标值),用于指导网络学习。 | 一个预测值,由网络直接输出,作为边界框的置信度。 |
| 公式的作用 | 定义损失函数,让网络学会预测出同时包含物体存在性和框质量的综合置信度。 | 计算最终得分,用于评估预测框的综合质量并进行筛选。 |
简单来说,这个公式在训练时是“老师”,用来教导网络;在推理时是“学生”,是网络输出的答案。它完美地将分类准确度(是什么)和定位精度(框得准不准)统一到了一个综合的评分里。
- 核心问题:推理阶段如何得到 IoU?
图片首先指出,公式中的 IOU_pred^truth 符号最容易引起歧义,因为在推理(测试)时,没有真实框(ground truth),无法计算这个值。
- 训练阶段:置信度是“学习目标”
在训练阶段,网络有真实标签作为参考答案,置信度的作用是作为模型的学习目标。
- 学习标签的构成:完整的置信度标签 =
Pr(objectness) * IOU_pred^truth - 正样本(有物体):
Pr(objectness) = 1- 标签值即为预测框与真实框的
IOU_pred^truth(交并比)。
- 负样本(无物体):
Pr(objectness) = 0- 标签值直接为
0。
小结:通过这种方式,YOLOv1在训练时让模型学会预测的置信度不仅能反映“有无物体”,还能反映“框得准不准”(即IoU的高低)。
- 推理阶段:置信度是“预测结果”
在推理阶段,没有真实框来计算 IoU。此时,网络运用了训练好的能力。
- 预测值的意义:训练好的模型,其
objectness分支的直接输出值,就等价于Pr(objectness) * IOU_pred^truth这个整体。 - 置信度的双重作用:这个预测出的置信度值同时代表两层含义:
- 有无物体:进行前景/背景的二分类判断。
- 定位质量:定量评价这个预测框本身的质量好坏。
- 理想情况:一个完美的预测框,其置信度应为
1。这表示它肯定包含一个物体(Pr(objectness)=1),并且框的位置极其精准(IOU_pred^truth=1)。
- 推理流程:从置信度到最终得分
推理阶段的实际操作流程和最终计算公式:
- 过滤背景:设定一个阈值(如0.5)。将置信度低于此阈值的预测框过滤掉,视为背景。
- 计算最终得分:对于保留下来的预测框(前景),其最终得分(
score)由 置信度 与 类别概率 相乘得到。- 最终公式:
score = Pr(objectness) × Pr(Class_i) - 公式解读:这个得分综合反映了“这里有一个物体”(置信度高)且“这个物体是某类别”(类别概率高)的联合概率。
- 最终公式:
总结
核心思想是阐明了 IOU_pred^truth 在 YOLOv1 中的角色转变:
- 训练时:它是一个计算出来的、用于指导学习的标签值。
- 推理时:它的物理意义已经融合进网络所预测的置信度值之中,不再需要单独计算。
这种设计使得模型在预测时,仅通过一个置信度值就能同时表达“存在性”和“精确性”,非常巧妙。
好滴!我们继续看图!

注意看上面的图,我们会发现这个中心点相对于它所在的网格的四边是有偏距的,这其实就是由于降采样带来的量化误差,因此,我们只要获得了这个量化误差,就能获得中心点的准确坐标了,那么YOLOv1中是怎么计算这个量化误差的呢?
或者说YOLOv1如何确定目标位置的核心原理——即如何将图片上的一个真实框,转换成网络需要学习的目标,以及网络预测出的值又如何变回最终的框。
🧭 一、核心思想:从“地图网格”到“精确定位”
YOLOv1 目标检测的核心创新在于,它不再盲目地搜索图片,而是采用了一种“网格化定位”的策略。你可以将其理解为:
- 绘制地图:将一张图片划分为
S x S(例如7 x 7)的网格,就像一张城市地图被划分成不同的街区。 - 分配任务:每个网格(“街区”)负责预测中心点落在自己区域内的物体。
- 精准导航:对于有物体的网格,网络不仅要知道“这里有东西”,还要预测一个精细的偏移量,来精确定位物体中心点在这个“街区”内的确切位置。
“如何根据真实物体的坐标,为网络生成学习目标” 以及 “如何从网络的预测值,反推出物体的真实坐标” 的完整过程。
📐 二、第一步:确定“目标街区”(正样本候选区域)
首先,我们有一个已知的真实边界框(Bounding Box),用它的左上角和右下角坐标 (x_min, y_min, x_max, y_max) 表示。
- 计算宽高:这个框的宽度
w和高度h很容易计算:w = x_max - x_minh = y_max - y_min
- 计算中心点:计算出这个框的中心点坐标,也就是目标物体的中心位置:
center_x = (x_min + x_max) / 2center_y = (y_min + y_max) / 2
- 映射到网格(找到“目标街区”):
grid_x = floor(center_x / stride)(floor是向下取整)grid_y = floor(center_y / stride)
- 由于网络最终的输出是
7x7的特征图,我们需要将原始图片坐标映射到这个低分辨率的网格上。这个映射的比例尺就是stride(步长),在这里是64(448 / 7 = 64)。 - 计算中心点落在哪个网格:
(grid_x, grid_y)这个网格位置,就是“正样本候选区域”。网络训练时,只有这个格子需要学习如何预测这个物体。
🎯 三、第二步:计算“门牌号”(量化误差与学习目标)
仅仅知道物体在哪个“街区”(grid_x, grid_y)是不够的,我们需要知道它在这个街区内部的精确位置。
- 计算量化误差:
c_x = (center_x / stride) - floor(center_x / stride)c_y = (center_y / stride) - floor(center_y / stride)
- 当我们用
floor(center_x / stride)计算时,我们得到了整数部分(例如2),但丢弃了小数部分(例如0.3)。这个被丢弃的小数部分,就是“量化误差”。 - 这个误差代表了物体中心点相对于所在网格左上角的偏移比例。
- 计算公式:
- 确定学习目标:
c_x和c_y就是YOLOv1网络关于中心点坐标要学习的目标!- 它们的值永远在
[0, 1)范围内。这使得网络的学习任务变得非常简单和稳定——不再是预测几百像素的绝对坐标,而是预测一个0到1之间的小数(偏移量)。
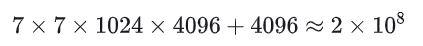
🔄 四、第三步:从预测值“反推”真实坐标(解码)
网络在推理时,会在 (grid_x, grid_y) 位置预测出 c_x, c_y,以及物体的宽 w 和高 h。我们需要一个逆过程将这些值变回原始图片上的坐标。
- 反解中心点坐标:
center_x = (grid_x + c_x) * stridecenter_y = (grid_y + c_y) * stride
- 公式非常简单直观:
- 通俗解释:
grid_x * stride可以算出这个网格左上角在原始图片上的绝对坐标。再加上预测的偏移量c_x * stride,就精准地还原出了中心点的绝对坐标。
- 处理宽高(w, h)—— 归一化:
w = w / w_imageh = h / h_image
- 网络直接预测边界框的宽和高。但宽高(可能上百像素)和中心点偏移(0~1)的数值尺度差异巨大,直接一起训练会导致网络不稳定(Loss不平衡)。
- 解决方案:归一化。将宽和高分别除以图片的总宽度和总高度,也压缩到0~1附近:
- 这样,网络预测的
w,h目标值也和c_x,c_y的尺度一致,训练就稳定了。预测时,再用w * w_image和h * h_image还原回真实的宽高。
🏆 五、总结与意义
YOLOv1的两个伟大之处:
- 它将复杂的检测问题分解:把“找物体”这个难题,分解为 “网格定位” (
grid_x, grid_y) + “精细偏移” (c_x, c_y) + “大小预测” (w, h) 三个更简单的子问题,极大降低了学习难度。 - 它是Anchor-Free的开创者:这种让每个网格直接预测相对于自身位置的偏移量的思路,无需预先设置大量不同形状的“锚框”(Anchor),设计非常简洁、优雅,成为了后来众多Anchor-Free检测算法的思想源泉。
简单回顾其工作流程:
- 训练时:根据真实框,计算出
c_x,c_y(偏移目标)和归一化的w,h(宽高目标),让网络去学习。 - 推理时:网络在
(grid_x, grid_y)位置预测出c_x,c_y, w, h,我们再通过解码和反归一化公式,将它们还原成图片上最终的边界框。
再来看原文,讲的挺清晰这部分

瞧瞧,是不是觉得有的时候科研就是在开“历史倒车”呢?不过,从螺旋发展的角度来看,这并不奇怪,毕竟那时候连anchor box都没有呢,说YOLOv1是anchor-free模型反而有点本末倒置了。
那我们了解一下理解目标检测中的 Anchor-based(基于锚框)和 Anchor-free(无锚框)。
🧱 核心概念速览
| 特性维度 | Anchor-Based (基于锚框) | Anchor-Free (无锚框) |
|---|---|---|
| 核心思想 | 预先铺设大量不同形状的“锚框”作为候选,网络学习调整这些框。 | 直接预测目标的关键点(如中心、角点)或边界框,无需预定义锚框。 |
| 工作原理 | 1. 生成锚框 2. 计算锚框与真实框的IoU来确定正负样本 3. 回归锚框的偏移量进行调整 4. 分类 | 1. 定位关键点(如中心点或角点) 2. 直接回归边界框的尺寸或偏移量 |
| 典型代表 | Faster R-CNN (两阶段) YOLOv2-v5 (单阶段) RetinaNet | YOLOv1 CornerNet (关键点) FCOS, CenterNet (中心点) |
| 主要优点 | 召回率较高,收敛速度较快,技术相对成熟。 | 模型设计更简洁,减少超参数和计算量,泛化能力更强。 |
| 主要缺点 | 超参数多(尺寸、比例、数量需精心设计),计算冗余,泛化能力较弱。 | 小目标检测、密集物体和重叠场景下的精确定位能力可能面临挑战。 |
🔍 深入理解两种方法
🧩 Anchor-Based (基于锚框) 这种方法你可以想象成:在一张图片上,系统会预先铺上成千上万个不同大小、不同长宽比的“锚框”(Anchor Boxes)或“先验框”。这些锚框是预先定义好的候选检测框。网络的任务不是直接凭空生成框,而是学习如何微调这些预定义的锚框,使其完美地贴合真实物体。
- 工作流程:
- 生成锚框:在特征图的每个位置上,预先生成多个不同尺度和宽高比的锚框。
- 匹配正负样本:计算每个锚框与真实标注框的交并比(IoU)。IoU高的锚框被标记为正样本(包含物体),IoU很低的则标记为负样本(背景)。
- 边界框回归:网络学习预测正样本锚框需要进行的精细调整(微调偏移量),使其更准确地匹配真实物体。
- 分类:同时,网络判断每个调整后的锚框内物体的类别。
- 优缺点:
- 优点:锚框提供了良好的初始猜测,有助于网络更快收敛,并且在传统应用上非常成熟。
- 缺点:锚框的尺寸、比例和数量都需要人工预先设定或通过聚类确定,这依赖于经验和数据,缺乏灵活性且会引入大量超参数。同时,会产生大量无效的锚框,导致计算冗余和正负样本不平衡问题。
🎯 Anchor-Free (无锚框) 无锚框方法试图摆脱对预定义锚框的依赖,追求更简洁、更直接的检测方式。它的核心思想是:直接预测物体本身的关键属性,而不是去调整一堆预定义的框。
无锚框方法主要分为两大流派:
- 基于关键点(Keypoint-based):例如 CornerNet,通过检测物体的左上角和右下角两个关键点,然后将它们配对组合成边界框。
- 基于中心(Center-based):例如 FCOS 和 CenterNet,它们将目标的中心点或中心区域定义为正样本,然后直接预测该点到物体边界框的四条边的距离(上、下、左、右),或者直接预测物体的宽和高。
- 工作流程(以FCOS为例):
- 将图像输入网络,输出特征图上每个点都负责预测。
- 如果一个点的位置落在真实框内,它就被视为正样本,需要预测物体类别。
- 对于正样本点,网络直接回归四个值:到边界框左、右、上、下的距离。
- 引入 “中心度”(Centerness) 概念,预测点距离物体中心的程度,用于抑制低质量预测框。
- 优缺点:
- 优点:模型设计更简单,避免了与锚框相关的所有超参数和复杂计算。泛化能力更强,更容易迁移到不同数据集或任务上。
- 缺点:在极端场景下可能面临挑战,例如非常小的物体、严重重叠的物体,其密集预测的特性可能使得正负样本分配和精确定位变得困难。
🤔 如何选择与发展趋势
- 如何选择:这通常取决于你的具体任务、数据集和资源限制。Anchor-based 方法在传统应用和高召回率场景中可能更稳定。而 Anchor-free 方法在追求模型简洁性、推理速度和泛化能力时更有优势。
- 发展趋势:近年来,Anchor-free 方法因其简洁性和不断增长的性能表现而受到广泛关注,成为了目标检测领域的一个重要研究方向。值得注意的是,YOLO 系列的发展也体现了这种演变:YOLOv1 是 Anchor-free 的,YOLOv2 到 v5 转向了 Anchor-based,而最新的 YOLOX 等版本又回归了 Anchor-free 设计,并取得了优异性能,这印证了“螺旋式上升”的技术发展规律。
💎 核心区别与联系
尽管两种方法路径不同,但它们的核心任务是一致的:准确分类图像中的物体并定位其位置。研究表明,当使用相同的正负样本定义策略时,两种方法最终的性能差异会变得很小。这意味着,如何为网络训练选择高质量的正样本和负样本,比“是否使用锚框”更为关键。
不过,这些都不重要,我们继续看点实在的东西。
我们已经确定了bbox的位置参数,接下来,再看框的置信度 C ,或者说是objectness。
它的作用其实就是用来表征此处是否有物体,和RPN 的概念是一样的,因此,学习标签可以用0和1,分别表示有物体额没有物体。但是,YOLO认为框的置信度也应该具备表征对bbox预测的定量评价的能力,因此,尽管对于没有物体处,其学习标签是0,但对于有物体的地方,则采用另一种做法:
具体来说,在训练过程中,在正样本候选区域处(grid_x, grid_y):
- 第1步:YOLOv1网络输出B个预测框;
- 第2步:计算这B个bbox与此处的真实bbox(也就是标签)之间的交并比(Intersection over Union,IoU),得到B个IoU值;
- 第3步:选择IoU值最大的预测框作为正样本,分别去计算置信度损失、类别损失和边界框回归损失,其中置信度损失的标签就是该IoU值。
- 第4步:对于剩下的没被选中的B-1个预测框,它们都被标记为负样本,即只计算置信度损失,且置信度标签都为0,这是显然的。这些负样本不计算类别损失和边界框回归损失。同时,对于那些处在正样本候选区域之外的预测,都标记为该标签的负样本,也只计算置信度损失。
举例来说,假设当前预测的B个矩形框和真实的矩形框的最大IoU = 0.28,对应的预测bbox为Bi,那么网络就会将这个0.28作为置信度C的学习目标,同时只有Bi,会去计算regression部分的loss,然后反向传播,其他的bbox就都被忽略了。
可见,倘若bbox都学得不好,那么算出的IoU也就都不高,网络预测的置信度学出来的也就偏低。但换个角度来看,这个置信度直接就能衡量定位的好坏。
让网络学习IoU,即所谓的IoU-Aware,这一思想还是在后来的ECCV的IoU-Net提出的呢~
另外,关于YOLOv1中只让IoU最高的那个bbox去回归,其他都忽略掉这一点,笔者认为是多余的,因为B个bbox是完全平权的,没有差异性,没有约束性,倒不如就令B=1,简单省事。
我们不断重复这几个步骤,直到给所有的标签都匹配上了一个正样本为止。不过,这里会有一个潜在的问题,要是两个物体的中心点都在同一个网格,且都匹配到了同一个预测框,那么这个预测框该学哪个标签?这个问题是YOLOv1无法回答的,是YOLOv1的一个缺陷。
继续白话
这说的就是YOLOv1是如何在训练时,从多个预测框中选出“最佳员工”并给它“发奖金”(计算损失)的。
🏭 核心比喻:工厂质检流程
想象一下,YOLOv1的网络就是一个质检工厂。它的任务是:在一张图片上的每个指定区域(网格),检查里面有没有瑕疵(物体),如果有,就画个框标出来,并说明是什么瑕疵。
- 网格(Grid Cell):工厂的一个个质检工位。
- 预测框(Bounding Box):每个工位派出的质检员,负责观察和报告瑕疵范围。YOLOv1中,每个工位有 B=2 个质检员。
- 真实框(Ground Truth):已知瑕疵范围的标准答案。
- IoU(交并比):质检员画的框和标准答案框的重叠程度。IoU越高,说明质检员画得越准。
🔧 四步质检流程(对应你的四个步骤)
- ✅ 第一步:派出质检员
工厂在每个工位(网格)派出 B 个质检员(生成 B 个预测框),每个质检员都根据自己的经验画一个框,猜测瑕疵的范围。
- ✅ 第二步:对比标准答案
工厂手里有标准答案(真实框)。现在,计算每个质检员画的预测框和标准答案框的重叠程度(IoU)。
- IoU = 交集面积 / 并集面积
- 值在 0 到 1 之间。1表示完全重合,0表示完全没有重叠。
- ✅ 第三步:奖励最佳员工(计算正样本损失)
工厂比较这 B 个质检员(预测框)的IoU成绩。
- 成绩最高的那个质检员,被评选为 “正样本”。它将获得丰厚的奖励和全面的培训。
- 奖励和培训(计算损失):工厂会从三个方面来指导这位最佳质检员:
- 置信度(Confidence):工厂告诉他:“你的框和答案有XX%的重合度(IoU值),所以你对自己这次判定的自信程度就应该是这个分数!” 这就是为什么置信度的学习目标直接就是IoU值。
- 类别(Class):工厂告诉他:“你框里的这个东西,它的正确类别是XXX。”
- 框的位置(Bbox):工厂会微调他画的框,告诉他:“框的中心应该再往右一点,框应该再宽一点。”
- ❌ 第四步:批评其他员工(计算负样本损失)
- 同一个工位里没被选上的 B-1 个质检员,以及其他所有工位上根本没看到瑕疵的质检员,只会受到一点批评:工厂告诉他们:“你们这里根本没有东西,你们的置信度应该是0!”
- 他们不参与学习画框和分类,只学习“承认自己看错了”(只计算置信度损失,且标签为0)。
- 🧩 举例说明
假设一个工位的两个质检员(预测框B1和B2)和标准答案的IoU分别是 0.28 和 0.12。
- B1(IoU=0.28) 成为正样本。它的学习目标是:
- 置信度 要学习到 0.28。
- 位置和类别 要向真实框看齐。
- B2(IoU=0.12) 成为负样本。它只需要学习一件事:将自己的置信度降为 0。
“倘若bbox都学得不好,那么算出的IoU也就都不高,网络预测的置信度学出来的也就偏低。”
- 这就好比一群质检员业务水平都不行,画的框和标准答案差距很大,因此他们自己也心虚,不敢说自己看对了(预测的置信度低)。
“但换个角度来看,这个置信度直接就能衡量定位的好坏。”
- 这正是YOLOv1设计的高明之处!网络输出的置信度不是一个简单的“有/无”判断,而是一个同时包含了“有无物体”和“框得准不准”的综合评分。 一个完美的预测,应该是高置信度 + 类别正确 + 框的位置准。
- ⚠️ 作者观点与模型缺陷
作者认为“令B=1,简单省事”
- 在YOLOv1中,同一个工位的两个质检员(两个预测框)在初始化时是完全一样的(平权),没有分工。它们纯粹是靠“运气”和训练数据来分化,看谁能更快地学会拟合各种形状。
- 作者觉得,既然这样,不如就只设置 B=1,让一个框专心致志地去学习,模型更简单,参数更少。后来的YOLO版本(如v2)引入了“锚框”(Anchor Boxes),就是让不同形状的预测框有明确的初始分工,解决了这个问题。
YOLOv1的缺陷:一个工位只能处理一个瑕疵
- 如果两个瑕疵(物体)的中心点恰好都落在同一个工位(网格) 里,那么这个工位就会“不知所措”,因为它只能预测一个物体。 这是YOLOv1在设计上的一个固有局限,导致它在检测密集或重叠物体时表现较差。
总结一下,网络的最后输出中,每个正样本候选区域 位置处的每个bbox都包含如下参数:
最后再加上类别:
由这些参数,计算出相应矩形框的位置:
参数说明
| 参数符号 | 参数名称 | 含义与作用 |
|---|---|---|
C_box | 边界框置信度 | 表示该预测框内是否存在物体以及预测的准确程度。其值由 Pr(object) × IoU 计算得到,范围在0到1之间。Pr(object) 是网格内存在物体的概率,IoU 是预测框与真实框的交并比。高的置信度意味着模型不仅认为框内有物体,而且预测框的位置很准。 |
c_x | 中心点x坐标偏移 | 预测的边界框中心点相对于其所在网格左上角的横向偏移量。这是一个归一化值,范围在0到1之间。例如,0.5表示中心点位于网格的水平中央。 |
c_y | 中心点y坐标偏移 | 预测的边界框中心点相对于其所在网格左上角的纵向偏移量。同样是一个0到1之间的归一化值。0.5表示中心点位于网格的垂直中央。 |
w | 宽度比例 | 预测的边界框宽度相对于整个图像宽度的比例。归一化值,范围0~1。例如0.5表示框的宽度是图像宽度的一半。 |
h | 高度比例 | 预测的边界框高度相对于整个图像高度的比例。归一化值,范围0~1。例如0.25表示框的高度是图像高度的四分之一。 |
C_1, C_2, ..., C_20 | 类别概率 | 表示该网格内的物体分别属于20个类别(以PASCAL VOC数据集为例)的概率。这些概率是条件概率,即基于“该网格内存在物体”这一条件。所有类别的概率之和为1。一个网格只预测一组类别概率,并由该网格预测的所有边界框共享。 |
🧠 关键补充说明
- 置信度 (
C_box) 是核心:它巧妙地将“有无物体”和“框得准不准”两个信息合二为一。测试时,我们会将每个框的置信度C_box与其最可能的类别概率max(C_1, C_2, ..., C_20)相乘,得到最终的“类别置信度得分”,用于衡量检测结果的可信度。 - 坐标如何解码:网络输出的
(c_x, c_y, w, h)是相对值,需要转换回图像上的绝对坐标。- 中心点绝对坐标:
center_x = (grid_x + c_x) * stride,center_y = (grid_y + c_y) * stride。其中grid_x,grid_y是网格的索引(如0,1,2...),stride是网格的步长(图像尺寸/网格数,如448/7=64)。 - 宽高绝对值:
width = w * image_width,height = h * image_height。
- 中心点绝对坐标:
- YOLOv1的局限性:由于每个网格只预测一组类别概率,并且只能检测一个物体,这导致它对密集和小目标的检测效果不佳,容易漏检。
明确了学习目标见,制作训练标签也就清楚了。在制作标签时,遵循如下步骤:
- 首先计算,中心点落入的网格位置:
- 对于 位置,我们认为此处有物体,因此 ,此处即为正样本,并计算量化误差与矩形框的宽和高:
- 确定类别标签即可。
最后,我们再说一下损失函数的设计,直接上图:𝟙𝟙𝟙𝟙𝟙
图中的第一行关于 , 的损失计算,原文中用的是x,y。第二行是关于w,h的损失计算。注意,这两行中都用一个 符号,这个符号表示正样本,即只有正样本才会计算bbox的损失和class损失,负样本 都只计算置信度损失,且置信度损失的标签为0(原文公式中没有直接标出这个0)。
这就会带来一个问题:只有正样本才会去学习类别和边界框,而负样本不去学习,那负样本的预测岂不就是“瞎预测”了?
其实,这个问题没关系的,损失函数的第三行和第四行就是解决这个问题的,也就是置信度的作用。
在第三行中, 是预测框与真实框计算的 ,预测的越准, 越趋近于1,那么网络预测的C也就越趋近于1,而没有物体的地方,也就是第四行,其中的 都是0(因为这些地方是不应该有框的,所以直接设为0即可),那么网络在这些地方预测的C也就会趋近于0。
在测试的时候,我们会有优先看置信度,只有置信度高的地方才会被考虑,其他的地方就不会了,它输出怎样的bbox也就都无所谓了。
通常,置信度高的地方都会学习到正确的物体知识,这些地方的类别和边界框预测也都是比较准确的。
因此,框的置信度的本质就是一个有无物体的二分类,其作用就是判断此处是前景还是背景。
另外,很明显,一张图中,有物体的网格数目是小于没有物体的网格数目的,因此,为了平衡他们两个的损失,需要赋予不同的权重,正样本的置信度损失的权重给1,没有物体的,即负样本的损失权重给 。
最后的第五行,就是类别概率的损失计算,同样,我们也只考虑正样本的类别损失,其他地方不管。
从上面的损失,我们发现,都是用MSE来计算的,这是因为YOLO-v1关于框的五个参数和类别都是用的是线性函数(全连接层不加激活函数)来做的预测。至于为什么YOLOv1用线性函数来预测,而不是用softmax,咱也不知道,也许是一种历史问题。
在进行下一步之前,我们得承认YOLOv1的损失函数确实有点复杂,咱们一步步把它拆开看明白。这个函数就像是给模型制定的一个“综合评分标准”,告诉它哪些地方做得好,哪些地方需要改进。
好久没有看过这么多公式了,不着急,慢慢来梳理一下!
为了更直观地理解这个“综合评分标准”,先通过一个表格来看看它的全貌和每个部分的职责:
| 损失部分 | 通俗理解 | 负责对象 | 作用 | 权重系数 (用意) |
|---|---|---|---|---|
| 第一行: | 预测框中心点(x, y)的误差 | 正样本 | 让模型学会更准确地预测物体中心点的位置 | (强调定位准确性的重要性) |
| 第二行: | 预测框宽高(w, h)的误差(经平方根处理) | 正样本 | 让模型学会更准确地预测物体的宽高,并对小目标的误差更敏感 | (强调定位准确性的重要性) |
| 第三行: 𝟙 | 正样本的“置信度”误差 | 正样本 | 让模型对有物体的预测框,输出高的置信度 (目标是其与真实框的IoU值) | 权重为1 (基准权重) |
| 第四行: 𝟙 | 负样本的“置信度”误差 | 负样本 | 让模型对没有物体的预测框,输出低的置信度 (目标为0) | (降低大量负样本的影响,避免“滥杀无辜”) |
| 第五行: 𝟙 | 物体分类的误差 | 正样本 | 让模型正确判断有物体的网格内的物体类别 | 权重为1 (基准权重) |
🧠 逐行详解
📍 第一行 & 第二行:边界框位置损失 (只针对正样本) 这两行负责教模型如何画框。
- 第一行计算的是预测的中心点坐标(x, y) 和真实的中心点坐标之间的差距。模型需要学习将框的中心点对准物体。
- 第二行计算的是预测的宽度和高度(w, h) 与真实的宽高之间的差距。这里对宽高取了平方根,主要是因为如果不处理,大框的宽高误差会远大于小框,模型会因此更关注大物体而忽略小物体。取平方根后,大小框的误差尺度更接近,让模型能平等地学习大小物体的定位。
- 𝟙 是一个指示函数,只有负责预测物体的那个正样本预测框(即与真实框IoU最大的那个)才会计入损失,其他框忽略。
- (通常设为5) 是一个权重系数,放大定位损失的重要性,告诉模型“框得准”非常关键。
✅ 第三行 & 第四行:置信度损失 (正负样本都参与) 这两行负责教模型判断框里有没有物体。
- 第三行针对正样本:目标是让模型为有物体的框输出高置信度。这个置信度的学习目标不是简单的1,而是预测框与真实框的IoU值(交并比)。IoU越高,说明框得越准,置信度就应该越高。这样,置信度不仅包含了“有无物体”的信息,还包含了定位质量的信息。
- 第四行针对负样本:目标是让模型为没有物体的框输出低置信度(接近0)。 (通常设为0.5) 是一个权重系数,削弱负样本损失的影响。因为一张图中大部分网格都是没有物体的,如果不降低权重,负样本会“淹没”正样本的损失,导致模型变得保守。
🎯 第五行:类别损失 (只针对正样本) 这一行负责教模型识别框里的物体是什么。
- 只有在包含物体中心点的网格(𝟙)才会计入类别损失。
- 它的目标是让模型输出的类别概率分布尽可能接近真实类别(例如,真实是“狗”,那么“狗”对应的概率就应该接近1,其他类别接近0)。
❓ 回答你的疑问
“只有正样本学习类别和边界框,负样本不就瞎预测了吗?”不会的,这正是YOLOv1设计的巧妙之处。负样本虽然不学习如何画框和分类,但它学习一个更重要的能力:闭嘴(输出低置信度)。
- 在训练时,负样本的唯一目标就是把置信度降为0。
- 在预测时,模型会输出大量框,但我们只关心那些置信度高的框。
- 一个负样本框,即使它胡乱画了一个框,但只要它的置信度很低(比如0.1),我们在最后做非极大值抑制(NMS) 时就会把它过滤掉,根本不会影响最终检测结果。
- 而一个正样本框,因为它同时学习了如何精准画框、识别类别以及输出高置信度,所以它的高置信度是有意义的,最终会被保留。
“为什么都用均方误差(MSE),而不用Softmax?”这更多是YOLOv1原始论文的设计选择。MSE用于回归坐标和置信度是自然的。对于类别预测,虽然现在看用交叉熵损失更常见,但YOLOv1作者当时选择了MSE。这可能是一种历史局限,后来的YOLO版本也改进了这一点。
💎 总结
YOLOv1的损失函数是一个精心平衡的系统:
- 正样本:全面学习 → 画得准(定位)、认得对(分类)、说得自信(高置信度)。
- 负样本:只学习一件事 → 保持谦虚(低置信度),避免刷存在感。
通过这种设计,模型最终只会那些高置信度的预测框,而这些框通常就是学习效果好的正样本,从而实现了端到端的目标检测。
以上,便是有关于训练YOLO-v1的全部了。
那么,在测试的时候我们应该怎么做呢?
1.计算bbox和类别:
2.计算每个边界框的得分:
在YOLOv1中,边界框的得分score = 该处的框的置信度即objectness与类别的置信度class的乘积:
因为在训练阶段,只有正样本出的class预测才会被学习到,而负样本,也就是背景给出的class预测不会被学习,这就会导致在推理的时候,有物体的地方会有可靠的class预测输出,而没有物体的地方的class预测输出约等于瞎预测,毕竟没有被训练。
但这个时候,由于objectness的作用就是判断是否有物体,因此,对于前景,objectness的值会很接近1,反之很接近0。那么,即使class瞎预测,但objectness只要给出接近0的值,那么这个地方的score也会很低,从而滤除了背景。
YOLO的精髓在于把背景和前景的各个类别的学习给解耦了。
objectness分支就负责学习前景和背景,本质是个二分类,等价于Faster R-CNN中的RPN,而类别学习只学正样本的信息,标签里也没加进去背景标签,这就等于Faster R-CNN的第二阶段。
而像SSD和RetinaNet,都是把背景作为一类标签加到了class里,把背景和前景的各个类别的学习耦合到了一块去,那自然要比YOLO学得麻烦一些。
个人感觉,这才是YOLO为什么对Focal loss不敏感的原因,因为它用objectness分支把背景和前景的各个类别的学习解耦了。
class分支只需要学正样本就好了,不需要像RetinaNet那样,单独的背景要和其他一大堆前景标签一块battle,把置信度拉到自己头上。
Objectness预测分支才是YOLO的灵魂!
如果没有这个分支,那和SSD、RetinaNet也就没差别了。
从实质上来讲,objectness的作用更像是RCNN中的RPN网络,只负责预测有无物体,classification和regression的学习都是在正样本上的,由此,从学习的理念上来看,YOLO的学习方式更接近two-stage,从发展的角度来看也是如此,新事物诞生之初,不可避免地保留一部分旧事物的痕迹,YOLO是孕育自two-stage框架的,其诞生之初不可避免地会带有two-stage的痕迹。
直到SSD,抛弃掉objectness这一二分类的预测分支,将背景也视为一个类别标签,one-stage框架才算是真正意义上的自成一派,摒弃了two-stage的痕迹。
用这个得分去做后续的非极大值抑制处理(NMS)。最后保留下来的结果,就是网络的最终预测输出。
到此,关于YOLOv1,我们就全部讲完了~整体来看,YOLOv1还是非常简单的,无论是groundtruth制作,网络预测,都非常简单,这也是我为什么会把它作为本教程的重点示例来讲解。在下一章,我们将对YOLOv1做一次优化改进,来实现一个简单而更好的目标检测网络。
补充: 最后简单说一下什么是非极大值抑制吧。
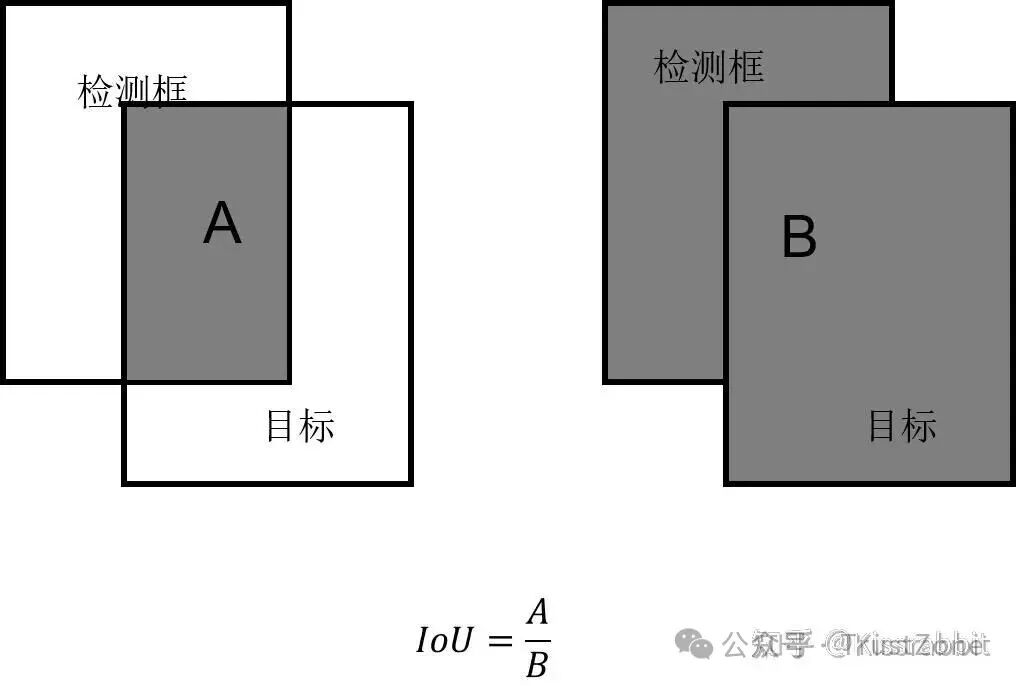
事实上,如果我们把所有的预测结果都可视化出来,会发现有很多冗余,即多个box检测到了同一个物体,而我们对于每一个物体只需要一个框就够了。因此,我们有必要去剔除掉多余的结果。以下面的人间检测为例:
左图中,是未经过处理的,我们可以看到有多个红框检测到了同一张脸,为了提出掉多余的 框,采用如下步骤:
- 1.首先挑选出得分score最高的框;
- 2.依次计算其他框与这个得分最高的框的IoU,超过给定IoU阈值的框舍掉。
- 3.对每一类别都进行以上的操作,直到无框可剔除为止。
微信扫描下方的二维码阅读本文

Comments NOTHING