- 学习教案:https://zhuanlan.zhihu.com/p/364912692
- 作者:Kissrabbit
- 作者书籍:《YOLO目标检测》
在上一节,我们已经学习了经典的YOLOv1的内容,对其论文层面的技术做了详细的介绍,相信读者已经对YOLOv1已经有了足够的感性认识和一定的理性认识,但所谓“纸上得来终觉浅”,为了进一步加深对YOLOv1的认识,我们将从本节开始,展开对YOLOv1的代码实践环节。我们将会使用python语言和pytorch深度学习框架去动手实现一款我们自己的YOLOv1检测器。
然而,YOLOv1工作太过久远了,其诸多技术细节以现在的眼光来看已经太陈旧了,在笔者看来,一板一眼地、循规蹈矩地实现原版的YOLOv1并没有多大的意义。因此,我们在不脱离YOLOv1的大部分核心理念的前提下,重构一款较新的YOLOv1检测器。
为了更好地学习相关的代码,建议读者将项目代码下载下来,相关的github链接如下:
一、搭建YOLOv1
首先,放上一张我们将要搭建的YOLOv1的网络结构图,以便在正式开始代码实践之前,能够对我们所要做的事情有一个整体性的认识,如下图的图1所示。
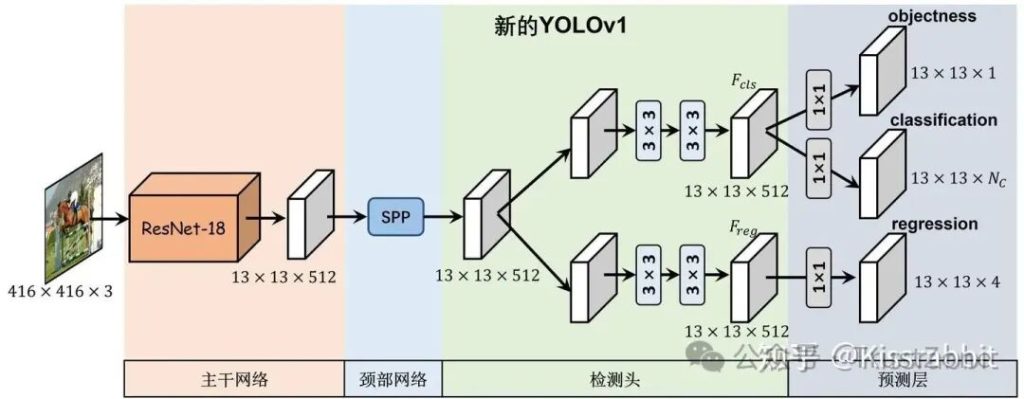
整体来看,我们所要搭建的YOLOv1一共包含三大部分:
- 1)提取输入图像high-level特征的Backbone网络;
- 2)进一步处理图像特征、提升模型感受野的Neck网络;
- 3)提取用于分类的类别特征和用于定位的位置特征的Detection head;
- 4)以及最终的预测层Prediction layer。
当然,这里的3)和4)可以统一称为“检测头”(Detection head),不过,为了更细致的介绍,我们还是将这两点分开来介绍。
接下来,我们展开介绍每一部分的设计。
1.1 Backbone网络
官方的YOLOv1的主干网络是参考了GoogLeNet设计的(没有inception结构),这里我们直接替换成ResNet18。关于ResNet18的网络结构,如下方的图2所示:
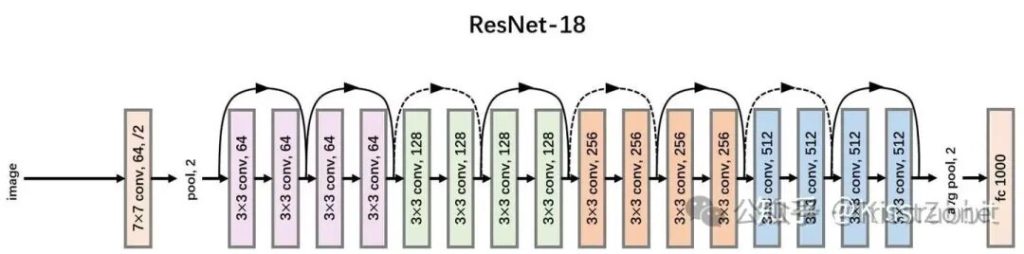
ResNet系列是目前最受欢迎的CNN网络(几乎没有“之一”),该系列工作提出的residual connection几乎成为了当前神经网络设计的准则。
相较于原版YOLOv1所采用的GoogLeNet风格的主干网络,我们所采用的ResNet-18更加轻量、性能更优、速度更快,且网络结构设计更加先进。
就入门而言,使用ResNet-18即可,感兴趣的读者也可尝试使用更大的ResNet网络,如ResNet50、101等。
小白笔记
| 术语 | 通俗解释 |
|---|---|
| CNN | 一种专门处理图像这类网格数据的神经网络,通过“卷积核”在图像上滑动来提取特征。 |
| ResNet | 一个非常著名的深度CNN家族,其核心创新是引入了“残差连接”,解决了深层网络难训练的问题,使得构建成百上千层的网络成为可能。 |
| Residual Connection | ResNet的核心设计,也叫“跳跃连接”。它像一条“捷径”,让输入信号可以直接跳到后面,与经过层层处理后的输出相加。这极大地缓解了梯度消失问题,让超深网络得以训练。 |
| Backbone (主干网络) | 在目标检测等复杂任务中,专门负责提取图像特征的部分。可以理解为网络的“眼睛”,后续的“检测头”等部分再基于这些特征进行分析。 |
| GoogLeNet | 一种在ResNet之前提出的经典深度CNN,其特点是使用了复杂的“Inception”模块来高效利用计算资源。YOLOv1借鉴了它的设计。 |
| ResNet-18 | ResNet家族中的轻量级成员。数字18代表其“深度”(带参数层的数量)。它结构相对简单,参数少,计算快,适合入门或计算资源有限的场景。 |
| ResNet-50/101 | ResNet家族中更深的版本。它们使用了更复杂的“瓶颈结构”来减少计算量,特征提取能力更强,精度更高,但同时也更慢、更占资源。 |
🧠 核心概念详解
- CNN (卷积神经网络):你可以把它想象成一个非常挑剔的“找茬专家”。它手里有很多种不同的“小模板”(卷积核),比如专门找“横线”的、找“竖线”的、找“小圆圈”的。它把这些模板在图片上一个个地方去比对,只要发现某个地方和模板很像,就标记出来。一层层下来,就从最简单的“边缘”、“纹理”找起,最后组合成更复杂的“眼睛”、“轮子”等特征。
- Residual Connection (残差连接/跳跃连接):这是ResNet的灵魂所在。在传统网络里,数据必须一层一层地过,就像爬一个没有休息平台的楼梯,越爬越累(梯度消失),而且可能爬了半天发现还没原来站得高(网络退化)。 残差连接则是在楼梯中间架了很多“滑梯”或“捷径”。如果某一层的学习效果不好,或者梯度传递不过来了,数据可以直接从“滑梯”溜下去,至少能保证信息不会比原来更差。这使得构建非常深的网络(如ResNet-101, ResNet-152)成为可能,并且性能更好。
- Backbone (主干网络):好比一个特征提取流水线。它的任务就是接收一张原始图片,然后通过层层卷积操作,提炼出其中最有用的、不同层级的特征信息(例如,浅层特征可能是边缘、颜色,深层特征可能是物体的部件或整体形状)。这些提炼好的特征会交给后续专门负责“分类”或“检测位置”的模块(称为Head)去使用。很多复杂的视觉系统(如目标检测、图像分割)都会选用一个成熟的CNN(如ResNet、VGG)作为它的Backbone。
- ResNet-18 vs. ResNet-50/101:
- ResNet-18:像一辆灵活的小轿车。它的层数较少(18层),使用基本的残差块(两个3x3卷积)。优点是参数少、训练快、占资源少,非常适合入门学习、快速实验或在手机、嵌入式设备上部署。对于很多不太复杂的任务,它的性能已经足够好了。
- ResNet-50/101:像重型卡车或挖掘机。它们更深(50层/101层),使用了更先进的“瓶颈结构”(Bottleneck,由1x1、3x3、1x1三个卷积组成),虽然参数量和计算量更大,但特征提取能力更强,在大型数据集(如ImageNet)上的精度更高。通常用于对精度要求极高的学术研究或复杂工业场景。
💡 一点额外的理解
原文说ResNet-18比YOLOv1的GoogLeNet风格主干“更轻量、性能更优、速度更快,且网络结构设计更加先进”,这主要是因为:
- 残差连接的设计是神经网络架构的一个重大突破,它解决了深层网络的根本性训练难题,比之前的许多结构(包括GoogLeNet的Inception)都更有效和优雅。
- 因此,即使是一个相对较浅的ResNet(如ResNet-18),凭借其更先进的架构,也能在更少的参数和计算量下,达到甚至超过之前更复杂网络的性能。
1.2 Neck网络
在原版的YOLOv1中,是没有Neck网络的概念的,但随着目标检测领域的发展,相关框架的成熟,一个通用目标检测网络结构可以被划分为Backbone、Neck、Head三大部分。
当前的YOLO工作也符合这一设计。
因此,我们不妨遵循当前主流的设计理念,为我们的YOLOv1添加一个Neck网络。这里,我们选择YOLO系列一直以来都很钟爱的SPP模块,其网络结构如下方的图3所示。
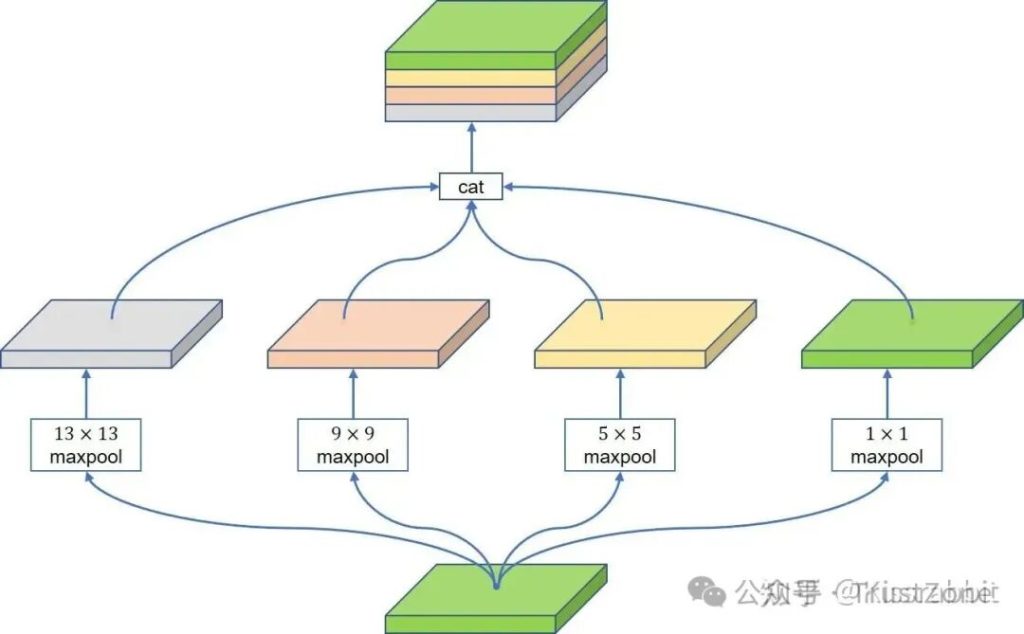
YOLO所采用的SPP模块的设计十分简单,采用了四条并行的Maxpooling分支,pooling kernel的大小分别为1x1、5x5、9x9、13x13,其中的1x1分支本质就是恒等变换。
当四条并行的分支都完成计算后,将四个分支的结果沿通道拼接在一起,最后用一层1x1的卷积做一次映射。
1.3 Detection Head网络
原版的YOLOv1采用了全连接层来完成最终的处理,即将此前卷积输出的二维 H x W 特征图拉平(flatten操作)成一维 HW 向量,然后接全连接层得到4096维的一维向量。https://wxa.wxs.qq.com/tmpl/oc/base_tmpl.html
在此前的YOLOv1论文讲解的章节里,我们也提到了有关这一操作的弊病,因此,我们抛掉这里的flatten操作,改用当下主流的基于卷积的检测头。
具体来说,我们使用普遍用在RetinaNet、FCOS、YOLOX等通用目标检测网络中的“解耦检测头”(Decoupled head),即使用两条并行的分支,分别用于提取类别特征和位置特征,两条分支都由卷积层构成。图4展示了我们所采用的Decoupled head结构。
小白笔记
| 检测头类型 | 代表模型 | 核心思想 | 分类与回归分支关系 | 主要特点与优势 | 潜在局限 |
|---|---|---|---|---|---|
| 耦合头 (Coupled) | Faster R-CNN, 原始 YOLO, RetinaNet (部分共享) | 分类和回归任务共享绝大部分的特征提取层和计算。 | 高度共享,仅在最后预测层分离 | 结构紧凑,参数量较少。 | 任务冲突严重,分类与回归特征相互干扰,难以优化,性能上限较低。 |
| 参数解耦头 (Parametrically Decoupled) | RetinaNet (常见实现) | 分类和回归使用两个独立的卷积序列,但输入的特征完全相同。 | 早期层共享基础特征,后期使用独立参数的分支 | 结构简单直观,一定程度缓解了任务冲突,相比耦合头性能有提升。 | 输入特征未解耦,两个任务仍需从同一特征图中学习不同信息,存在根本性限制。 |
| 上下文解耦头 (Contextually Decoupled) | TSD, TSCODE, YOLO-PRO (ISADH) | 不仅使用独立参数,还通过设计为两个任务提供不同的输入特征上下文。 | 输入特征和参数均解耦 | 性能更优。分类分支融入深层语义特征,回归分支引入浅层细节特征,从根源上缓解空间不对齐问题。 | 结构相对复杂,可能引入额外计算量(但许多设计也致力于轻量化)。 |
🧠 为何需要解耦?
目标检测中的分类和定位任务本质上是不同的:
- 分类任务:关心的是“是什么”,需要丰富的语义信息和上下文来判断物体的类别。它更关注目标内部的显著特征。
- 定位任务:关心的是“在哪里”,需要精确的边界信息(如边缘、角落)来回归出准确的边界框。它更关注目标边界的特征。
在早期的耦合头(Coupled Head) 设计中,这两个任务共享同一个特征提取 backbone,甚至在 head 部分也共享大部分计算。这会导致一种“空间不对齐(Spatial Misalignment)”:即对分类最有利的特征(物体内部)和对定位最有利的特征(物体边缘)在同一位置可能是矛盾的,从而在训练时产生梯度冲突,限制模型性能的上限。
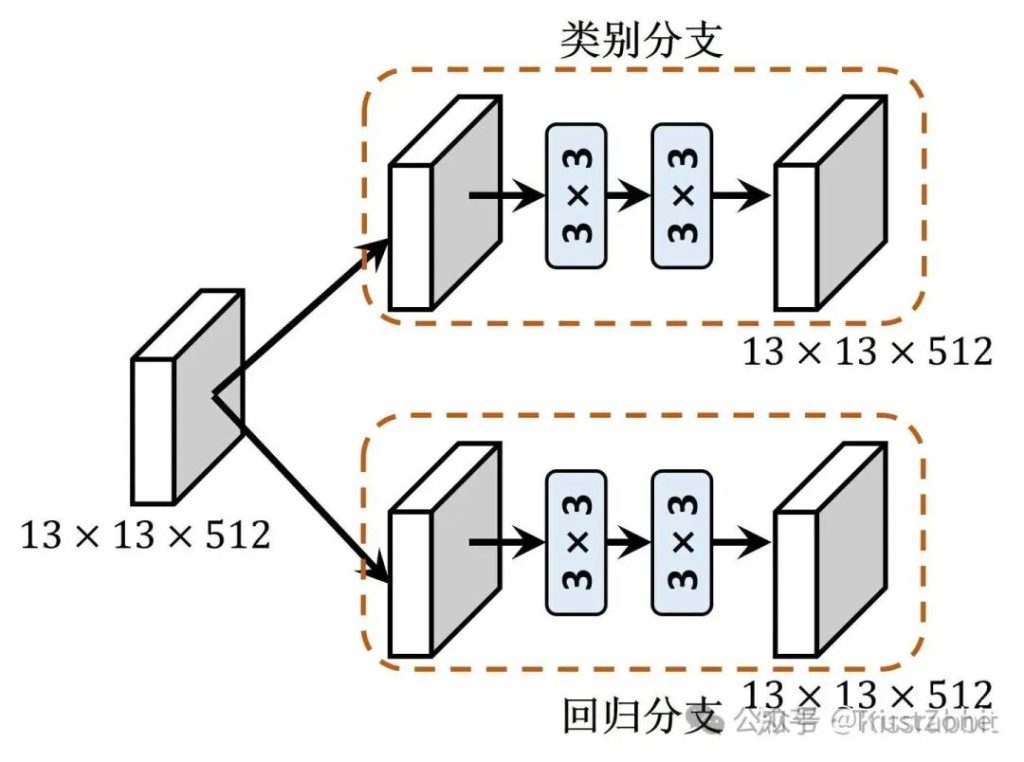
🔧 解耦头如何工作
“两条并行的分支”是解耦头最经典和普遍的形式,其工作流程通常如下:
- 共享基础特征提取:从 Neck(如 FPN)输出的多尺度特征图首先会通过一个或多个共享的卷积层进行初步处理。这一步旨在提取一个通用的基础特征。
- 任务特定分支分离:随后,特征被送入两个完全独立的并行分支中:
- 分类分支(Cls Branch):由一系列卷积层组成,专门负责从特征中学习与物体类别相关的信息。其最终输出是一个维度为
(B, H, W, num_anchors * num_classes)的特征图,通常再接上 Sigmoid 激活函数来输出类别置信度。 - 回归分支(Reg Branch / BBox Branch):同样由一系列卷积层组成(有时结构会与分类分支略有不同),专门负责从特征中学习物体边界框的偏移量。其最终输出是一个维度为
(B, H, W, num_anchors * 4)的特征图(4 对应中心点坐标和宽高的偏移量)。
- 分类分支(Cls Branch):由一系列卷积层组成,专门负责从特征中学习与物体类别相关的信息。其最终输出是一个维度为
🚀 优势与影响
采用解耦头带来了多方面的重要提升:
- 缓解任务冲突:两个分支各司其职,大幅减少了分类和回归任务之间的梯度干扰。
- 提升检测精度(mAP):这是最直接的收益,几乎所有主流检测器在采用解耦头后都观察到了显著的 mAP 提升。
- 加速训练收敛:由于任务冲突减少,优化过程更加平滑,模型收敛速度更快。
- 成为现代检测器标配:正如你所见,从 YOLOX 开始,到后来的 YOLOv6, v7, v8, PP-YOLOE 等,解耦头已经成为高性能目标检测算法的标准配置。
💡 进阶设计
基本的解耦头(仅参数独立)之后,研究者们还提出了更精细的设计,例如图中可能展现的 TSCODE或 YOLO-PRO 中的 ISADH 等方案。这些设计意识到,仅让参数独立是不够的,两个分支的输入特征本身也应当有所侧重。因此,它们通过额外的网络结构:
- 为分类分支注入更多来自深层的、富含语义上下文的特征。
- 为回归分支注入更多来自浅层的、富含细节和边缘信息的高分辨率特征。 这些设计进一步提升了性能,代表了解耦头发展的新方向。
1.4 Prediction layer预测层
由于我们采用了解耦检测头的结构,因此检测头最后部分的“预测层”(Prediction layer)也要做相应的修改。
首先,我们只要求YOLOv1在每一个网格只需要预测一个bbox,而非两个甚至更多的bbox,因为在此前的YOLOv1论文详解中,我们提到过,尽管原版的YOLOv1在每个网格预测两个bbox,但在推理阶段,每个网格最终只输出一个bbox,从结果上来看,这和每个网格只预测一个bbox是一样的。完整的“检测头+预测层”的结构如下方的图5所示。
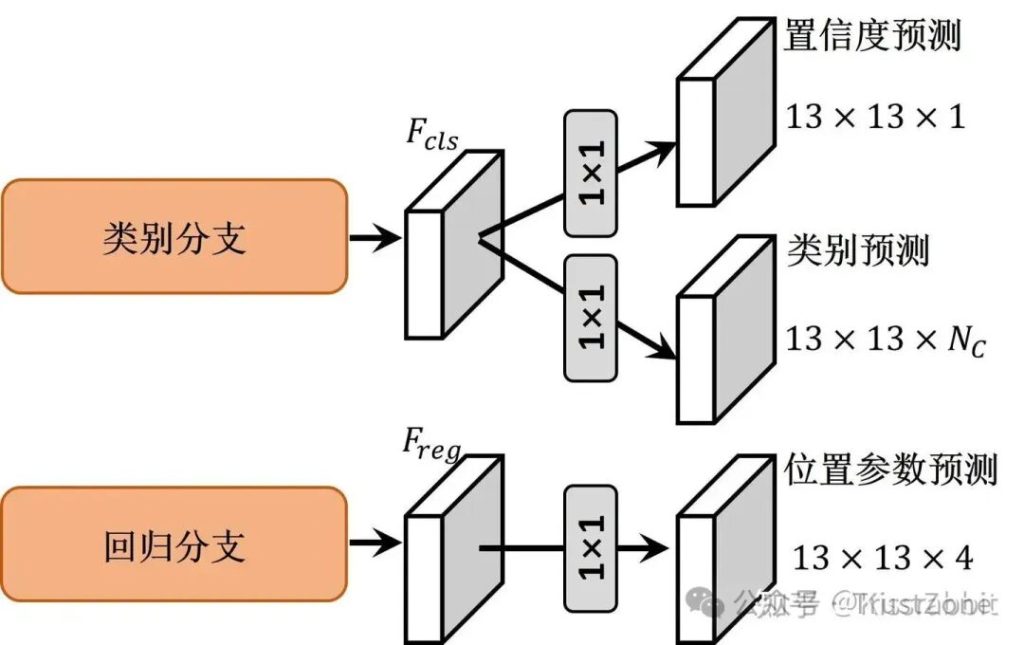
1)objectness预测。
前文我们已经讲到,这部分预测的物理含义主要是确定该bbox是否预测了一个物体,即“有无物体”的预测,虽然我们在训练阶段采用了预测的IoU作为学习标签,希望objectness即bbox的置信度也能表征bbox的检测质量,但事实上这并不严谨,因为我们并没有从数学的角度上去做这样的约束,更多是我们的“一厢情愿”。
事实上,有经验的读者不难发现,即便一个bbox定位得很准,其置信度仍可能会很低(用现在的语言来说,这种方法本质是IoU-aware,可以更好地平衡类别和定位两种语义的学习之间的矛盾)。
因此,我们不妨采用更加简单的学习策略,将其学习标签设置为0和1的二分类。
不难理解,objectness预测、即“有无物体”的预测是更多地是属于语义层面的预测,因此,我们在Decoupled head的类别分支的输出后面接一层1x1卷积去做objectness的预测,并在最后使用Sigmoid函数来输出objectness预测值。
2)classification预测。
我们在Decoupled head的类别分支的输出后面接一层1x1卷积去做classificaton的预测。
因此,classificaton预测和objectness预测都采用Decoupled的同一分支。遵循当下YOLO系列常用的方法,我们同样采用Sigmoid函数来输出classification预测值,即每个类别的置信度都是0~1。
3)bbox regression预测。
很自然的,另一分支的位置特征就被用于预测边界框的偏移量,即我们使用另一层1x1卷积去处理检测头的位置特征,得到每个网格的边界框的偏移量预测。
在原版的YOLOv1中,bbox预测主要包括目标中心点的偏移量 Cx, Cy 和归一化的边界框的宽高 w,h ,但是不论是哪个量,原版的YOLOv1均使用线性函数来输出,未加任何约束限制,很明显会有以下两点问题:
- a) 由于偏移量 Cx, Cy 是介于01范围内的数,因此,其本身就是有上下界的,而线性输出并没有上下界,这就容易导致在学习的初期,网络可能预测的值非常大,导致bbox分支学习不稳定。
- b)边界框的宽高显然是个非负数,而线性输出不能保证这一点,这也可能造成训练过程中的不稳定,一些输出一些不合理的数值(比如负数)。
对于问题a),我们使用sigmoid来输出,具体来说,假设模型的输出为 tx,ty ,我们使用sigmoid函数将其映射到0~1的范围内,保证网络的输出值是合理的。
在使用了sigmoid函数后,我们就确保网络最终预测的中心点偏移量是“合理”的数值,使得训练更加稳定。
对于问题b),一种解决办法是约束输出为非负,如用ReLU函数,但这种办法就会隐含一个约束条件,这并不利于优化,而且ReLU的0区间无法回传梯度,在一定程度上有可能造成“死元”的问题。https://wxa.wxs.qq.com/tmpl/oc/base_tmpl.html
另外,我们可以采用sigmoid函数来做这一约束,这种方法要优于ReLU函数,但是,sigmoid函数平等地处理任意尺度的坐标,没有考虑到不同尺度的目标的坐标回归难度。
对此,我们推荐采用“log-exp方法”来处理。具体来说,我们的YOLOv1所要预测的不是归一化的边界框宽高,而是经过log函数压缩后的宽高:
tw=log(y) th=log(h)
其中, w,h 是目标边界框的(未归一化)宽高。由于tw,th 的值域是实数全域,没有上下界,因此就无需担心约束条件对优化带来的影响,另外,由于log函数的指数级的压缩特性,在一定程度上可以拉近大目标和小目标之间的尺寸量级,因此,对于平衡不同尺度的目标的检测问题还能起到一定的缓解作用。
实际上,为了更好地学习这一标签,我们会将目标框的坐标先映射到网格的尺度上: ws=w/stride,hs=h/stride ,然后再做log处理。因此,在训练阶段,我们让YOLOv1去学习log尺度上的边界框宽高,然后在推理阶段,使用exp函数即可将预测恢复到正常的尺度上。
w=exp(tw) * stride h=exp(th)*stride
在部分工作中,log-exp方法也被称为“边界框坐标重参数化”,是一个很朴素但很有效的坐标回归方法。不过,这里也存在一个隐患,就是exp函数的“指数爆炸”特性,可能会在训练阶段有梯度爆炸、Loss出现NAN的隐患,就笔者个人经验而言,这种问题出现的频率很低,暂时可忽略不计。
啰嗦的白话一下!
简单来说,这段话在讨论如何设计一个检测头(Decoupled Head)来更好地完成目标检测的三项任务:判断“有没有物体”(Objectness)、判断“是什么物体”(Classification) 和 确定“物体在哪”(BBox Regression)。
下面这个表格总结了提到的Decoupled Head的核心分工和关键改进,我们先有一个整体的俯瞰:
| 预测任务 | 负责分支 | 核心功能 | 原文中提到的关键设计/改进 | 主要目的 |
|---|---|---|---|---|
| Objectness (有无物体) | 类别分支 | 预测每个位置是否存在物体,输出一个0到1之间的置信度。 | 将训练标签简化为0(无)或1(有),使用Sigmoid函数输出。 | 提供更稳定、更纯粹的“有无”信号,减少与定位质量的耦合。 |
| Classification (类别) | 类别分支 | 预测存在物体的情况下,该物体属于各个类别的概率。 | 使用Sigmoid函数独立预测每个类别的概率,而非Softmax。 | 更好地处理多标签问题(一个目标可能同时属于多个类别)。 |
| BBox Regression (位置) | 位置分支 | 预测目标边界框相对于当前网格位置的精细偏移量。 | 中心坐标(tx, ty)使用Sigmoid函数约束到(0,1);宽高(tw, th)采用 “log-exp” 变换(也称为线性化处理或重参数化)进行预测。 | Sigmoid确保中心点不溢出网格;“log-exp” 改善训练稳定性并缓解尺度敏感性问题。 |
🧠 核心概念详解
- Objectness预测(“有无”的预测)
- 它是什么:这是一个二分类问题,它的任务非常纯粹:判断网格的某个位置“有没有”一个物体,而不关心这个物体具体是什么,或者框得准不准。
- 原文的困惑与解决方案:
- 原来的做法(YOLOv1):训练时,让网络直接预测边界框与真实框的IoU(交并比) 作为置信度。理想很美好,希望这个值既能表示“有无”(IoU>0就是有),又能表示“多准”(IoU越高越准)。
- 问题所在:但事实上,“有无”是语义信息(需要看内容),“多准”是定位信息(需要看框线)。让一个信号同时学习两种差异较大的信息,会导致学习目标不清晰,容易产生矛盾。例如,一个框可能框得很准(IoU高),但网络对里面是否有物体(语义)的判断可能很犹豫,导致最终置信度不高。
- 改进策略:于是,作者提出将其简化为一个二分类问题。训练标签直接就是0(该位置没物体)或1(该位置有物体)。Sigmoid函数非常适合将网络的原始输出映射到一个(0, 1)的概率,来表示“有物体的可能性”。这样做的好处是学习目标变得非常清晰和稳定,网络只需要专注于从外观特征中判断“有无”,不再受定位质量的干扰。
- Classification预测(“是什么”的预测)
- 它是什么:在确定“有物体”的前提下,进一步判断这个物体属于各个类别的概率。
- 原文的设计: classification预测和objectness预测都采用Decoupled的同一分支。
- Sigmoid vs. Softmax:这里提到用Sigmoid而非Softmax来输出类别概率。这是一个重要细节:
- Softmax假设所有类别是互斥的(一个物体只能是猫、狗或车,不能同时是),所有类别的概率之和为1。
- Sigmoid则是独立地判断每个类别是否存在。这更灵活,可以处理多标签问题(例如,一个物体同时是“车”和“救护车”),也更适合现代数据集中可能出现的复杂情况。
- Sigmoid:用于二分类,将单个数值压缩为(0,1)的概率,表示“是”或“不是”的可能性。
- Softmax:用于多分类,将一组数值压缩为(0,1)的概率分布,所有类别概率之和为1,表示属于每个类别的可能性。
- BBox Regression预测(“在哪”的预测) 这是最复杂的一部分,原文主要讨论了如何稳定地预测边界框的偏移量。
- 目标:预测边界框的中心坐标(x, y)和宽高(w, h)。
- 问题(a):中心坐标(x, y)的边界问题
- 背景:在YOLO中,目标中心点的偏移量是相对于它所在网格的左上角计算的。因此,无论怎么偏移,这个点都不应该跑出当前网格,所以偏移量理论上应该在0到1之间。
- 原版YOLOv1的隐患:原版使用线性输出,没有限制范围。网络在训练初期可能预测出很大的数值(如100, -50),这会导致梯度剧烈波动,训练不稳定。
- 解决方案:使用 Sigmoid函数将输出约束在(0, 1)范围内。这样确保了预测的偏移量一定是合理的,极大增强了训练的稳定性。
- 问题(b):宽高(w, h)的正数性和尺度问题
- 解决正数问题:
log函数的定义域就是正数,从网络设计上就避免了负值问题。 - 缓解尺度差异:
log函数能压缩数值的动态范围。一个大目标(w=100)和一个小目标(w=10)之间的绝对差是90,但经过log变换后,log(100)=4.6,log(10)=2.3,它们的差变成了2.3。这个变化范围更小,使得网络对不同尺寸的目标的回归难度更加均衡,让小目标和大目标的学习难度相对拉平,改善了训练效果。
- ReLU:可以保证非负,但可能会“杀死”神经元(梯度为0),且没有上限。
- Sigmoid:虽然能约束到(0,1),但它是平等地压缩所有尺度的值。对于小目标,宽高本身很小,Sigmoid够用;但对于大目标,其宽高可能被压缩在Sigmoid曲线靠近1的饱和区,导致梯度消失,难以学习。
- 背景:宽高必须是正数。
- 原版YOLOv1的隐患:线性输出同样可能产生负值,这是没有意义的,也会导致训练不稳定。
- 初期方案(ReLU/Sigmoid)的缺点:
- 推荐的“log-exp”方法:
- 学习目标变换:不让网络直接预测宽高
w和h,而是让它们学习tw = log(w / stride),th = log(h / stride)。这里的stride是下采样倍数,用于将真实宽高映射回特征图的尺度。 - 为什么有效:
- 推理时转换回来:在预测时,只需要对网络的输出
tw_pred,th_pred进行exp操作,再乘上stride,就能恢复到原图上的宽高:w_pred = exp(tw_pred) * stride。
- 解决正数问题:
💡 一点额外的理解
原文片段反映的是对YOLOv1等早期设计的大量反思和工程优化。这些改进(如Objectness二分类、Sigmoid约束中心点、log-exp处理宽高)如今已成为许多现代目标检测模型(包括后续YOLO系列)的标准配置。它们背后的核心思想是一致的:通过精心设计网络输出层和损失函数,将复杂的物理问题转化为更稳定、更易于神经网络学习和优化的数学形式。
下一节,我们将会使用python语言和当下流行的PyTorch深度学习框架去搭建我们的YOLOv1。因而,也希望读者熟悉python语言,并拥有一定的PyTorch框架使用经验(比如可以手动实现完整的CIFAR10的图像分类任务)
关于python和PyTorch基础,咱们自己补补,这个部分要是展开那就多了。不过这里确实可以搞个PyTorch的案例来玩玩。
微信扫描下方的二维码阅读本文

Comments NOTHING