点击关注公众号,Java干货及时送达?
一、Caffeine介绍
1、缓存介绍
缓存(Cache)在代码世界中无处不在。从底层的CPU多级缓存,到客户端的页面缓存,处处都存在着缓存的身影。缓存从本质上来说,是一种空间换时间的手段,通过对数据进行一定的空间安排,使得下次进行数据访问时起到加速的效果。
就Java而言,其常用的缓存解决方案有很多,例如数据库缓存框架EhCache,分布式缓存Memcached等,这些缓存方案实际上都是为了提升吞吐效率,避免持久层压力过大。
对于常见缓存类型而言,可以分为本地缓存以及分布式缓存两种,Caffeine就是一种优秀的本地缓存,而Redis可以用来做分布式缓存
2、Caffeine介绍
Caffeine官方:
https://github.com/ben-manes/caffeine
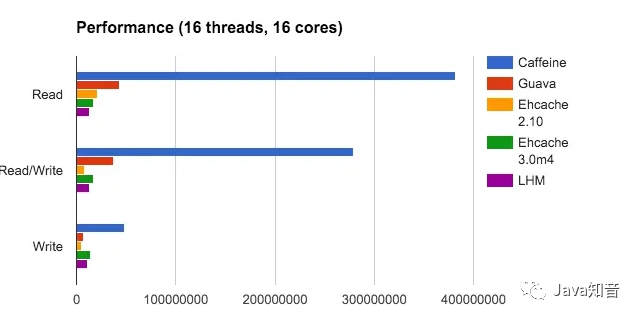
Caffeine是基于Java 1.8的高性能本地缓存库,由Guava改进而来,而且在Spring5开始的默认缓存实现就将Caffeine代替原来的Google Guava,官方说明指出,其缓存命中率已经接近最优值。实际上Caffeine这样的本地缓存和ConcurrentMap很像,即支持并发,并且支持O(1)时间复杂度的数据存取。二者的主要区别在于:
-
ConcurrentMap将存储所有存入的数据,直到你显式将其移除; -
Caffeine将通过给定的配置,自动移除“不常用”的数据,以保持内存的合理占用。
因此,一种更好的理解方式是:Cache是一种带有存储和移除策略的Map。
二、Caffeine基础
使用Caffeine,需要在工程中引入如下依赖
/**
* value:缓存key的前缀。
* key:缓存key的后缀。
* sync:设置如果缓存过期是不是只放一个请求去请求数据库,其他请求阻塞,默认是false(根据个人需求)。
* unless:不缓存空值,这里不使用,会报错
* 查询用户信息类
* 如果需要加自定义字符串,需要用单引号
* 如果查询为null,也会被缓存
*/
@Cacheable(value = CacheConstants.GET_USER,key = "'user'+#userId",sync = true)
@CacheEvict
public UserEntity getUserByUserId(Integer userId){
UserEntity userEntity = userMapper.findById(userId);
System.out.println("查询了数据库");
return userEntity;
}
来源:blog.csdn.net/lemon_TT/article/
details/122905113
热门内容:
最近面试BAT,整理一份面试资料《Java面试BAT通关手册》,覆盖了Java核心技术、JVM、Java并发、SSM、微服务、数据库、数据结构等等。 获取方式:点“在看”,关注公众号并回复 666 领取,更多内容陆续奉上。 明天见(。・ω・。) 本篇文章来源于微信公众号: 方志朋
微信扫描下方的二维码阅读本文

Comments NOTHING