STRAT
乘风破浪 | 直挂云帆
只要是MQ都会存在或多或少的问题,但是处理问题的方式方法各不相同,今天我们来分析一下RabbitMQ是如何处理生产中的各种问题。
消息丢失
消息丢失的处理方式:消息确认模式+持久化。
当然针对不同的场景,会存在不同的处理方案。
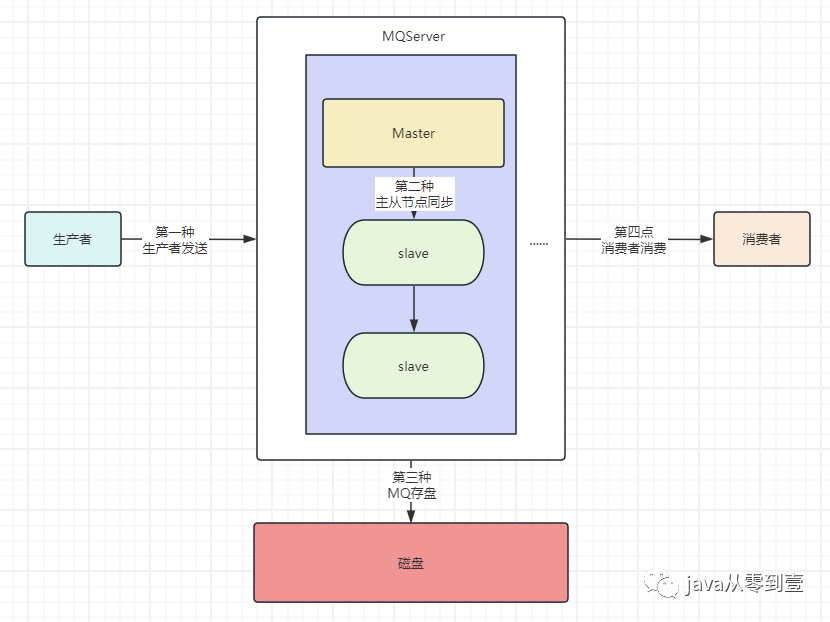
使用生产者确认机制来保证消息不丢失,而确认机制存在两种方式。
同步确认:主要体现在生产者端调用channel.waitForConfirmsOrDie()方法指定一个等待确认的时间。
异步确认:主要通过添加监听器,在channel过程中可以添加一个失败和成功的监听器,channel.addConfirmListener(ConfirmCallback var1, ConfirmCallback var2),通channel.getNextPublishSeqNo()来确定唯一的消息,然后通过存储的map找出消息体。
如果发送的是批量消息,我们还可以使用手动事务来保证消息的正确发送。
channel.txSelect() 开启事务;
channel.txCommit() 提交事务;
channel.txRollback() 回滚事务;
我们设置队列类型时候选择Classic类型,设置持久化类型为true,而其他两种类型都默认是true,这样都能更好的保证消息不丢失。
消息在消费的时候可以指定自动应答或者是手动应答,一般来要确保不存在其他问题,手动模式更好,消息的可靠性更好(自动应答设置为true,手动需要设置channel.basicAck等)。
消息幂等
幂等表示消息只能被消费一次,而Rabbitmq很好的保证了幂等,在消息消费过程中,消费过了就直接将消息移除,如果存在确认机制,可以重新去执行(可以手动设置重试的次数),如果存在死信队列就会入队列,如果都没有直接就丢弃了该消息。当然业务场景我们一样得设置一个唯一标识来防止重复生成,比如:生成订单我们可以去判断订单是否生成,如果已经生成了就不会生成了,这样更好保证消息的幂等。
消息顺序
RabbitMQ的消息顺序,只支持HelloWord模式,就是一个队列绑定一个消息者,这样才能保证消息的顺序。在多队列情况下,如何保证消息的顺序性,目前使用RabbitMQ的话,还没有比较好的解决方案。在使用时,应该尽量避免这种情况。
消息堆积
RabbitMQ一直以来都有一个缺点,就是对于消息堆积问题的处理不好。当RabbitMQ中有大量消息堆积时,整体性能会严重下降。而目前新推出的Quorum队列以及Stream队列,目的就在于解决这个核心问题。但是这两种队列的稳定性和周边生态都还不够完善,目前大部分企业还是围绕Classic经典队列构建应用。因此,在使用RabbitMQ时,还是要非常注意消息堆积的问题。尽量让消息的消费速度和生产速度保持一致。
曲线救国方案:使用懒队列,使用插件分片等。要提升消费速度最直接的方式,就是增加消费者数量。尤其当消费端的服务出现问题,已经有大量消息堆积时。这时,可以尽量多的申请机器,部署消费端应用,争取在最短的时间内消费掉积压的消息。但是这种方式需要注意对其他组件的性能压力。
总结:这些东西都是抽象的概念,后续有机会,我会将基本操作结合Springboot展现出来共同学习。
文章有帮助的话, 点赞、在看、转发吧。
点赞、在看、转发吧。
一起讨论,谢谢支持哟






本篇文章来源于微信公众号: java从零到壹
微信扫描下方的二维码阅读本文

Comments NOTHING