本文是翻译,首发于 k8s 介绍,原文:An introduction to Kubernetes
这篇博客将介绍 Kubernetes(k8s),以便你了解其背后的动机、它是什么以及如何使用它。在后续的文章中,我将讨论在数据科学类型应用程序中使用 k8s 更加具体的例子。而本文的重点是首先帮助你建立对基本概念的理解。
需要注意的是,我将假设你熟悉容器技术,如 Docker。如果你没有构建、运行容器镜像的经历,我建议你先看这里再读这篇文章。
k8s 是什么
k8s 通常被描述为一个容器编排(container orchestration)平台。为了理解这个含义,让我们重新审视容器的作用,这有助于知道容器有哪些不足,以及 k8s 如何弥补这些不足。
为什么我们喜欢使用容器?容器提供了一个轻量级的机制来隔离应用程序的环境。对于一个给定的应用程序,我们可以指定其配置和所需要安装的依赖,而不用担心其与同一台物理机上其他的应用程序发生冲突。我们将每个应用程序封装在容器镜像(container image)中,容器镜像可以可靠地运行在任何机器(只要机器有能力运行容器镜像)上,能够提供可移植的能力,即支持应用开发到部署的平滑过渡。此外,因为每个应用是独立的,不用担心环境冲突,所以在同一台物理机上可以部署多个容器,实现更高的资源(内存和 CPU)利用率,最终降低成本。
使用容器,会有哪些不足?比如,你的容器挂掉了会发生什么?或者更糟糕,容器发生错误,又或者机器运行容器失败会发生什么?要知道,容器是没有容错(fault tolerance)的能力。或者你有多个容器需要通信,如何在容器之间建立通信网络?当你启动、终止单个容器时,这种情况会发生什么变化?容器网络很容易变成一团混乱。最后,假设你的生产环境有多个机器,你将如何抉择使用哪个机器运行你的容器?
k8s 作为容器编排平台。 使用 k8s,我们可以解决很多上面提到的问题。
管弦乐队的指挥掌握着音乐表演的效果,并与音乐家们沟通,以协调他们各自的乐器,从而达到表演的总体效果。作为一个系统的架构师,你的工作只是编写音乐(指定要运行的容器),然后将控制权交给管弦乐队的指挥(容器编排平台)从而来实现这一目标。


k8s 管理着每个容器的全生命周期,如根据需要启动或停止容器。如果一个容器意外关闭,k8s 将会运行另一个容器快速代替它。
除此之外,k8s 提供一种机制,可以让应用程序相互通信,即使在底层单个容器正在被创建或正在被销毁的时候。
最后,给定要运行的一组容器和集群上的一组机器,k8s 检查每个容器并调度应用程序到最佳机器上。要了解为什么这是很有价值的,请观看 Kelsey Hightower(17:47-20:55)使用俄罗斯方块示例游戏解释自动化部署和容器编排之间的区别。
设计原则
现在我们大体上了解了 k8s 是什么,让我们花点时间讨论下 k8s 背后设计原则动机。它有助于让我们理解这些原则,以便你可以按预期使用该工具。
声明式
也许 k8s 最重要的设计原则就是,我们只需要简单地定义系统期望的状态(desired state),让 k8s 自动化工作,以确保实际的状态(actual state)与我们期望的状态一致。这使你免于承担大多数损坏时修理它们的责任。你只需要声明理想状态下系统应该是什么样子即可。当系统真实的状态与期望的状态不一致时,k8s 自动代替你处理这些问题。这使得我们的系统能够自我修复(self-healing)并对问题做出反应,而无需人工干预。
系统的状态(state)是由一组对象(objects)定义的。每个 k8s 对象都有一个清单(specification),包含你期望的状态和当前实际的状态。k8s 维护所有对象的清单列表,并不断轮询每个对象,以确保其状态与清单相同。如果一个对象没有响应,k8s 将会使用新版本的代替它。如果某个对象偏离了清单,k8s 将发出必要的命令使对象回到期望的状态。
分布式
应用达到一定规模,有必要将应用部署在分布式系统上。k8s 旨在为此类分布式应用提供基础设施层,产生简明的抽象,在一组机器(统称为集群)上构建应用程序。更具体的说,k8s 为与该集群交互提供了一个统一的接口,因此你不必担心如何与每台机器进行单独通信。
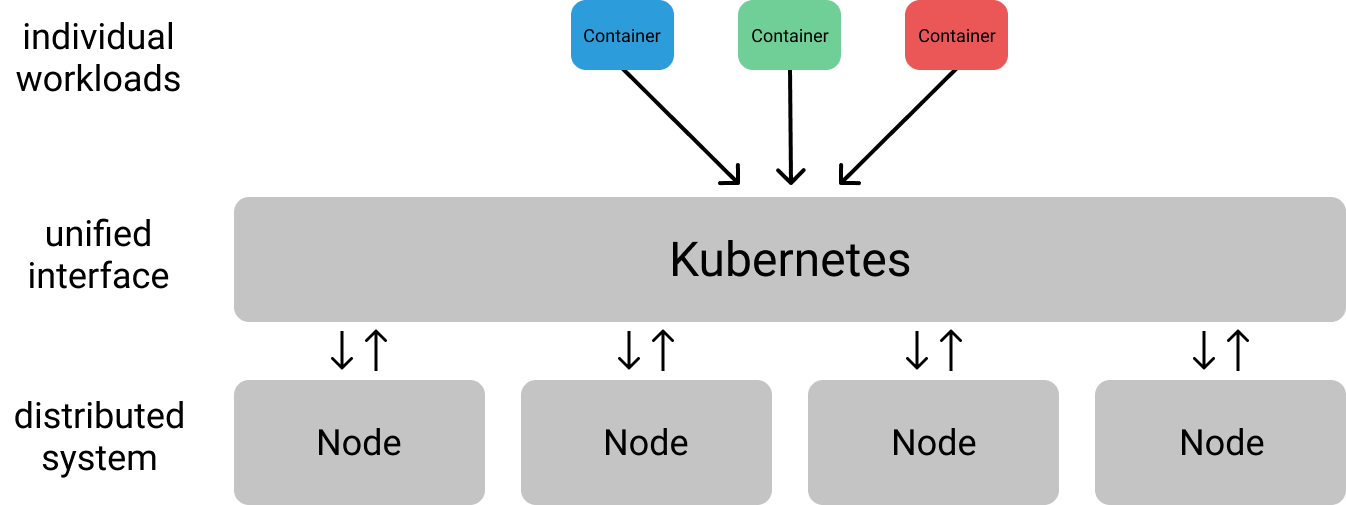
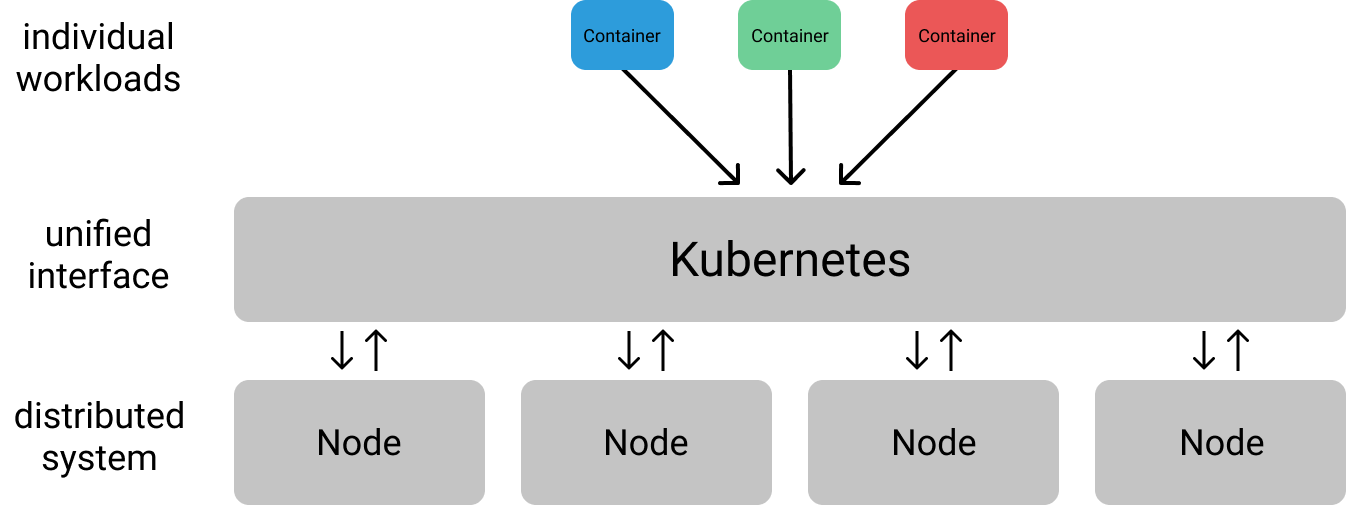
解耦
通常建议在开发容器时要特别注意。因此,开发容器化应用程序非常适合微服务体系结构设计模式,该模式建议「将应用程序设计为可独立部署的服务套件」。
k8s 中提供的抽象自然支持可独立伸缩和更新解耦服务的思想。这些服务在逻辑上是分开的,并通过定义良好的 API 进行通信。这种逻辑上的分离使团队可以更快地将更改部署到生产环境中,因为每个服务都可以在独立的发布周期内运行(前提是他们遵守现有的 API 合约)。
不可变基础设施
为了从容器和 k8s 中收益最大化,你应当部署不可变基础设施。与登录到一台机器的容器中进行修改(如更新依赖库)不同,你应该构建新的容器镜像,部署新的版本,并终止旧版本的容器。在应用程序生命周期(开发环境->测试环境->生产环境)中跨环境过渡时,应该使用相同的容器镜像,并只修改容器镜像外部的配置(如挂载的配置文件)。
这一点非常重要,因为容器被设计为临时的,随时可以被另一个容器实例替换。如果原始容器处于突变状态(例如手动更改配置),但由于健康检查失败而被关闭,则在其位置启动的新容器不会生效这些手动更改,并可能破坏应用程序。
维护不可变基础设施,将应用程序回滚到以前的状态(例如发生了错误)也变得更加容易,可以简单地更新配置以使用较旧的容器镜像。
译者注:不可变基础设施是由 Chad Fowler 于 2013 年提出的一个很有前瞻性的构想:在这种模式中,任何基础设施的实例(包括服务器、容器等各种软硬件)一旦创建之后便成为一种只读状态,不可对其进行任何更改。如果需要修改或升级某些实例,唯一的方式就是创建一批新的实例以替换。这种思想与不可变对象的概念是完全相同的。
k8s 基本对象
在前面,我提到我们通过一组 k8s 对象来描述我们所期望的系统状态。直到现在,我们对 k8s 的讨论还比较抽象和高屋建瓴。在本节中,我们将通过介绍 k8s 中可用的基本对象,深入了解有关如何在 k8s 上部署应用程序的更多细节。
k8s 对象可以用 YAML 或者 JSON 格式文件定义,这些文件通常被称为清单文件。将这些清单文件保存在版本控制仓库中是一个很好的做法,它可以作为 k8s 集群上正在运行哪些对象的唯一事实来源。
Pod
Pod 对象是 k8s 中基础对象,由一个或多个(紧密相关)容器组成,并且这些容器共享网络和文件系统。类似于容器,Pod 被设计成拥有短暂的生命周期,不会期望特定的 Pod 长期存在。
https://wp-moto-1258805347.cos.ap-shanghai.myqcloud.com/default/nine/2023-07-13/15-54-10/20230713155410eded7afa4.jpghttps://wp-moto-1258805347.cos.ap-shanghai.myqcloud.com/default/nine/2023-07-13/15-54-10/20230713155410eded7afa4.jpg
通常你不会显示地通过清单文件创建 Pod 对象,因为使用更高级的对象管理 Pod 对象通常更简单。
Deployment
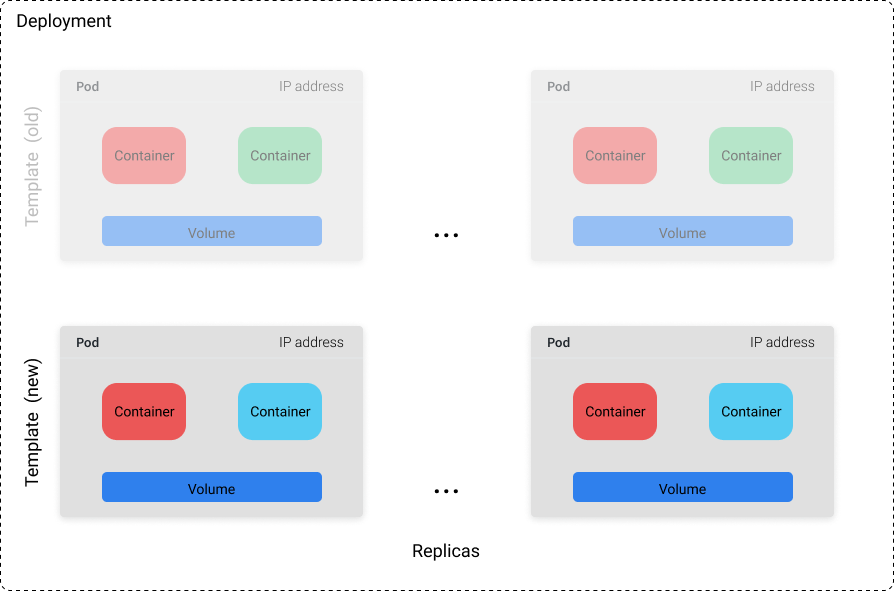
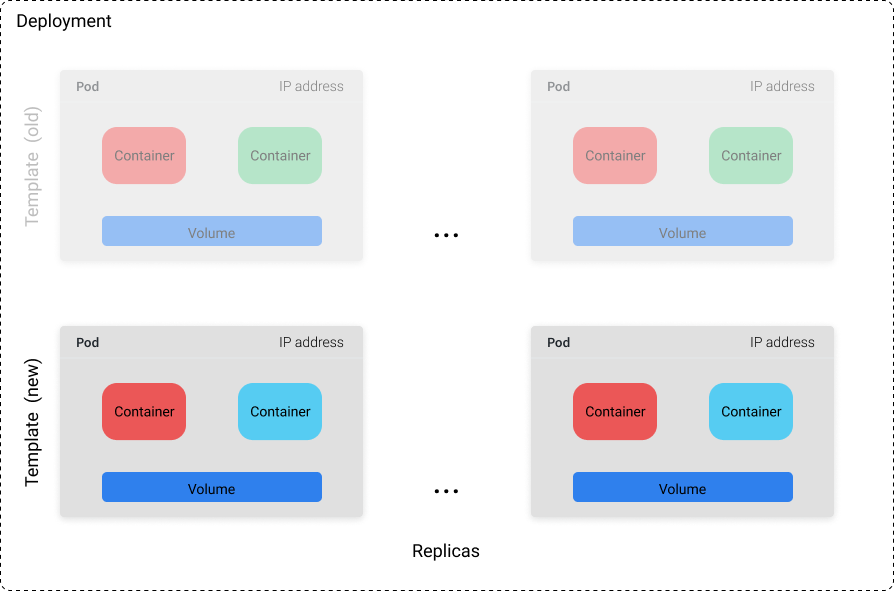
Deployment 对象包含由模板和副本数(要运行的模板数量)定义的 Pod 集合。你可以设置具体的副本数,也可以使用单独的 k8s 资源(如 HPA),基于系统性能指标如 CPU 使用率来控制副本数。
注意,Deployment 对象的控制器实际上会在背后创建 ReplicaSet 对象。然而,这对作为用户的你来说是抽象的。
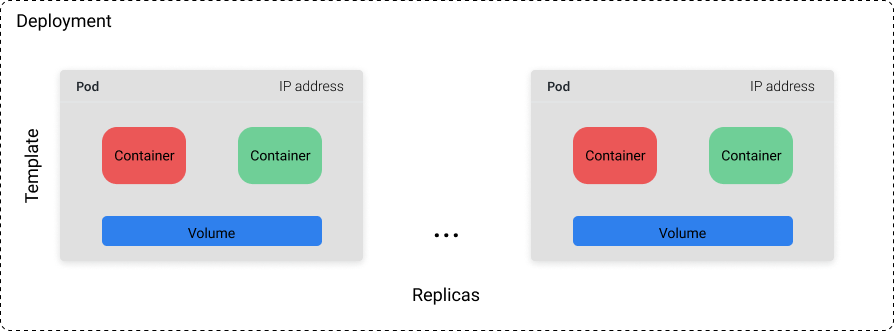
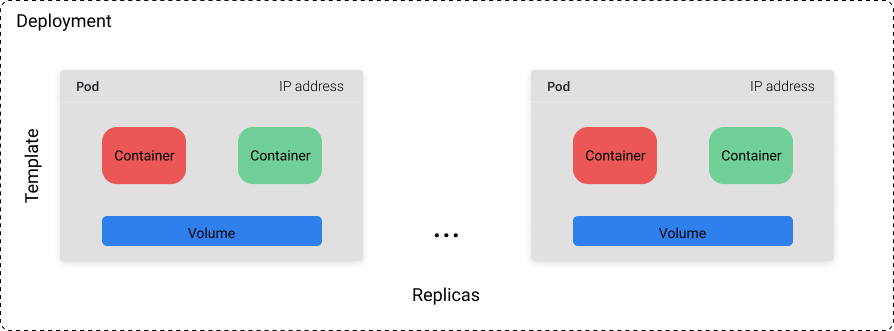
虽然你不能依赖任何单一 Pod 永远的保持运行,但你可以依赖这样一个事实:集群总是能保证 n 个 Pod 运行中(其中 n 是你定义的副本数)。如果我们有一个 Deployment,其副本数为 10,并且其中 3 个 Pod 由于机器故障而崩溃,这 3 个 Pod 将会在集群中的其他机器上被调度运行起来。因此,Deployment 是最适合无状态应用程序使用,Pod 能够随时被替换而不破坏其他东西。
下面 的 YAML 文件提供了一个带有注释的示例,展示了如何定义 Deployment 对象。在这个例子中,我们想运行 10 个容器实例,这些容器通过 REST 接口为机器学习模型提供服务。
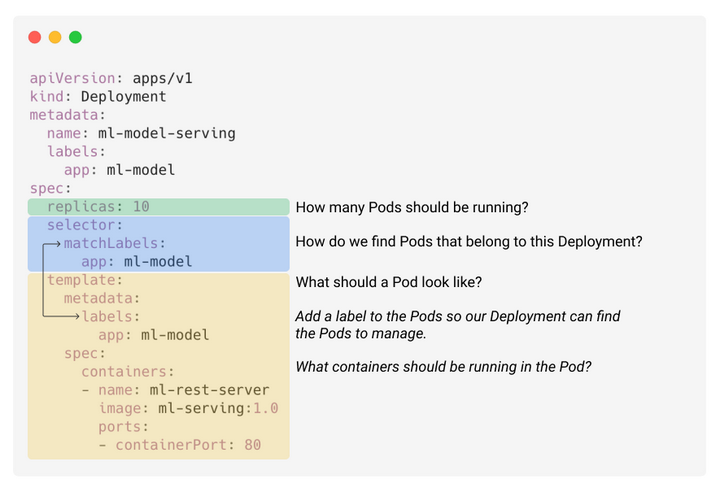
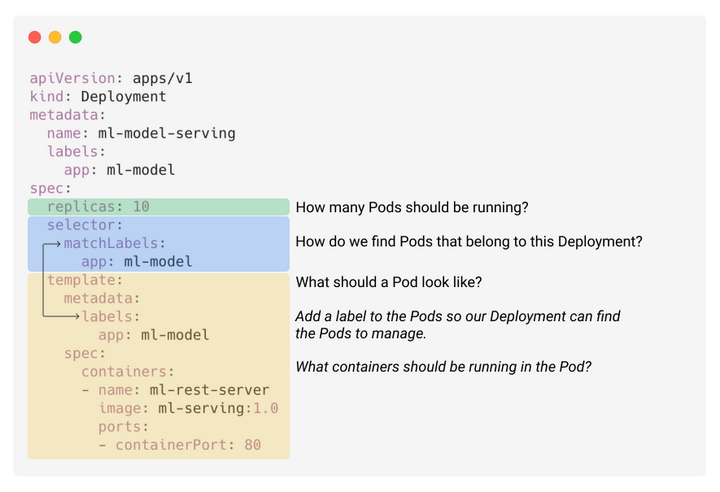
为了让 k8s 知道应用程序大概的负载,我们还应该在 Pod 模板清单中提供资源限制参数。
Deployment 还允许我们指定在拥有新的容器镜像时,我们希望如何进行更新。这篇文章很好地概述了不同操作选项。如果我们想覆盖默认值,我们可以在 Deployment 对象 spec 下附加一个 strategy 字段。 k8s 将确保优雅地关闭正在运行中的旧容器镜像的 Pod 并启动运行新容器镜像的新 Pod。
Service
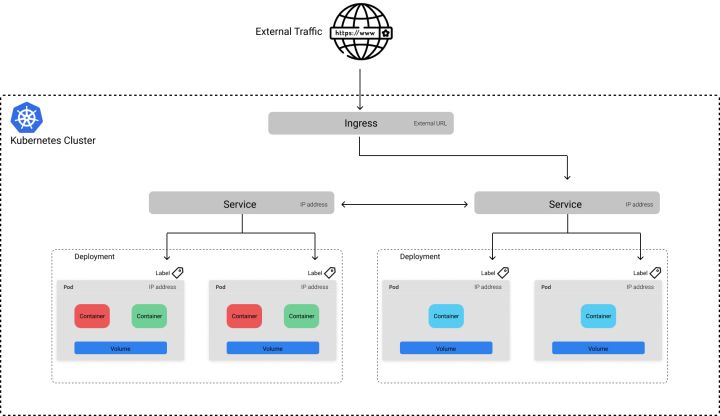
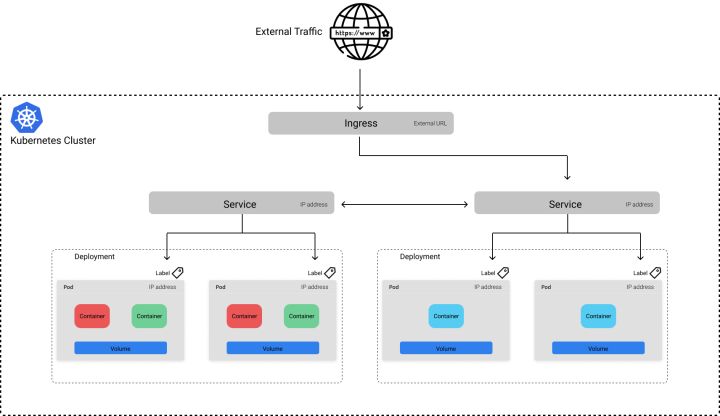
k8s 为每个 Pod 都分配了一个唯一的 IP 地址,可以使用这个 IP 来通信。但是,由于 Pod 的生命周期是短暂的,所以很难把流量发送到指定的容器上。例如,让我们考虑上面提到的 Deployment,有 10 个 Pod 运行,为机器学习模型提供 REST 接口服务。作为 Deployment 的一部分,这些运行的 Pod 可以随时更改,我们如何与服务器可靠地通信?这时 Service 对象映入眼帘。k8s 的 Service 提供了一个稳定的端点(endpoint),它可以用来将流量定向到所需的 Pod 上,即使底层 Pod 由于更新、扩展和故障而发生变化。Service 基于我们在 Pod 清单文件中元数据(metadata)中定义的标签(是键值对)知道应该向哪些 Pod 发送流量。
这篇文章很好的解释了流量是如何实际路由的。
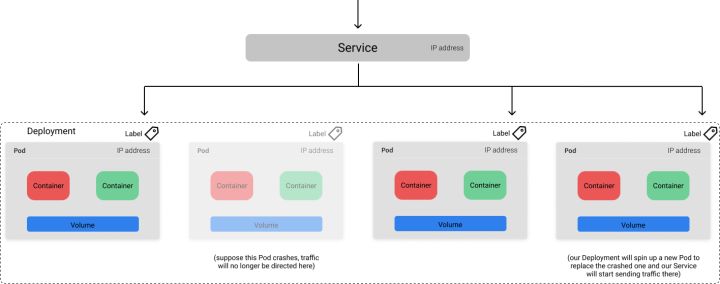
上图展示了 Service 通过 app=ml-model 标签将流量打到所有健康的 Pod 上。
以下 YAML 文件提供了一个示例,展示了我们如何根据早期的 Deployment 示例包装成 Service。


Ingress
虽然 Service 允许我们将应用程序公开在稳定的端点后面,但该端点仅可用于内部集群的通信。如果我们想将应用程序暴露给集群外部,则需要定义一个 Ingress 对象。
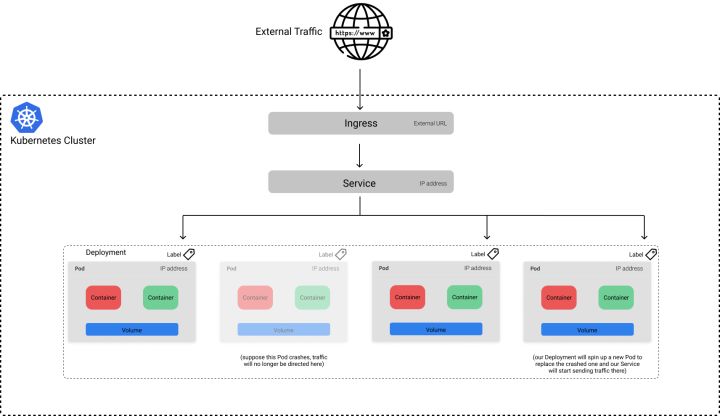
这种方法的好处是,你可以选择将哪些服务公开在外网。例如,假设除了我们为机器学习模型提供的服务以外,还有一个 UI 服务,它将模型的预测作为更大的应用程序的一部分加以利用。我们可以选择只让 UI 服务暴露在外网,这样用户就不能直接查询模型提供的服务。
下图是一个 Ingress 对象的 YAML 文件例子,使 UI 服务可以公开访问。


Job
到目前为止,我已经介绍过的 k8s 对象可以组合起来创建可靠的并能长期运行的服务。相反,当你想要执行离散的任务时,Job 对象很有用。例如,假设每天要基于前一天收集的数据重新训练模型。每一天,我们都想启动一个容器来执行一个预定义的程序(如 train.py 脚本),然后训练结束时关闭容器。而 Job 正好为我们提供了这种能力。如果由于某种原因我们的容器在运行完脚本之前崩溃了,k8s 将会启动一个新的 Pod 代替它来继续完成工作。Job 对象,期望的状态就是任务的完成。
以下 YAML 文件定义了一个用于训练机器学习模型的 Job 示例(假设在 train.py 文件定义了训练的代码)。


注意,此 Job 将会让训练的代码只执行一次。如果我们想每天执行此任务,则可以定义一个 CronJob 对象。
其他
上面讨论的对象当然不是 k8s 中可用对象的详尽列表。在部署应用程序过程中,你可能会发现一些其的对象很有用,包括:
- Volume: 用于将目录挂载到 Pod
- Secret: 用于存储敏感的凭证信息
- Namespace: 用于分离集群上的资源
- ConfigMap: 用于指定应用程序配置的文件
- HorizontalPodAutoscaler(HPA): 根据 Pod 当前资源利用率弹性伸缩 Deployment
- StatefulSet: 类似于 deployment,当你需要运行一个有状态的应用程序时会使用它
k8s 控制平面
至此,你可能想知道 k8s 如何能够使用我们所写的对象清单并在集群上运行这些应用程序。在本节中,我们将讨论构成 k8s 控制平面(control plane)的组件,这些组件控制如何在集群上运行、监控、和维护应用程序。在我们深入研究之前,区分集群中两类机器很重要:
- 主节点(master node)包含了控制平面的大部分组件,我们将在下面讨论这些组件。在大多数中等规模的集群中,只有一个主节点,尽管可以有多个主节点来实现高可用性。如果你使用云厂商托管的 k8s 服务,则它们通常会抽象出主节点,而你不需要管理或为此付费。
- 工作节点(worker node)工作节点是实际运行应用程序工作负载的机器。可以根据集群上不同类型的工作负载定制多种不同的机器类型。例如,你可能有一些 GPU 性能较好的节点用于更快的模型训练,然后使用 CPU 较好的节点来提供服务。定义对象的清单时,可以指定将该应用程序分配给哪种机器类型的选项。
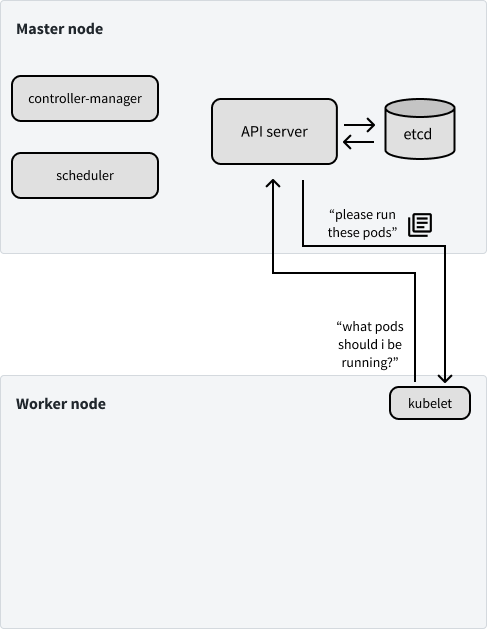
现在,让我们来深入了解主节点上的主要组件。当你提供新的或者更新的对象清单与 k8s 通信时,实质是正在与 API server 进行通信。
https://wp-moto-1258805347.cos.ap-shanghai.myqcloud.com/default/nine/2023-07-13/15-54-16/202307131554164444c0d0e.jpghttps://wp-moto-1258805347.cos.ap-shanghai.myqcloud.com/default/nine/2023-07-13/15-54-16/202307131554164444c0d0e.jpg
更具体地说,API server 会验证更新对象的请求,并充当查询集群当前状态的统一接口。但是,集群的状态是存储在 Etcd 中,Etcd 是一个分布式的键值存储。我们将使用 Etcd 上存储以下信息:集群配置、对象的清单、对象状态、集群上的节点,以及分配给对象运行的节点的信息。
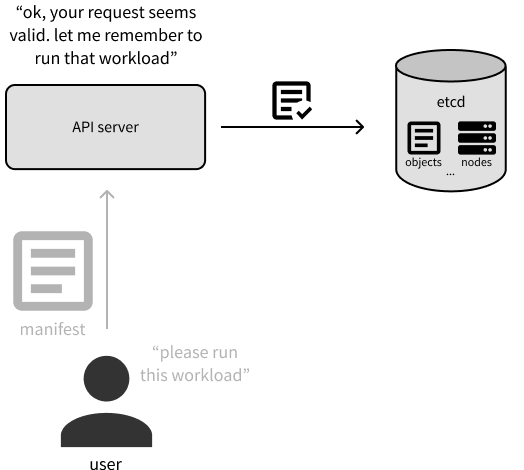
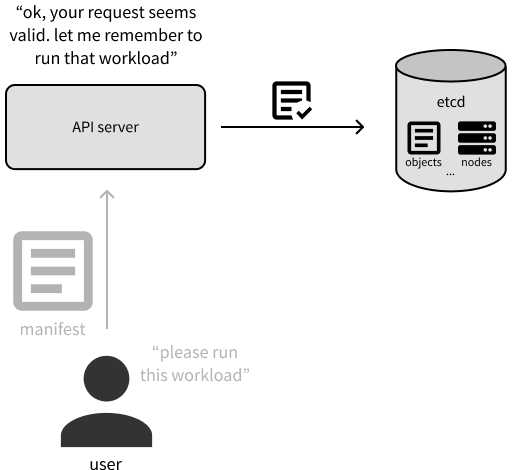
注意,Etcd 是控制面板中唯一一个是有状态的组件,其他所有的组件是无状态的。
scheduler 负责 k8s 的对象在哪里运行。scheduler 会询问 API server(它将与 Etcd 通信)哪些对象还没有分配到机器。scheduler 将确定应将这些对象分配到哪些机器上,并将回复 API server 以反馈此次分配(该分配信息将传播到 Etcd)。
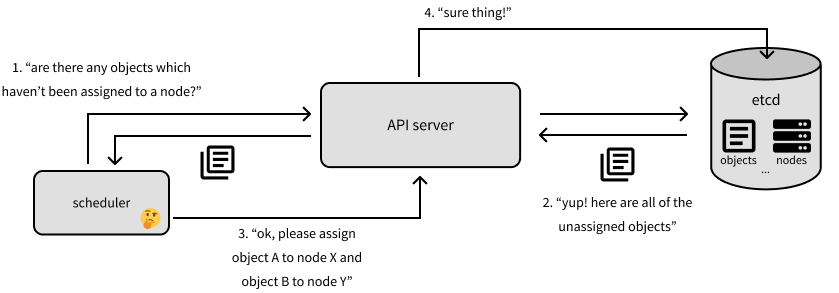
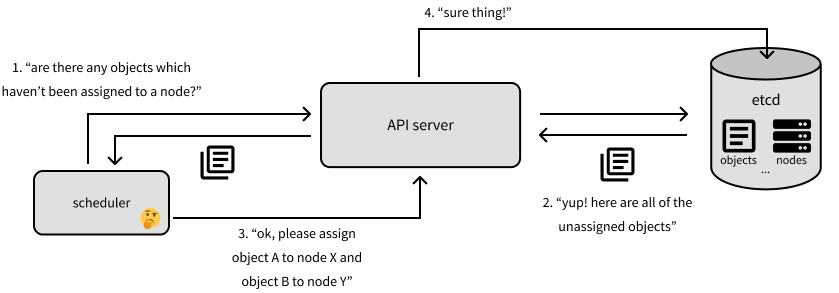
我们将在本文中讨论主节点上最后一个组件是 controller-manager,它通过 API server 监视集群的状态,查看集群的当前状态是否符合我们的期望状态。如果实际状态与我们的期望状态不同,controller-manager 将通过API server 更改,以试图推动集群到所需状态。controller-manager 是由一组 controller 组成,每个 controller 负责管理集群上特定类型资源的对象。在非常高的层次上,controller 将监视存储在 Etcd 中的特定资源类型(例如 Deployment)的信息,并为 Pod 创建清单,这些 Pod 应该运行以实现对象的期望状态。然后,controller 负责确保这些 Pod 在运行时保持健康,并在需要时关闭它们。
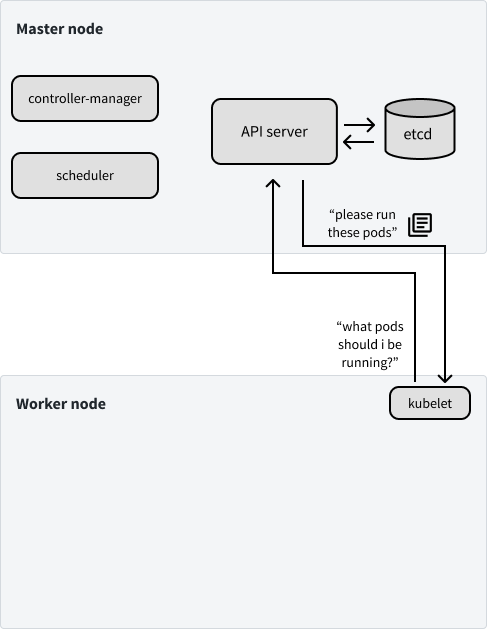
下图总结了到目前为止我们所说的。
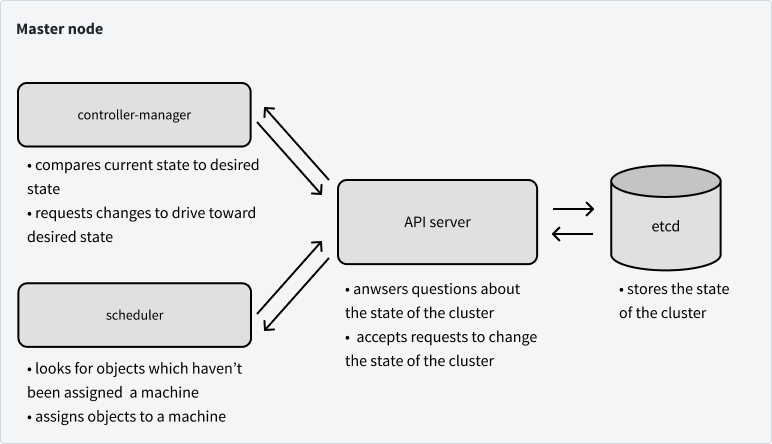
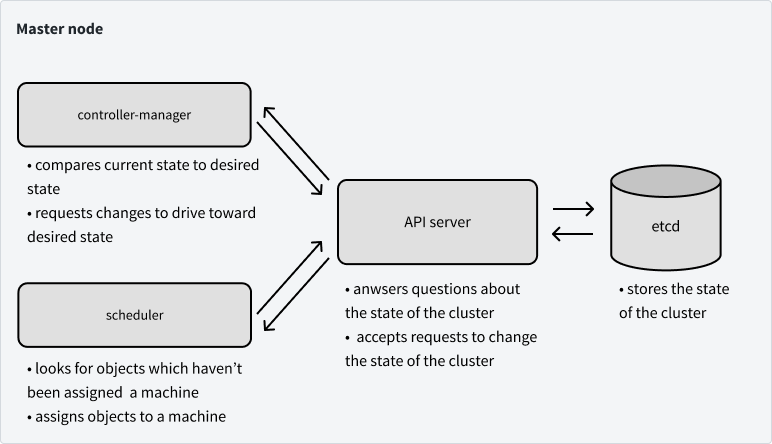
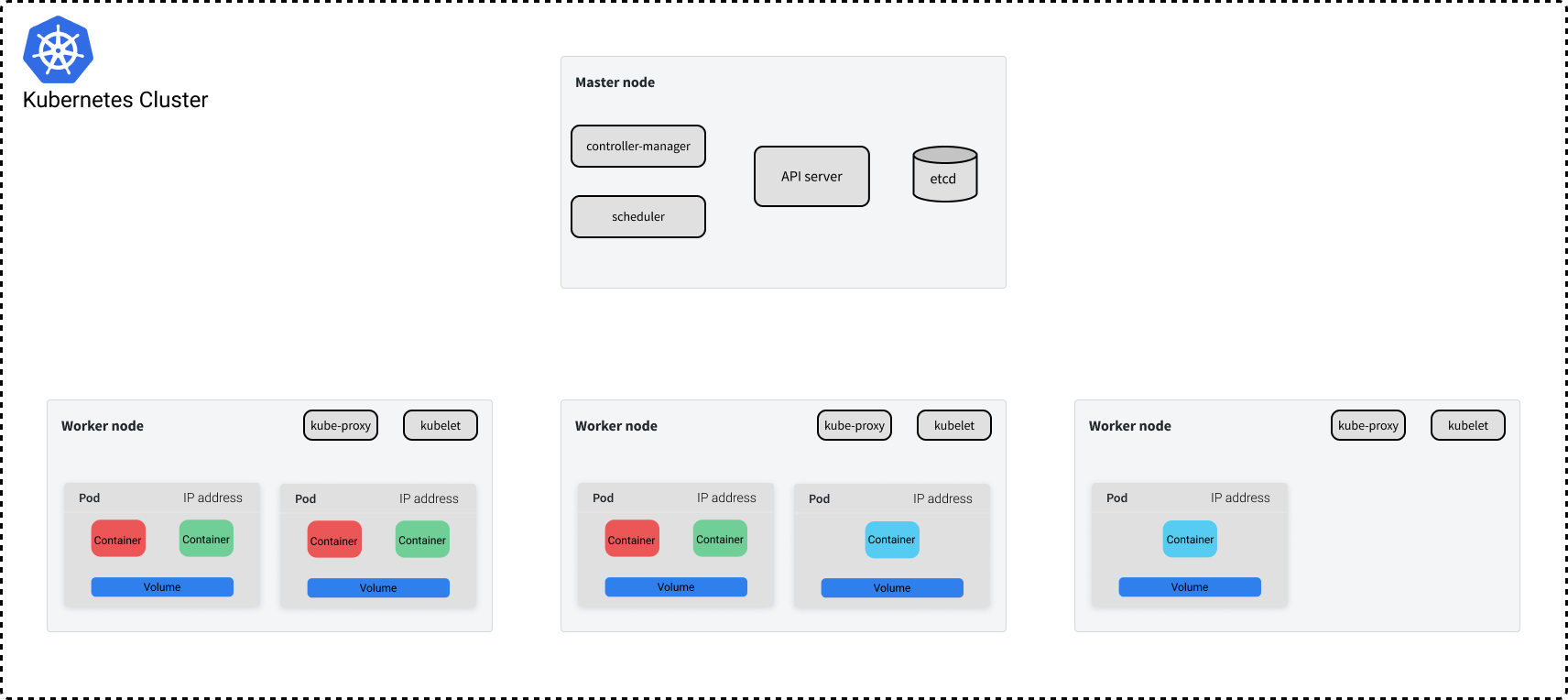
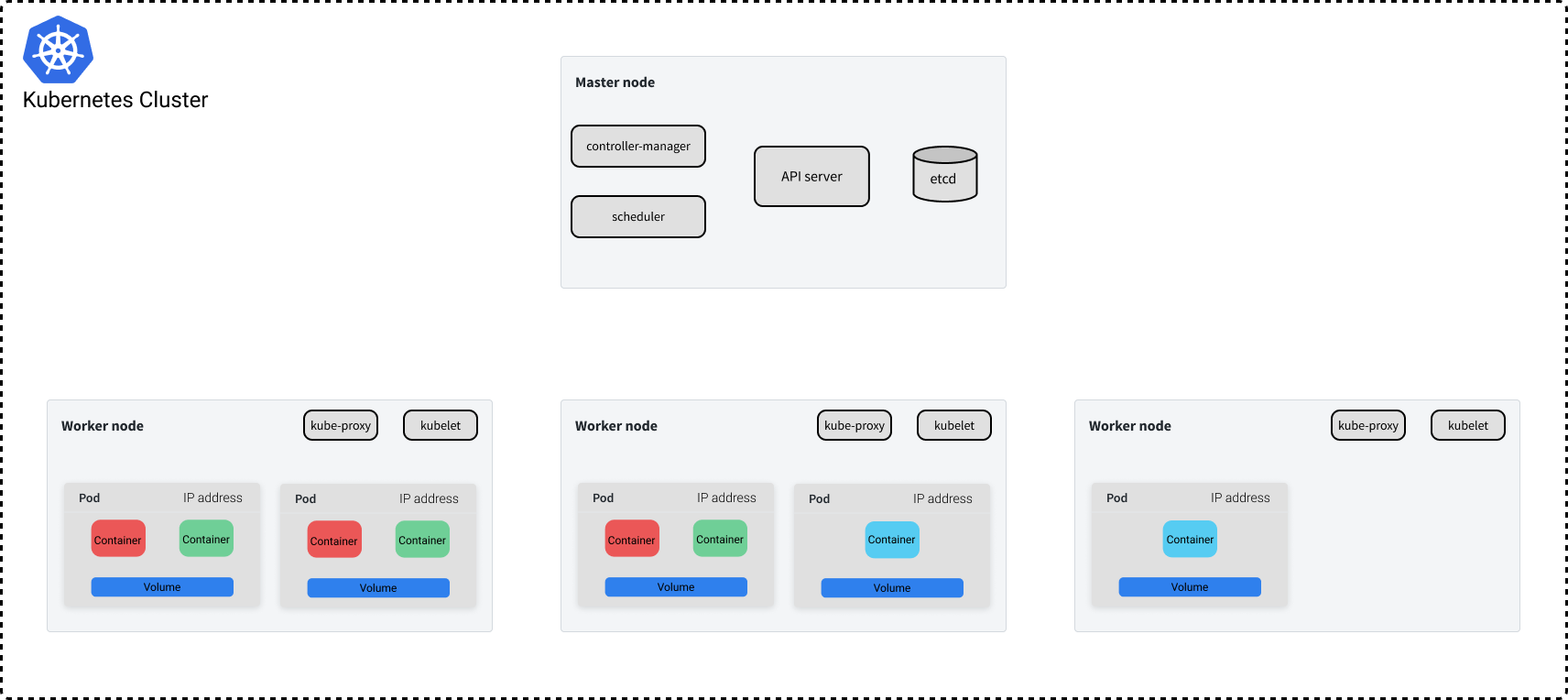
接下来说说运行在工作节点的控制面板组件。工作节点上大部分可用的资源是用于运行我们实际的应用程序,但是我们的节点确实需要知道它们应该运行哪些 Pod,以及如何与其他节点上的 Pod 通信。接下来我们将讨论控制平面的最后两个组件,它们恰好涵盖了了这两个问题。
kubelet 就像是节点上的代理(agent),该代理与 API server 通信以查看已将哪些应用程序的容器分配给该节点。然后它负责启动 Pod 运行分配到节点的应用程序。当节点首次加入集群当中时,kubelet 负责向 API server 宣布节点的存在,以便 scheduler 可以为其分配 Pod。
最后一个组件是 kube-proxy,它能够让容器跨集群的各个节点相互通信。kube-proxy 处理所有网络问题,例如如何将流量转发到适当的 Pod 上。
到这里,你应该能够开始了解有关 k8s 集群整体的运行方式。所有的组件都通过 API server 交互,将集群的状态存储在 Etcd 中。多种组件(通过API server)写入 Etcd,以对集群进行更改,集群上的节点(也是通过 API server)监听 Etcd,以查看其应该运行的 Pod。
整个 k8s 系统的设计使故障对整个群集的影响降低到最小。例如,如果我们的主节点宕机,我们的应用程序不会立即受到影响。在新的主节点上线之前,我们将无法对集群进行任何进一步的更改。
什么时候不应该使用 k8s
与每项新技术一样,学习、了解了 k8s 如何工作,以及它如何应用于你正在构建的应用程序时,你将承担采用它的间接成本。就会引发一个很合理的问题:我真的需要 k8s 吗?所以我列出一些不需要使用 k8s 的场景。
- 只需要一台机器就能运行的你的应用程序(k8s 可以被视为构建分布式系统的平台,但是,如果你的应用程序不需要分布式系统,就不应该构建分布式系统)
- 你的应用程序计算需求是轻量的(在这种情况下,花在 k8s 上的计算量相对较高)
- 你的应用程序不需要高可靠性,能够容忍停机
- 你不会设想对部署的服务进行大量更改
- 你已经有了一个你满意的并且有效的工具集合
- 你的应用程序是一个整体,并不打算把它拆分成微服务
- 你读完这篇文章后,认为 k8s 是「该死的,真复杂」而不是「该死的,真有用」
致谢
感谢 Derek Whatley 和 Devon Kinghorn 在我学习 k8s 时,教授了我关于 k8s 的大部分知识并回答了我的问题,当我一直在努力研究这项技术时。感谢 Goku Mohandas、John Huffman、Dan Salo 和 Zack Abzug 花时间审阅本文的早期版本,并提供了非常有用的反馈。最后,我需要感谢 Kelsey Hightower 为 k8s 社区所做出的一切,他的演讲帮助我更全面了解 k8s 并给予我信心去学习 k8s。
资源
下面是一些我在学习 k8s 时发现很有用的资源。
博客
- Julia Evans - Reasons Kubernetes is cool
- Julia Evans - A few things I’ve learned about Kubernetes
- Jessie Frazelle - You might not need Kubernetes
- Matt Rogish - Is Kubernetes Overkill?
- Major Trends in the 2019 Data & AI Landscape
- Introduction to cloud-native applications 和 defining cloud native
视频
- Kelsey Hightower - Kuberenetes for Pythonistas discusses the motivation for Kubernetes and provides an example of running a Python application.
- Kubernetes by Kelsey Hightower introduces the core components of Kubernetes and how they work together, with the API server at the core.
- Kubernetes The Easy Way! presents a developer-centric workflow for building products and leveraging Kubernetes as the infrastructure.
- Kubernetes in Real Life - Ian Crosby
- Kubernetes Design Principles: Understand the Why - Saad Ali, Google
- Kubernetes Deconstructed: Understanding Kubernetes by Breaking It Down - Carson Anderson, DOMO
- From COBOL to Kubernetes: A 250 Year Old Bank’s Cloud-Native Journey - Laura Rehorst
书籍
本篇文章来源于知乎:https://zhuanlan.zhihu.com/p/374497528
微信扫描下方的二维码阅读本文

Comments NOTHING