文章目录
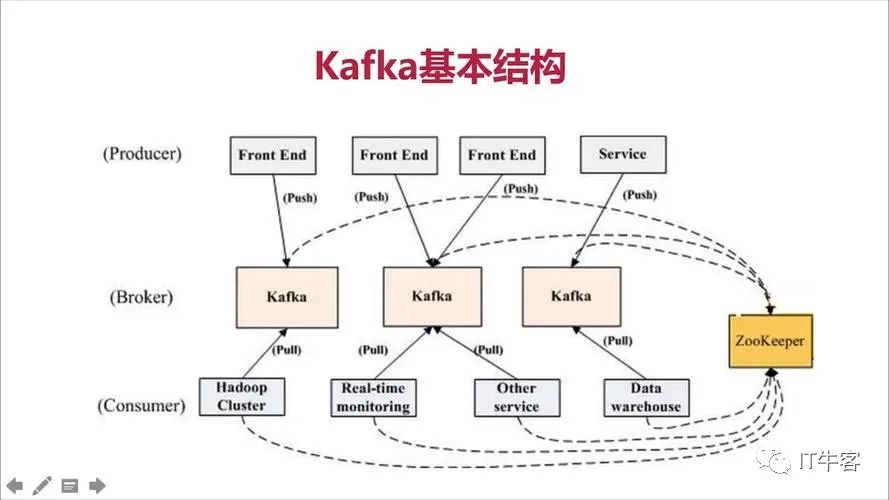 一、kafka API简介
一、kafka API简介
二、引入kafka java客户端依赖
要使用Producer、Consumer和AdminClient,你可以使用以下 maven 依赖项:
<dependency><groupId>org.apache.kafka</groupId><artifactId>kafka-clients</artifactId><version>3.4.0</version></dependency>
三、发送消息
kafka封装了一套二进制通信协议,用于对外提供各种各样的服务,对于producer而言,用户可以使用任意编程语言按照该协议的格式进行编程,从而实现向kafka发送消息。这组协议本质上为不同的协议类型分别定义了专属的紧凑二进制字节数组格式,然后通过socket发送给合适的broker,之后等待broker处理完成后返还响应给producer。
每个producer都是独立进行工作的,与其他producer之间没有关联,目前producer的首要功能就是向某个topic的某个分区发送一条消息,所以它首先需要确认到底向topic的哪个分区写入消息,这就是分区器(partitioner)的事情。kafka producer提供了一个默认的分区器,对于每条待发送的消息,如果该消息指定了key,那么该partitioner会根据key的哈希值来选择目标分区,若没有,会使用轮询的方式确认目标分区。当然,producer的API赋予了用户自行指定目标分区的权力。
在确认了目标分区后,producer要做的第二件事就是要寻找这个分区对应的leader,只有leader才能响应客户端发送过来的请求,而剩下的从节点中有一部分会同步该消息。因此在发送消息时,producer有不等待任何副本的响应便返回成功,或者只等待leader响应写入操作之后再返回成功。
Java版本producer工作流程:
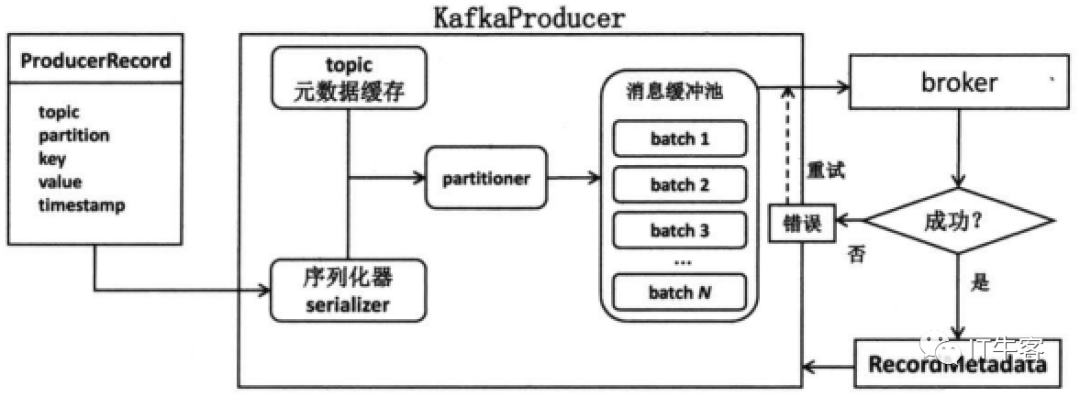
生产者代码演示:
import java.util.Properties;import org.apache.kafka.clients.CommonClientConfigs;import org.apache.kafka.clients.producer.Callback;import org.apache.kafka.clients.producer.KafkaProducer;import org.apache.kafka.clients.producer.Producer;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.clients.producer.ProducerRecord;import org.apache.kafka.clients.producer.RecordMetadata;import org.apache.kafka.common.config.SaslConfigs;import org.apache.kafka.common.serialization.StringSerializer;/*** kafka生产** @author dong.zhao* @date 2023/02/09 14:06**/public class ProducerTest {public static void main(String[] args) {Properties props = new Properties();// serverprops.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");// 被发送到broker的任何消息的格式都必须是字节数组props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());// 非必须参数配置// acks=0表明producer完全不管发送结果;// acks=all或-1表明producer会等待ISR所有节点均写入后的响应结果;// acks=1,表明producer会等待leader写入后的响应结果props.put(ProducerConfig.ACKS_CONFIG, "-1");// 发生可重试异常时的重试次数props.put(ProducerConfig.RETRIES_CONFIG, 3);// producer会将发往同一分区的多条消息封装进一个batch中,// 当batch满了的时候,发送其中的所有消息,不过并不总是等待batch满了才发送消息;props.put(ProducerConfig.BATCH_SIZE_CONFIG, 323840);// 控制消息发送延时,默认为0,即立即发送,无需关心batch是否已被填满。props.put(ProducerConfig.LINGER_MS_CONFIG, 1);// 指定了producer用于缓存消息的缓冲区大小,单位字节,默认32MB// producer启动时会首先创建一块内存缓冲区用于保存待发送的消息,然后由另一个专属线程负责从缓冲区中读取消息执行真正的发送props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);// 设置producer能发送的最大消息大小props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);// 设置是否压缩消息,默认noneprops.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "lz4");// 设置消息发送后,等待响应的最大时间,默认30秒props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 30);// 是否开启认证boolean auth = false;if (auth) {String userName = "admin";String password = "123456";// 设置SASL连接props.put(CommonClientConfigs.SECURITY_PROTOCOL_CONFIG, "SASL_PLAINTEXT");props.put(SaslConfigs.SASL_MECHANISM, "PLAIN");props.put(SaslConfigs.SASL_JAAS_CONFIG,"org.apache.kafka.common.security.plain.PlainLoginModule required username="" + userName+ "" password="" + password + "";");}Producer<String, String> producer = new KafkaProducer<>(props);String data ="{"account":"账号","taskId":"任务ID","data":[{"service":"服务","type":"类型","cycle":"计费周期","cost":[{"cpu":"4","gpu":"1","memory":"32"},{"cpu":"4","gpu":"1","memory":""}]}]}";// 直接发送,即发送之后便不再理会发送结果,这种方式在实际中是不被推荐使用的。// producer.send(new ProducerRecord<>("test", "key", data));// 异步发送producer.send(new ProducerRecord<>("test-topic", uuid, data), new Callback() {public void onCompletion(RecordMetadata metadata, Exception exception) {if (exception == null) {System.out.println("消息发送成功");} else {System.out.println("消息发送失败" + exception);}}});// 同步发送// ProducerRecord<String, String> record = new ProducerRecord<>("my-replicated-topic", "key", data);// RecordMetadata recordMetadata = producer.send(record).get();producer.close();}}
kafka producer发送消息的主方法是send方法,在底层完全地实现了异步化发送,并且通过Java提供的Future同时实现了同步发送和异步发送+回调两种发送方式。而上述代码使用的是第三种方式,即发送之后便不再理会发送结果,这种方式在实际中是不被推荐使用的。
异步发送:
实际上所有的写入操作默认都是异步的,send方法会返回一个Java Future对象供用户稍后获取发送结果,这就是所谓的回调机制。具体代码如下:
producer.send(record,new Callback(){@Overridepublic void onCompletion(RecordMetadata metadata,Exception exception){if(exception == null){System.out.println("消息发送成功");} else {System.out.println("消息发送失败");}}});
上面的代码中,Callback就是发送消息后的回调类,其onCompletion方法的两个输入参数metadata和exception不会同时非空,当消息发送成功时,exception为null,当消息发送失败时,metadata就是null。Callback实际上是一个Java接口,因此可创建自定义的Callback实现类来处理消息发送后的逻辑。
同步发送:
同步发送和异步发送其实就是通过Java的Future来区分的,调用Future.get()等待返回结果,即是同步发送,具体代码如下:
ProducerRecord<String, String> record = new ProducerRecord<>("test-topic",uuid,data);RecordMetadata recordMetadata = producer.send(record).get();
使用Future.get()方法会一直等待下去直到broker将结果返回给producer程序,当结果返回时,get()方法要么返回发送结果,要么抛出异常交由producer自行处理。如果没有错误,get将返回对应的RecordMetadata实例。
kafka发送异常
当前kafka的错误类型包含了两类:可重试异常和不可重试异常,常见的可重试异常如下:
所有可重试的异常都继承自or.apache.kafka.common.errors.RetriableException,对于这些可重试的异常,如果在producer程序中配置了重试次数,那么只要在规定的重试次数内自行恢复了,便不会出现在onCompletion的exception中。若超过了重试次数仍没成功,就会被封装到exception中,此时就需要producer程序自行处理这种异常。
没有继承自RetriableException的其他异常都属于不可重试异常,这类异常表明了一些非常严重或kafka无法处理的问题。
四、消息分区机制
producer发送过程中需要确定将消息发送到topic的哪一个分区,默认的分区器会尽力确保具有相同key的所有消息都被发送到相同的分区上;若没有指定key,会以轮询的方式来确保消息在topic的分区上均匀分配。
1、自定义分区机制
自定义分区器需要实现org.apache.kafka.clients.producer.Partitioner接口,分区逻辑写在partition()方法中,例如:
public class AuditPartitioner implements Partitioner {private Random random;public void configure(Map<String, ?> map) {// 该方法实现必要资源的初始化工作random = new Random();}public int partition(String topic, Object keyObj, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {String key = (String)keyObj;// 获取该topic可用的所有分区List<PartitionInfo> partitionInfoList = cluster.availablePartitionsForTopic(topic);int partitionCount = partitionInfoList.size();int auditPartition = partitionCount -1;return key == null || !key.contains("audit") ? random.nextInt(auditPartition) : auditPartition;}public void close() {// 该方法实现必要资源的清理}}
使用自定义分区器:
props.put("partitioner.class","xx.xx.AuditPartitioner");五、消息序列化
1、自定义序列化器
public class User{private String firstName;private String lastName;private int age;private String address;public User(String firstName,String lastName,int age,String address){this.firstName=firstName;this.lastName=lastName;this.age=age;this.address=address;}}
由于要用jackson-mapper-asl包中的ObjectMapper来将对象转成字节数组,因此需要将其依赖引入:
<dependency><groupId>org.codehaus.jackson</groupId><artifactId>jackson-mapper-asl</artifactId><version>1.9.13</version></dependency>
接下来创建serializer
public class UserSerializer implements Serializer{private ObjectMapper objectMapper;public void configure(Map config,boolean isKey){objectMapper = new ObjectMapper();}public byte[] serialize(String topic,Object data){byte[] res = null;try{res = objectMapper.writeValueAsString(data).getBytes("utf-8");}catch(Exception e){logger.warn("failed to serialize the object: {}", data, e);}return res;}public void close(){}}
使用自定义序列化器:
props.put("value.serializer","xx.xx.UserSerializer");六、producer拦截器
producer拦截器使得用户在消息发送前和producer回调逻辑执行前可对消息做一些定制化处理,允许使用多个拦截器构成拦截器链。拦截器的实现接口是org.apache.kafka.clients.producer.ProducerInterceptor。interceptor可能运行在多个线程中,因此在具体实现时用户需要确保线程安全。下面以一个简单的双interceptor组成的拦截链为例。第一个interceptor会在消息发送前将时间戳信息加到消息value的最前部,第二个interceptor会在消息发送后更新成功发送消息或失败发送消息数。
public class TimeStampPrependerInterceptor implements ProducerInterceptor<String,String> {/*** producer确保在消息被序列化前调用该方法* 可以在该方法中对消息做任何操作*/public ProducerRecord onSend(ProducerRecord record) {return new ProducerRecord(record.topic(),record.partition(),record.timestamp(),record.key(),System.currentTimeMillis() +","+record.value().toString());}/*** 该方法会在消息被应答之前或消息发送时调用*/public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {}public void close() {}public void configure(Map<String, ?> map) {}}
public class CounterInterceptor implements ProducerInterceptor<String,String> {private int errorCounter = 0;private int successCounter = 0;public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {return record;}public void onAcknowledgement(RecordMetadata recordMetadata, Exception e) {if (e == null) {successCounter++;}else{errorCounter++;}}public void close() {System.out.println("Successful sent: " + successCounter);System.out.println("Failed sent: " + errorCounter);}public void configure(Map<String, ?> map) {}}
List<String> interceptors = new ArrayList<>();interceptors.add("xx.xx.TimeStampPrependerInterceptor");interceptors.add("xx.xx.CounterInterceptor");props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,interceptors);
七、消息的可靠发送
1、无消息丢失配置
2、附录:消费者代码演示:
import java.time.Duration;import java.util.Collections;import java.util.Properties;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.clients.consumer.ConsumerRecord;import org.apache.kafka.clients.consumer.ConsumerRecords;import org.apache.kafka.clients.consumer.KafkaConsumer;import org.apache.kafka.common.serialization.StringDeserializer;/*** kafka消费者** @author dong.zhao* @date 2023/02/10 17:53**/public class ConsumerTest {private static final String TOPIC_NAME = "sothisai";private static final String CONSUMER_GROUP_NAME = "testGroup";public static void main(String[] args) {Properties properties = new Properties();properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9092");// 消费分组名properties.put(ConsumerConfig.GROUP_ID_CONFIG, CONSUMER_GROUP_NAME);// earliest:offset偏移至最早时候开始消费;latest:偏移到从最新开始消费(默认)properties.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");// 设置序列化properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());// 创建一个消费者的客户端KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);// 消费者订阅主题列表// KafkaConsumer.subscribe():为consumer自动分配partition,有内部算法保证topic-partition以最优的方式均匀分配给同group下的不同consumer。// KafkaConsumer.assign():为consumer手动、显示的指定需要消费的topic-partitions,不受group.id限制。consumer.subscribe(Collections.singletonList(TOPIC_NAME));// // A.设置要订阅的topic 列表// List<TopicPartition> topicPartitions = new ArrayList<>();// topicPartitions.add(new TopicPartition(TOPIC_NAME, 0));// consumer.assign(topicPartitions);while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(2000));for (ConsumerRecord<String, String> record : records) {System.out.printf("收到的消息:partition= %d,offset= %d,key= %s,value=%s %n", record.partition(),record.offset(), record.key(), record.value());}}}}
·END·
本篇文章来源于微信公众号: IT牛客
微信扫描下方的二维码阅读本文

Comments NOTHING