Redis数据类型是面试官喜欢问的项目之一,也是Redis面试八股文中必须熟练掌握的知识点。相信大部分人都知道Redis有五大基本数据类型,但是它们使用场景有哪些、分别是怎么实现的呢?Redis还有几种数据类型,你能答出来让面试官眼前一亮么?
面试官都喜欢用不断深入追问的方式,来看候选人到底对一个知识点的掌握程度如何,如果面试官想探你的“底”,往往会发出一连串的追问?除了上述问题,可能还会问Zset(Sorted Set)为什么要用跳表、不用平衡树/二叉树/B+树来实现呢?
下面让我们来一起探讨下这些题目的参考回答,让你真正面对这些问题时,能够得心应手。
Redis数据类型及其使用场景、实现方式(底层数据结构)
Redis 提供了以下五种基本数据类型:
1、String(字符串)
(1)使用场景:
-
存储单个值,如用户信息、商品详情等简单文本或二进制数据。
-
作为计数器,实现递增/递减操作,如统计网页访问次数、库存数量等。
-
作为分布式锁的实现基础,利用其原子性操作保障并发安全。
-
共享Session信息,多个服务都从同一Redis查询Session信息,判断用户是否登录。
(2)实现方式:
Redis 中的 String 采用简单动态字符串(SDS)实现,SDS 不仅可以保存文本数据,还可以保存二进制数据,拼接字符串之前会检查 SDS 空间是否满足要求,如果空间不够会自动扩容,所以不会导致缓冲区溢出的问题。根据保存对象长短,编码方式(encoding)不同[1],如下图所示:
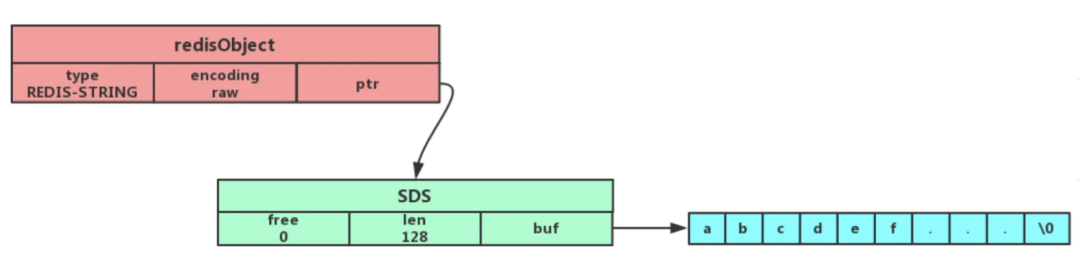
2、Hash(哈希)
(1)使用场景:
-
存储对象或结构化的数据,如用户资料、商品属性等,通过 field-value 形式组织,便于快速访问和更新单个属性。
-
用作缓存,将关系型数据库中的一行记录完整地存储为一个哈希。
(2)实现方式:
-
Redis Hash 采用压缩列表(ziplist)或哈希表(hashtable)两种底层数据结构实现。当哈希元素数量较少且元素值较小(默认512个)的情况下,使用压缩列表以节约空间;随着元素数量增长或值大小超过阈值,自动转换为哈希表以保证操作性能。
-
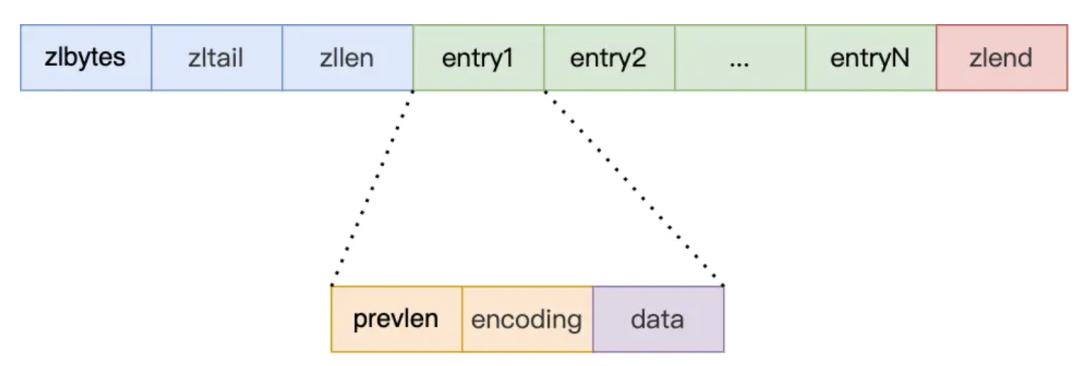
压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据。和数组不同的是,压缩列表在表头有三个字段 zlbytes、zltail 和 zllen,分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。缺点:插入大元素容易引发后面元素的prevlen字段的连锁更新、占用空间调整等。压缩列表结构如下图所示:

-
在 Redis 7.0中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。listpack结构如下图[3]:
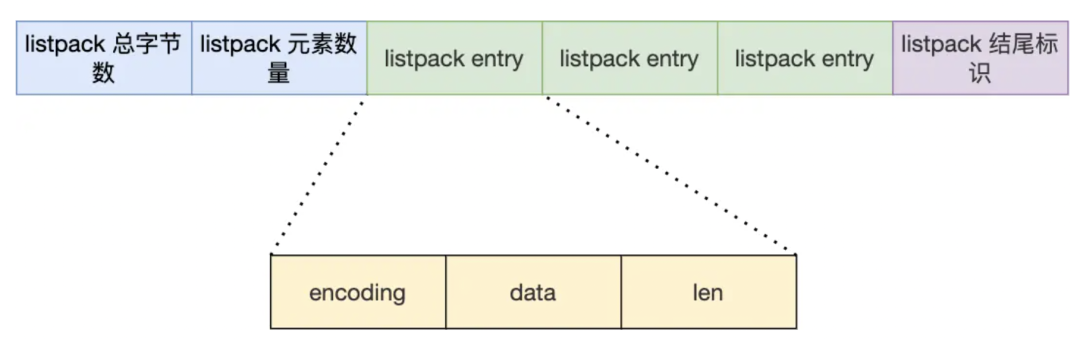
3、List(列表)
(1)使用场景:
-
实现队列或栈功能,如任务队列、消息队列等,通过 LPUSH/RPOP 或 RPUSH/LPOP 操作实现先进先出(FIFO)或后进先出(LIFO)。
-
时间序列数据的存储,如用户浏览历史、日志记录等,利用列表的有序性。
(2)实现方式:
-
Redis List 可以选择使用双端链表(linked list)或压缩列表(ziplist)作为底层实现。对于元素数量较少或元素值较小的列表(默认512个),使用压缩列表以节省内存;当元素数量增长或值大小超过设定阈值时,自动转为双端链表以保证快速地插入和删除操作。
-
在 Redis 3.2 版本之后,List 数据类型底层数据结构就只由 quicklist 实现了,替代了双向链表和压缩列表。如下图所示[3]:
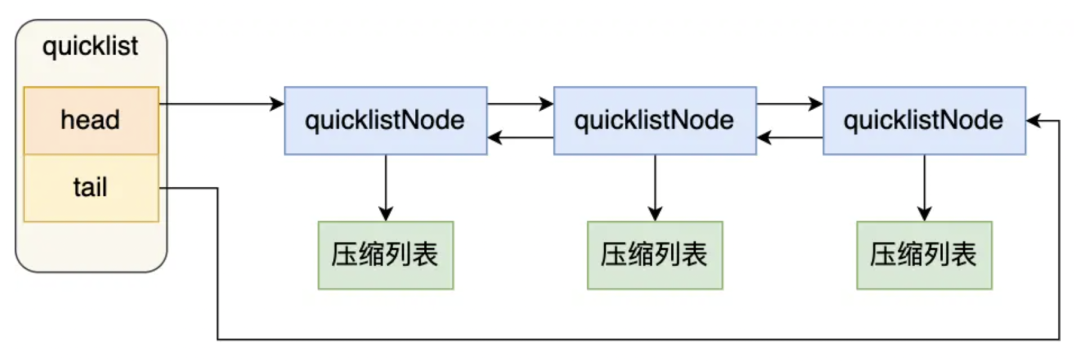
4、Set(集合)
(1)使用场景:
-
存储唯一值集合,如标签系统中的用户标签、社交网络中的关注关系等。
-
实现交集、并集、差集等集合运算,如共同关注、推荐好友等。
(2)实现方式:
-
Redis Set 使用整数集合(int set)或哈希表(hashtable)实现。当集合元素全部为整数且范围合适时,使用整数集合以节省空间;否则使用哈希表来保证唯一性和快速增删查操作。
5、ZSet(有序集合)
(1)使用场景:
-
排行榜系统,如用户积分排名、热门文章等,根据分数(score)对成员(member)进行排序。
-
时间窗口内事件计数,如最近活跃用户、按时间排序的日志记录等,score 作为时间戳或其他排序依据。
-
地理位置服务,利用经纬度作为 score,对地点进行范围查询和排序。
(2)实现方式:
-
Redis ZSet 采用跳跃表(skiplist)和字典(dict)相结合的方式实现。跳跃表提供有序性,通过多层索引结构实现快速的范围查询和排序;字典则用于确保成员的唯一性。每个成员在跳跃表和字典中各有一份拷贝,以兼顾排序和唯一性检查。
-
跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位,如下图所示:
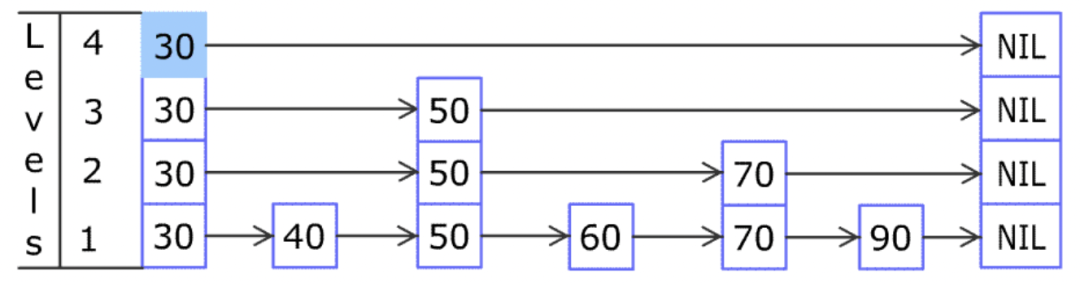
-
在 Redis 7.0中,压缩列表数据结构已经废弃了,交由 listpack 数据结构来实现了。
实现方式总体如图所示[2]:
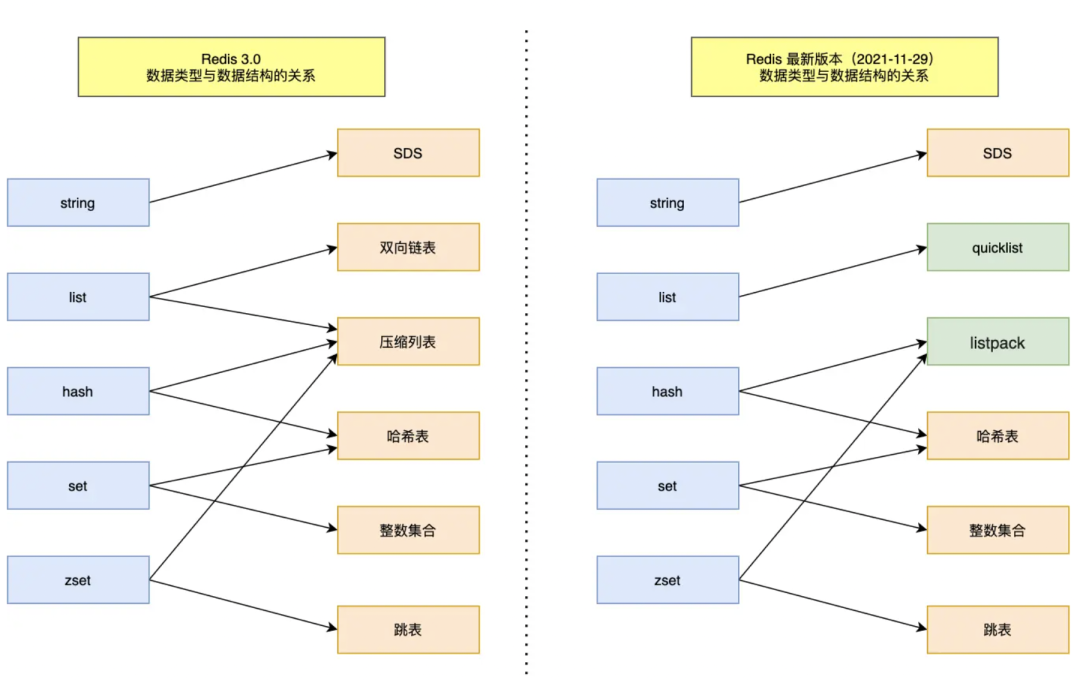
Redis还有哪些数据类型?
如果你想让面试官眼前一亮,除了上述五种基本数据类型外,还可以回答,Redis 还提供了以下几种特殊数据类型,进一步扩展了其应用场景和功能:
1、Bitmaps(位图)
(1)使用场景:
-
适用于需要对大量二进制位进行高效操作的场景,如用户签到、活跃用户统计等。
-
空间高效的存储布尔状态或标志位,如用户是否已读某条消息、某个商品是否有库存等。
(2)实现方式:
-
Bitmaps 在 Redis 中实际上是 String 类型的一种特殊应用。通常将一个大整数看作一系列连续的位,每个位代表一个独立的状态。Redis 提供了一系列针对位的操作命令,如 SETBIT、GETBIT、BITCOUNT 等,使得用户能够以极低的空间成本(每个位仅占用 1 bit)对大量二进制位进行快速的设置、获取与统计。
2、HyperLogLog(基数估计算法)
(1)使用场景:
-
用于近似统计大量唯一元素的数量,如网站独立访客数、唯一用户 ID 计数等,无需精确计数但对内存占用敏感的场景。
(2)实现方式:
-
HyperLogLog 是一种概率算法,能在小内存空间内(通常几十到几百字节)提供对大规模数据集基数(不重复元素数量)的估算。Redis 将 HyperLogLog 算法实现为一种数据类型,提供 PFADD、PFCOUNT 等命令,允许用户向 HyperLogLog 结构添加元素,并获取估算的基数,误差率通常在0.81%以内,精确计数时不能使用。
3、Geo(地理位置)
(1)使用场景:
-
适用于需要对带有地理位置信息的数据进行距离查询、范围查询、附近点查找等操作的场景,如地图服务、LBS 应用、社交网络中基于位置的好友推荐等。
(2)实现方式:
-
Redis 的 Geo 数据类型基于 ZSet 实现,通过将经纬度信息转换为分值,结合专用的地理空间操作命令(如 GEOADD、GEODIST、GEORADIUS、GEORADIUSBYMEMBER),实现了对地理位置数据的高效管理和查询。用户可以轻松地添加、删除地理位置信息,以及根据给定坐标或距离范围进行查询。
4、Streams(流)
(1)使用场景:
-
适用于处理持续追加的事件序列,如消息队列、活动日志、物联网设备数据流等,支持持久化存储、多消费者消费、消息分片等复杂需求。
(2)实现方式:
-
Redis Streams 是一种逻辑上类似于发布-订阅模式,但具有更强持久化、多消费组、消息回溯等特点的数据类型。每个 Stream 由一系列带有唯一 ID 和元数据(时间戳、字段值等)的消息组成。Redis 提供 XADD、XREAD、XGROUP 等命令,支持客户端以高并发、低延迟的方式生成、消费和管理数据流。
5、RedisObject(自定义数据类型)
(1)使用场景:
-
RedisObject 是一种更为抽象和灵活的数据类型概念,它涵盖了 Redis 中所有基本数据类型以及特殊数据类型的实现。在实际应用中,开发者并不直接操作 RedisObject,而是通过使用 Redis 提供的各种数据类型命令与之交互。RedisObject 作为 Redis 内部的核心数据结构,为不同数据类型的特性和操作提供了统一的封装和管理。
-
在高级开发和定制化需求中,RedisObject 的存在为扩展 Redis 功能、实现特定业务逻辑或集成第三方模块提供了可能。例如,通过编写自定义 Redis 模块,开发者可以创建新的数据类型,结合 Redis 的高性能特性实现特定领域的高效数据存储和处理解决方案。
(2)实现方式:
RedisObject 结构包含了以下几个关键部分:
a.type:表示该对象的实际类型,如 STRING、LIST、HASH、SET、ZSET、BITMAPS、HYPERLOGLOG、GEO 或自定义类型。
b.encoding:表示对象内部数据的编码方式,如整数、压缩列表、双端链表、哈希表、跳跃表、整数集合、字典等。不同的数据类型和使用场景下,Redis 会根据数据量、元素分布等因素动态选择最合适的编码,以平衡内存占用和操作性能。
c.ptr:指向实际数据存储区域的指针。根据type和encoding,该指针可能指向不同类型和编码的具体数据结构。
d. 其他属性和元数据,如过期时间(TTL)、引用计数(用于复制、AOF/RDB 持久化等场景)等。
RedisObject 的设计使得 Redis 能够以高度统一且灵活的方式处理各种数据类型。当客户端执行相关命令时,Redis 会根据命令参数和目标对象的类型与编码,调用相应的内部函数进行操作。这种设计不仅简化了 Redis 内部的代码组织和维护,也使得 Redis 能够在不牺牲性能的前提下,轻松支持新的数据类型和功能扩展。
总结
Redis 提供了丰富多样的数据类型,包括 String、Hash、List、Set、ZSet 五种基本数据类型,以及 Bitmaps、HyperLogLog、Geo、Streams 四种特殊数据类型。这些数据类型覆盖了多种常见应用场景,如缓存、队列、排行榜、计数器、唯一值集合、地理位置服务、基数估算、位图操作、事件流处理等。而作为 Redis 内部核心数据结构的 RedisObject,则为这些数据类型的统一管理、动态编码选择以及功能扩展提供了坚实的基础。通过合理选择和运用这些数据类型,开发者能够充分发挥 Redis 的高性能、低延迟特性,构建高效、可扩展的应用系统。
为何 ZSet 不使用二叉树/红黑树/B+树实现?
尽管 B+树是一种常用于数据库系统中实现有序数据存储的数据结构,具有良好的查询性能和较高的空间利用率,但 Redis 在设计 ZSet 时选择使用跳跃表而非 B+树,主要原因可能包括:
-
范围查询性能:
-
跳跃表的层次化索引结构使得它能够快速进行范围查询,无需像 B+树那样需要从根节点逐层遍历到叶子节点。尤其是在处理大量范围查询的场景(如排行榜分页展示、地理坐标范围检索)时,跳跃表的优势更为明显。
-
内存使用:
-
可以有效地控制跳表的索引层级,来控制内存的消耗,Redis是直接操作内存的并不需要磁盘IO,而MySQL需要去读取IO,所以MySQL要使用B+树的方式减少磁盘IO(B+树的原理是叶子节点存储数据,非叶子节点存储索引,每次读取磁盘页时就会读取一整个节点,每个叶子节点还有指向前后节点的指针,为的是最大限度地降低磁盘的IO)。
-
二叉树/红黑树层级较高,内存占用大;B+树的空间利用率较高,但其节点间复杂的指针结构可能导致内存分配不连续,从而增加内存占用。
-
简单性与实现成本:
-
跳跃表是一种相对简单的数据结构,其逻辑清晰、易于实现和维护。相比之下,B+树的实现较为复杂,涉及到节点分裂、合并等操作,对于追求简洁高效的 Redis 来说,跳跃表是更轻量级的选择。
-
高效插入与删除:
-
跳跃表支持在 O(logN)时间复杂度内完成插入、删除和查找操作,与 B+树相当。但在实际应用中,跳跃表的插入和删除操作通常能更快地完成,因为它不需要像 B+树那样频繁调整节点之间的指针关系。
综上所述,Redis 选择跳跃表而非 B+树来实现 ZSet,主要是出于良好范围查询性能、内存使用效率、简单性、以及高效操作的考虑。这种设计选择在实践中已被证明能够很好地满足 Redis 应用场景的需求,特别是在高并发、低延迟的环境中表现出色。
参考:
[1]https://xiaolincoding.com/redis/data_struct/command.html
[2]https://xiaolincoding.com/redis/base/redis_interview.html
[3]https://xiaolincoding.com/redis/data_struct/data_struct.html
点击关注我,交个朋友吧!
本篇文章来源于微信公众号: 程序员Aike
微信扫描下方的二维码阅读本文

Comments NOTHING