尼恩说在前面
在40岁老架构师 尼恩的读者交流群(50+)中,最近有小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团、蚂蚁、得物的面试资格,遇到很多很重要的相关面试题:
说说:蚂蚁面试:Springcloud核心组件的底层原理,你知道多少?越多越好。
说说:Springcloud 生态的基础组件的底层原理?
最近有小伙伴在面试蚂蚁,问到了相关的面试题,可以说是逢面必问。
小伙伴没有系统的去梳理和总结,所以支支吾吾的说了几句,面试官不满意,面试挂了。
所以,尼恩给大家做一下系统化、体系化的梳理,使得大家内力猛增,可以充分展示一下大家雄厚的 “技术肌肉”,让面试官爱到 “不能自已、口水直流”,然后实现”offer直提”。
当然,这道面试题,以及参考答案,也会收入咱们的 《尼恩Java面试宝典PDF》V175版本,供后面的小伙伴参考,提升大家的 3高 架构、设计、开发水平。
《尼恩 架构笔记》《尼恩高并发三部曲》《尼恩Java面试宝典》的PDF,请到文末公号【技术自由圈】获取
本文目录
- 尼恩说在前面
-总结: Springcloud体系的几个核心组件
-Nacos 注册中心的底层原理
-AP 模式的 Distro 分布式协议
-CP 模式的 Raft 分布式协议
-Raft算法选主流程
-1.基础概念之 Term 任期
-2.基础概念之 Log Entry 日志条目
-3.基础概念之 RPC
-Raft 选举流程(Election)
-投票选举流程图解
-Raft 日志复制
-Leader Append-Only 原则
-Log Matching 特性
-强制复制
-解决冲突的性能优化
-Nacos 如何实现Raft算法
-启动选举
-选举流程
-心跳机制
-sentinel高可用组件的底层原理
-Sentinel熔断降级,是如何实现的?
-第一个维度,Sentinel主要功能:
-第二个维度, Sentinel 的基本组件:
-第三个维度, Sentinel 的流量治理几个核心步骤:
-第四个维度, Sentinel 的源码架构维度:
-Sentinel 的源码层面的两个核心架构:
-滑动窗口的核心数据结构
-ArrayMetric 源码
-LeapArray 源码
-MetricBucket 源码
-WindowWrap 源码
-loadbanlancer负载均衡组件的底层原理
-基础原理:负载均衡的类型
-基础原理:常见的负载均衡算法的实现
-随机(Random)负载均衡算法的实现
-轮询(Round Robin、RR)负载均衡算法的实现
-加权轮询(WeightedRound-Robin、WRR)负载均衡算法的实现
-SpringCloud 整合LoadBalancer 负载均衡
-Ribbon负载均衡组件
-Ribbon重要接口
-Ribbon负载均衡规则
-LoadBalancer 负载均衡组件
-OpenFeign + LoadBalancer所需依赖
-OpenFeign + LoadBalancer所需配置
-OpenFeign + LoadBalancer所需注解
-OpenFeign + LoadBalancer 的演示
-LoadBalancer自定义负载均衡策略
-LoadBalancer基于Nacos权重自定义负载算法
-通过nacos配置 权重
-基于nacos权重实现自定义负载
-配置使用自定义负载均衡器
-说在最后:有问题找老架构取经
总结: Springcloud体系的几个核心组件
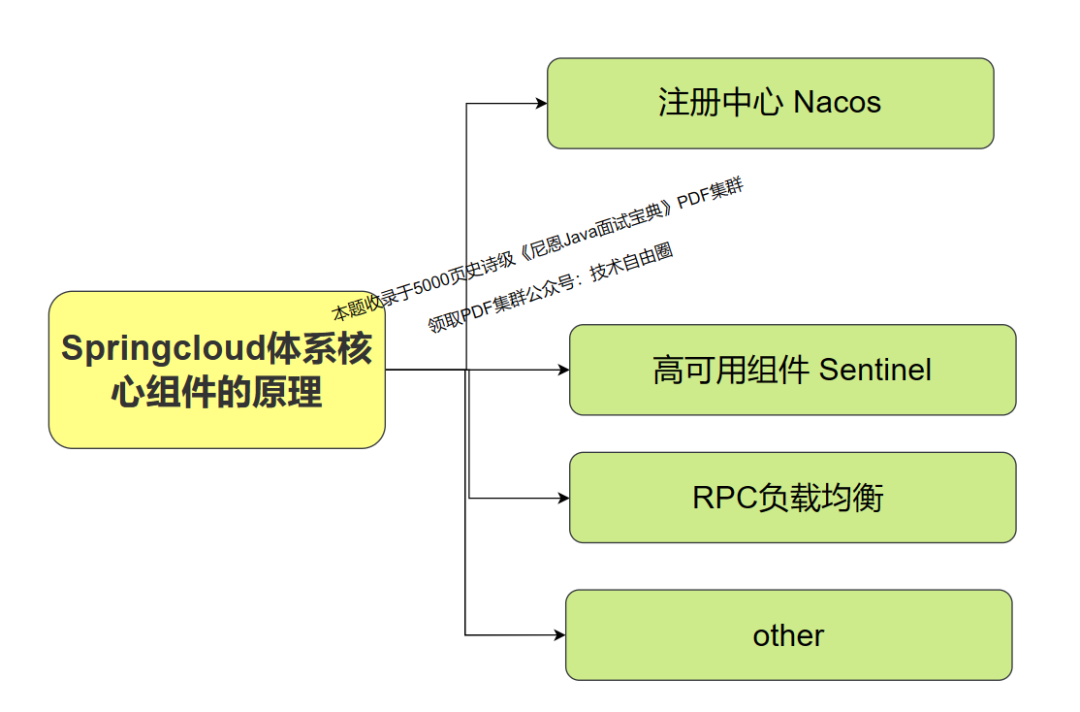
Nacos 注册中心的底层原理
-
如果注册到Nacos的client节点注册时ephemeral=true,那么Nacos集群对这个client节点的效果就是AP,采用distro协议实现; -
而注册Nacos的client节点注册时ephemeral=false,那么Nacos集群对这个节点的效果就是CP的,采用raft协议实现。
AP 模式的 Distro 分布式协议
-
每个节点是平等的都可以处理写请求,同时将新数据同步至其他节点。 -
每个节点只负责部分数据,定时发送自己负责数据的校验值,到其他节点来保持数据⼀致性。 -
每个节点独立处理读请求,并及时从本地发出响应。
CP 模式的 Raft 分布式协议
-
Leader:负责Client交互和log复制,同一时刻系统中最多存在1个。 -
Follower:被动响应请求RPC,从不主动发起请求RPC。 -
Candidate:一种临时的角色,只存在于leader的选举阶段,某个节点想要变成leader,那么就发起投票请求,同时自己变成candidate。如果选举成功,则变为candidate,否则退回为follower
-
领导选举 -
日志复制 -
安全和成员变化。
-
日志:每台机器都保存一份日志,日志来源于客户端的请求,包含一系列的命令。 -
状态机:状态机会按顺序执行这些命令。 -
一致性模型:在分布式环境中,确保多台机器的日志保持一致,从而使状态机回放时的状态保持一致。
Raft算法选主流程
-
Leader:负责日志的同步管理,处理来自客户端的请求,与Follower保持heartBeat的联系; -
Follower:刚启动时所有节点为Follower状态。响应Candidate的请求,选举完成后它的责任是响应Leader的日志同步请求,把请求到Follower的事务转发给Leader; -
Candidate:负责选举投票,一轮选举开始时节点从Follower转为Candidate发起选举,选举出Leader后从Candidate转为Leader状态;
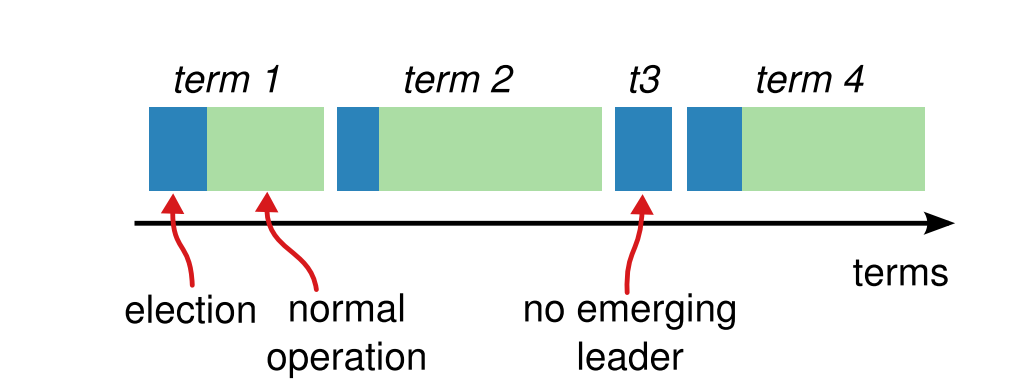
1.基础概念之 Term 任期
-
选举阶段 -
正常阶段。
2.基础概念之 Log Entry 日志条目
-
term Leader收到log时的term -
index log下标。log存储结构是一个List -
command 操作指令
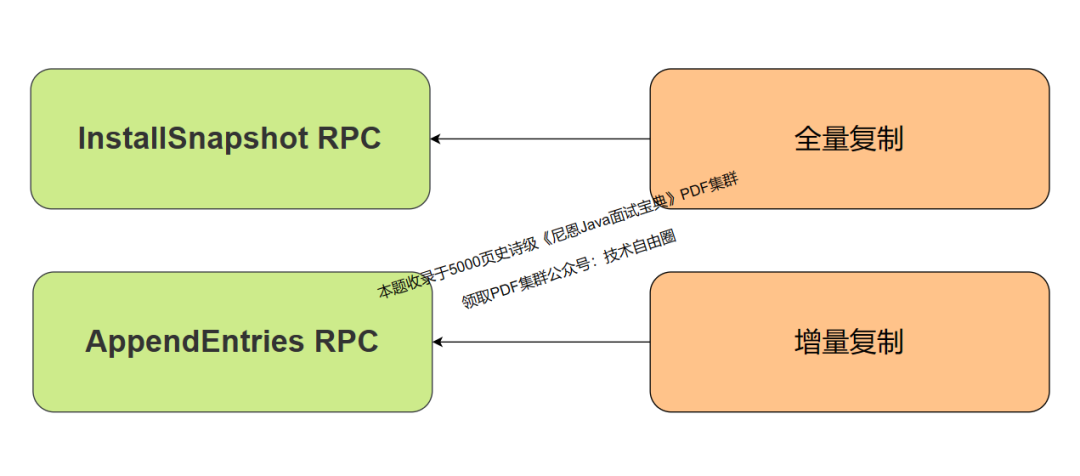
3.基础概念之 RPC
-
RequestVote RPC:候选人在选举期间发起 -
AppendEntries RPC:领导人发起的一种心跳机制,复制日志也在该命令中完成 -
InstallSnapshot RPC:领导者使用该RPC来发送快照给太落后的追随者
-
节点发送 RequestVote 请求给其他节点,请求它们投票支持自己成为领导者。 -
其他节点收到请求后,会根据自己的选举算法判断是否给予支持。 -
如果其他节点认为该节点可以成为领导者,就会向其发送投票,并更新自己的状态以反映投票结果。 -
请求节点收到足够多的投票后,就可以成为领导者,并开始执行相应的操作。
-
请求节点的ID:用于标识请求的发起者。 -
请求的任期号:用于确保只有最新的领导者才能获得其他节点的投票。 -
候选人的最后日志条目的索引和任期号:用于其他节点判断候选人的日志是否比自己的日志更新,从而决定是否给予投票支持。 -
投票结果:表示其他节点是否投票支持候选人成为领导者。
-
领导者节点将自己的日志条目以 AppendEntries 请求的形式发送给其他节点。 -
其他节点收到请求后,会根据领导者的日志条目信息进行处理,将日志条目追加到自己的日志中。 -
如果其他节点的日志中存在与领导者发送的日志冲突的条目,节点会根据一定的规则进行日志的比较和冲突解决。 -
处理完请求后,其他节点会向领导者发送响应,表示是否成功追加日志条目。
-
领导者的ID:用于标识发送请求的节点。 -
领导者的任期号:用于确保其他节点只接受来自最新领导者的日志复制请求。 -
领导者的日志条目:包括日志条目的索引、任期号以及具体的日志内容。 -
领导者的前一条日志条目的索引和任期号:用于其他节点在追加日志条目时进行一致性检查。
-
领导者节点检测到某个跟随者节点的日志太过庞大,或者该节点刚刚加入集群。 -
领导者节点将当前的系统状态(快照)打包,并通过InstallSnapshot RPC将该快照发送给跟随者节点。 -
跟随者节点接收到领导者发送的快照后,将其应用到自己的状态机中,使得自己的状态与领导者节点的状态一致。 -
跟随者节点同时接收到快照的元数据(如快照的最后一个包含的日志索引和任期号等),并根据这些元数据更新自己的日志。
-
领导者的ID:用于标识发送请求的节点。 -
领导者的任期号:用于确保其他节点只接受来自最新领导者的快照。 -
快照数据:包括当前系统的状态信息,如存储的数据、索引等。 -
快照元数据:包括快照的最后一个包含的日志索引和任期号等信息,用于更新跟随者节点的日志状态。
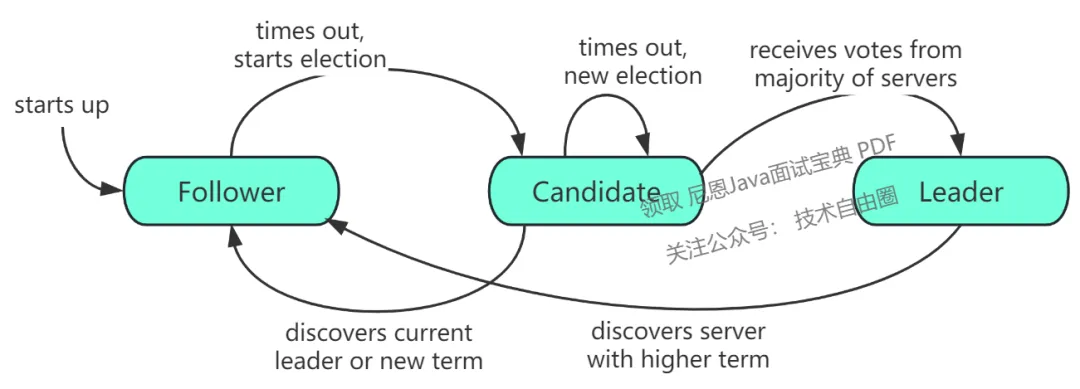
Raft 选举流程(Election)
-
Raft初次启动,不存在Leader,发起选举; -
Leader宕机或Follower没有接收到Leader的heartBeat,发生election timeout从而发起选举。
-
自己被选成了主。当收到了大多数的投票后,状态切成leader,并且定期给其它的所有server发心跳消息(其实是不带log的AppendEntriesRPC)以告诉对方自己是current_term_id所标识的term的leader。每个term最多只有一个leader,term id作为logical clock,在每个RPC消息中都会带上,用于检测过期的消息,一个server收到的RPC消息中的rpc_term_id比本地的current_term_id更大时,就更新current_term_id为rpc_term_id,并且如果当前state为leader或者candidate时,将自己的状态切成follower。如果rpc_term_id比本地的current_term_id更小,则拒绝这个RPC消息。 -
别人成为了主。如1所述,当candidate在等待投票的过程中,收到了大于或者等于本地的current_term_id的声明对方是leader的AppendEntriesRPC时,则将自己的state切成follower,并且更新本地的current_term_id。 -
没有选出主。当投票被瓜分,没有任何一个candidate收到了majority的vote时,没有leader被选出。这种情况下,每个candidate等待的投票的过程就超时了,接着candidates都会将本地的current_term_id再加1,发起RequestVoteRPC进行新一轮的leader election。
投票选举流程图解
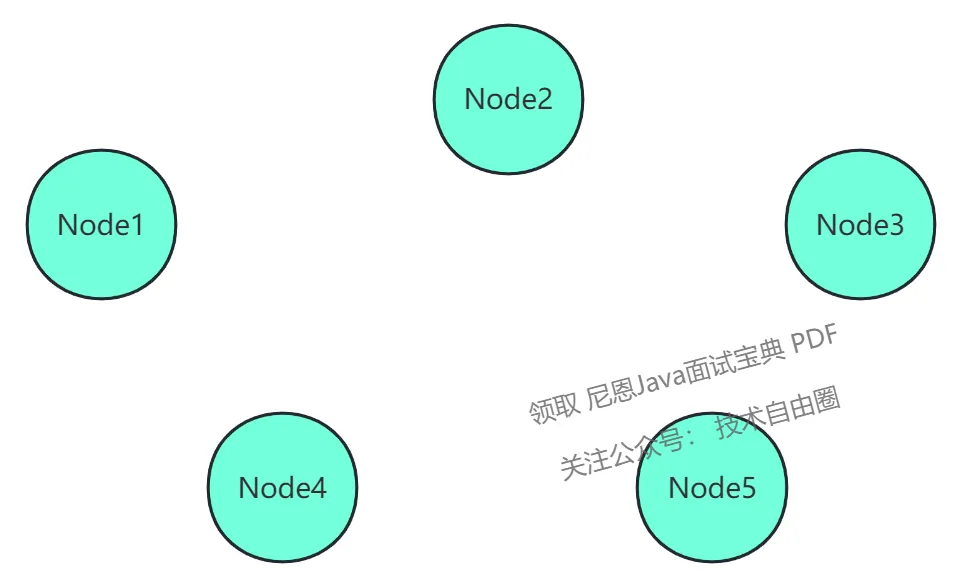 初始节点
初始节点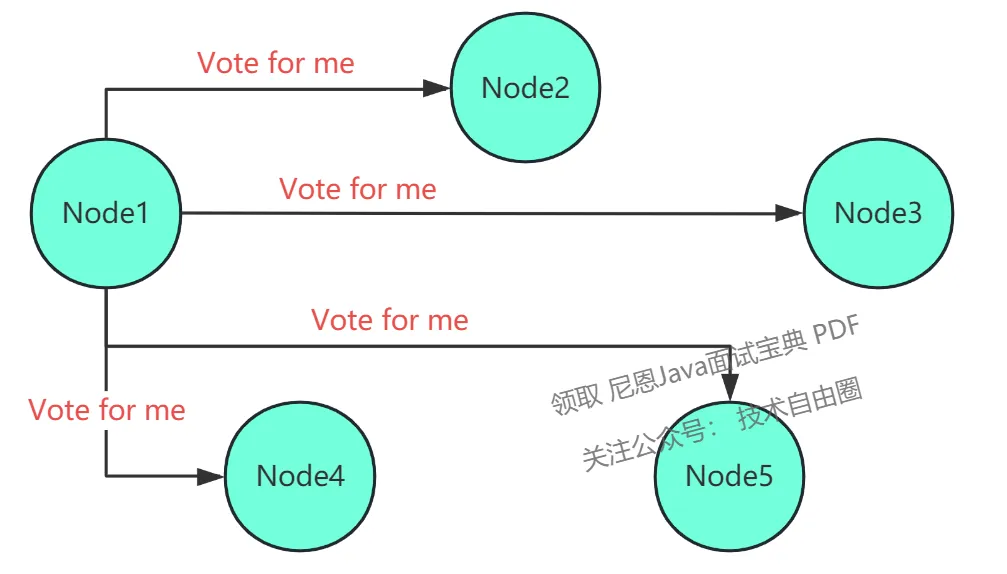 Node1 转为 Candidate 发起选举
Node1 转为 Candidate 发起选举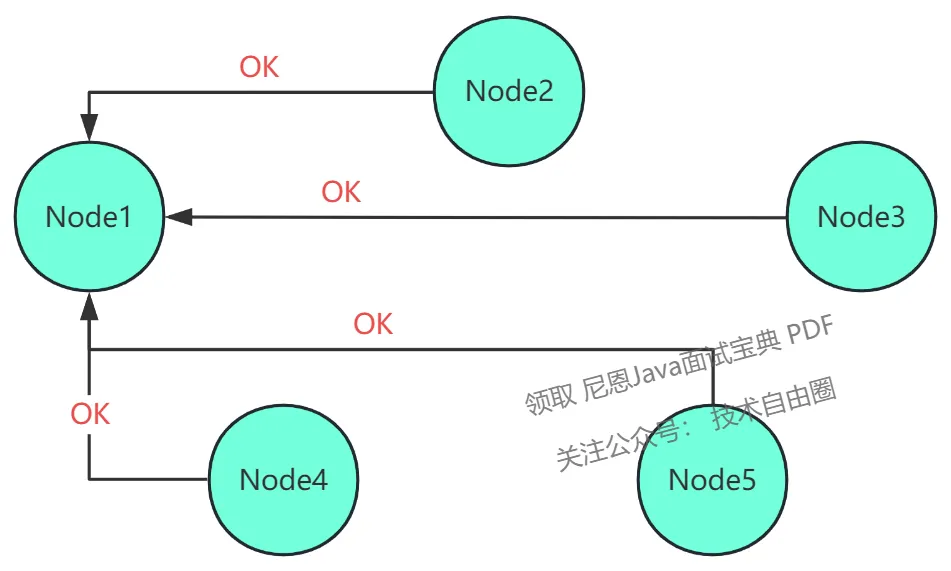 Node 确认选举
Node 确认选举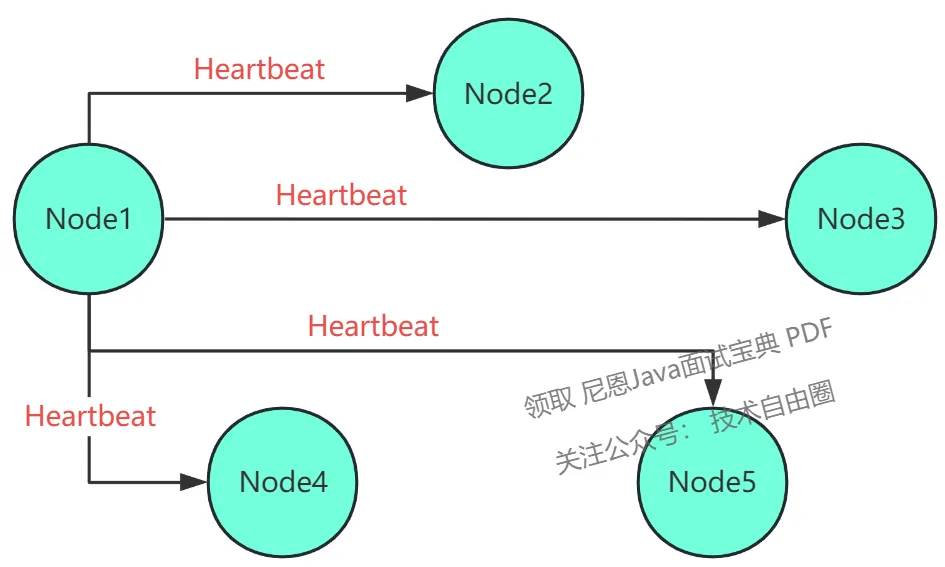
-
该节点赢得选举,即收到大多数节点的投票,然后转变为 leader 状态。 -
另一个服务器成为 leader,即收到合法心跳包(term 值大于或等于当前自身 term 值),然后转变为 follower 状态。 -
一段时间后仍未确定胜者,此时会启动新一轮的选举。
Raft 日志复制
-
Leader收到客户端请求后,leader会把它作为一个log entry,append到它自己的日志中。并向其它server发送AppendEntriesRPC(添加日志)请求。 -
其它server收到AppendEntriesRPC请求后,判断该append请求满足接收条件,如果满足条件就将其添加到本地的log中,并给Leader发送添加成功的response。 -
如果某个follower宕机了或者运行的很慢,或者网络丢包了,则会一直给这个follower发AppendEntriesRPC直到日志一致。 -
Leader在收到大多数server添加成功的response后,就将该条log正式提交。提交后的log日志就意味着已经被raft系统接受,并能应用到状态机中了。每个日志条目也包含一个整数索引来表示它在日志中的位置。
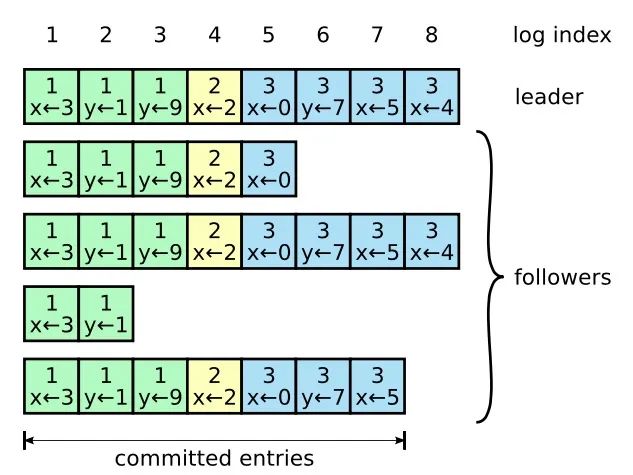
Leader Append-Only 原则
Log Matching 特性
-
如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们存储了相同的指令。 -
如果在不同的日志中的两个条目拥有相同的索引和任期号,那么他们之前的所有日志条目也全部相同。
强制复制
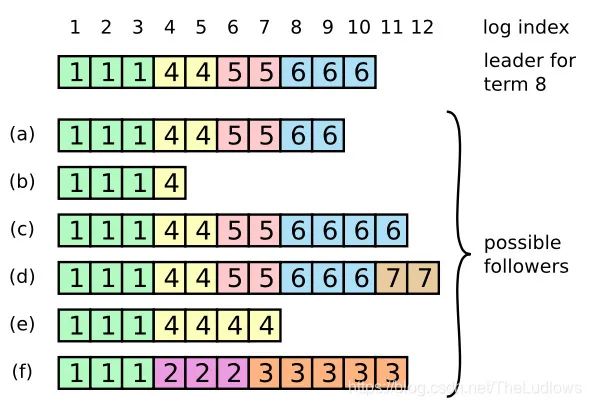
-
a,b:follower 可能丢失部分日志 -
c,d:follower 本地可能 uncommited 的日志 -
e,f:follower 可能既缺少本该有的日志,也多出额外的日志
解决冲突的性能优化
Nacos 如何实现Raft算法
启动选举
public static void init() throws Exception { Loggers.RAFT.info("initializing Raft sub-system"); // 启动Notifier,轮询Datums,通知RaftListener executor.submit(notifier); // 获取Raft集群节点,更新到PeerSet中 peers.add(NamingProxy.getServers()); long start = System.currentTimeMillis(); // 从磁盘加载Datum和term数据进行数据恢复 RaftStore.load(); Loggers.RAFT.info("cache loaded, peer count: {}, datum count: {}, current term: {}", peers.size(), datums.size(), peers.getTerm()); while (true) { if (notifier.tasks.size() <= 0) { break; } Thread.sleep(1000L); System.out.println(notifier.tasks.size()); } Loggers.RAFT.info("finish to load data from disk, cost: {} ms.", (System.currentTimeMillis() - start)); GlobalExecutor.register(new MasterElection()); // Leader选举 GlobalExecutor.register1(new HeartBeat()); // Raft心跳 GlobalExecutor.register(new AddressServerUpdater(), GlobalExecutor.ADDRESS_SERVER_UPDATE_INTERVAL_MS); if (peers.size() > 0) { if (lock.tryLock(INIT_LOCK_TIME_SECONDS, TimeUnit.SECONDS)) { initialized = true; lock.unlock(); } } else { throw new Exception("peers is empty."); } Loggers.RAFT.info("timer started: leader timeout ms: {}, heart-beat timeout ms: {}", GlobalExecutor.LEADER_TIMEOUT_MS, GlobalExecutor.HEARTBEAT_INTERVAL_MS);}
-
获取Raft集群节点 peers.add(NamingProxy.getServers()); -
Raft集群数据恢复 RaftStore.load(); -
Raft选举 GlobalExecutor.register(new MasterElection()); -
Raft心跳 GlobalExecutor.register(new HeartBeat()); -
Raft发布内容 -
Raft保证内容一致性
选举流程
POST HTTP://{ip:port}/v1/ns/raft/vote : 进行投票请求POST HTTP://{ip:port}/v1/ns/raft/beat : Leader向Follower发送心跳信息GET HTTP://{ip:port}/v1/ns/raft/peer : 获取该节点的RaftPeer信息PUT HTTP://{ip:port}/v1/ns/raft/datum/reload : 重新加载某日志信息POST HTTP://{ip:port}/v1/ns/raft/datum : Leader接收传来的数据并存入DELETE HTTP://{ip:port}/v1/ns/raft/datum : Leader接收传来的数据删除操作GET HTTP://{ip:port}/v1/ns/raft/datum : 获取该节点存储的数据信息GET HTTP://{ip:port}/v1/ns/raft/state : 获取该节点的状态信息{UP or DOWN}POST HTTP://{ip:port}/v1/ns/raft/datum/commit : Follower节点接收Leader传来得到数据存入操作DELETE HTTP://{ip:port}/v1/ns/raft/datum : Follower节点接收Leader传来的数据删除操作GET HTTP://{ip:port}/v1/ns/raft/leader : 获取当前集群的Leader节点信息GET HTTP://{ip:port}/v1/ns/raft/listeners : 获取当前Raft集群的所有事件监听者RaftPeerSet
心跳机制
-
重置Leader节点的heart timeout、election timeout; -
sendBeat()发送心跳包
public class HeartBeat implements Runnable { @Override public void run() { try { if (!peers.isReady()) { return; } RaftPeer local = peers.local(); local.heartbeatDueMs -= GlobalExecutor.TICK_PERIOD_MS; if (local.heartbeatDueMs > 0) { return; } local.resetHeartbeatDue(); sendBeat(); } catch (Exception e) { Loggers.RAFT.warn("[RAFT] error while sending beat {}", e); } }}
git clone https://github.com/alibaba/nacos.git
sentinel高可用组件的底层原理
-
限流 -
降级 -
熔断 -
预热
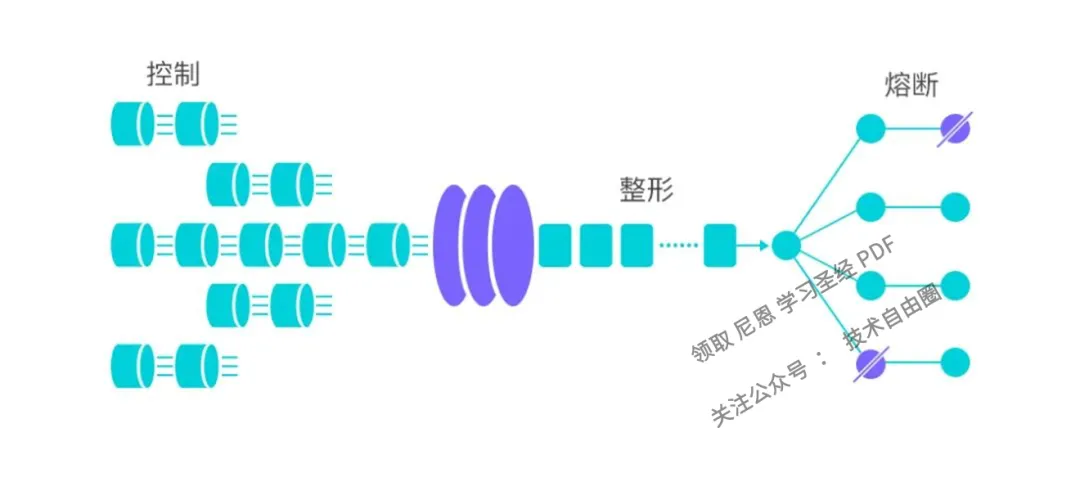
-
资源的调用关系,例如资源的调用链路,资源和资源之间的关系; -
运行指标,例如 QPS、线程池、系统负载等; -
控制的效果,例如直接限流、冷启动、排队等。
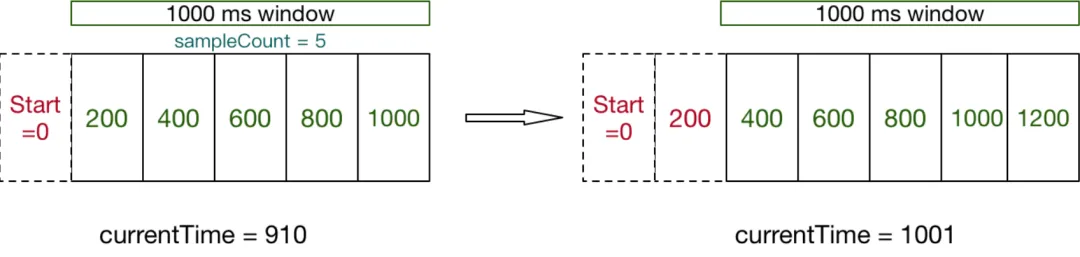
-
时间窗口划分:将整个时间范围划分为多个固定大小的时间窗口(例如1秒一个窗口)。这些时间窗口会随着时间的流逝依次滑动。 -
计数器:为每个时间窗口维护一个计数器,用于记录在该时间窗口内的请求数。 -
请求计数:当有请求到来时,将其计入当前时间窗口的计数器中。 -
滑动时间窗口:定期滑动时间窗口,将过期的时间窗口删除,并创建新的时间窗口。这样可以保持时间窗口的滚动。 -
限流判断:当有请求到来时,Sentinel会检查当前时间窗口内的请求数是否超过了预设的限制阈值。如果超过了限制阈值,请求将被拒绝或执行降级策略。 -
计数重置:定期重置过期时间窗口的计数器,以确保计数器不会无限增长。
Sentinel熔断降级,是如何实现的?
第一个维度,Sentinel主要功能:
-
Sentinel使用滑动窗口统计请求的成功和失败情况。这些统计信息包括成功的请求数、失败的请求数等。 -
当某个资源(例如一个API接口)的错误率超过阈值或其他指标达到预设的条件,Sentinel将触发熔断机制。 -
一旦熔断触发,Sentinel将暂时阻止对该资源的请求,防止继续失败的请求对系统造成更大的影响。
-
Sentinel还提供了降级机制,可以在资源负载过重或其他异常情况下,限制资源的访问速率,以保护系统免受过多的请求冲击。 -
降级策略可以根据需要定制,可以是慢调用降级、异常比例降级等。
第二个维度, Sentinel 的基本组件:
-
资源是我们想要保护的对象,比如一个远程服务、一个数据库连接等。 -
规则是定义如何保护资源的,比如我们可以通过设置阈值、时间窗口等方式来决定何时进行限流、熔断等操作。 -
上下文是一个临时的存储空间,用于存储资源的状态信息,比如当前的 QPS 等。 -
插槽属于责任链模式中的处理器/过滤器, 完成资源规则的计算和验证。
第三个维度, Sentinel 的流量治理几个核心步骤:
-
资源注册:当一个资源被创建时,需要将其注册到 Sentinel。在注册过程中,会为资源创建一个对应的上下文,并将资源的规则存储到插槽中。 -
流量控制:当有请求访问资源时,Sentinel 会根据资源的规则进行流量控制。如果当前 QPS 超过了规则设定的阈值,Sentinel 就会拒绝请求,以防止系统过载。 -
熔断降级:当资源出现异常时,Sentinel 会根据规则进行熔断或降级处理。熔断是指暂时切断对资源的访问,以防止异常扩散。降级则是提供一种备用策略,当主策略无法正常工作时,可以切换到备用策略。 -
规则更新:在某些情况下,我们可能需要动态调整资源的规则。Sentinel 提供了 API 接口,可以方便地更新资源的规则。
第四个维度, Sentinel 的源码架构维度:
Sentinel 的源码层面的两个核心架构:
-
责任链模式架构 -
滑动窗口数据统计架构
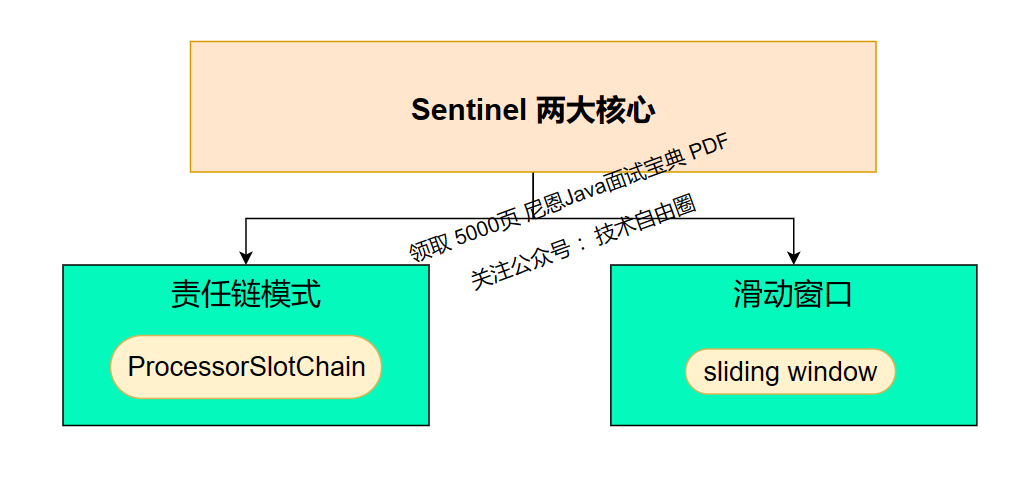
尼恩说明: 两大架构的源码,简单说说就可以了,具体可以参见《Sentinel 学习圣经》 最新版本。
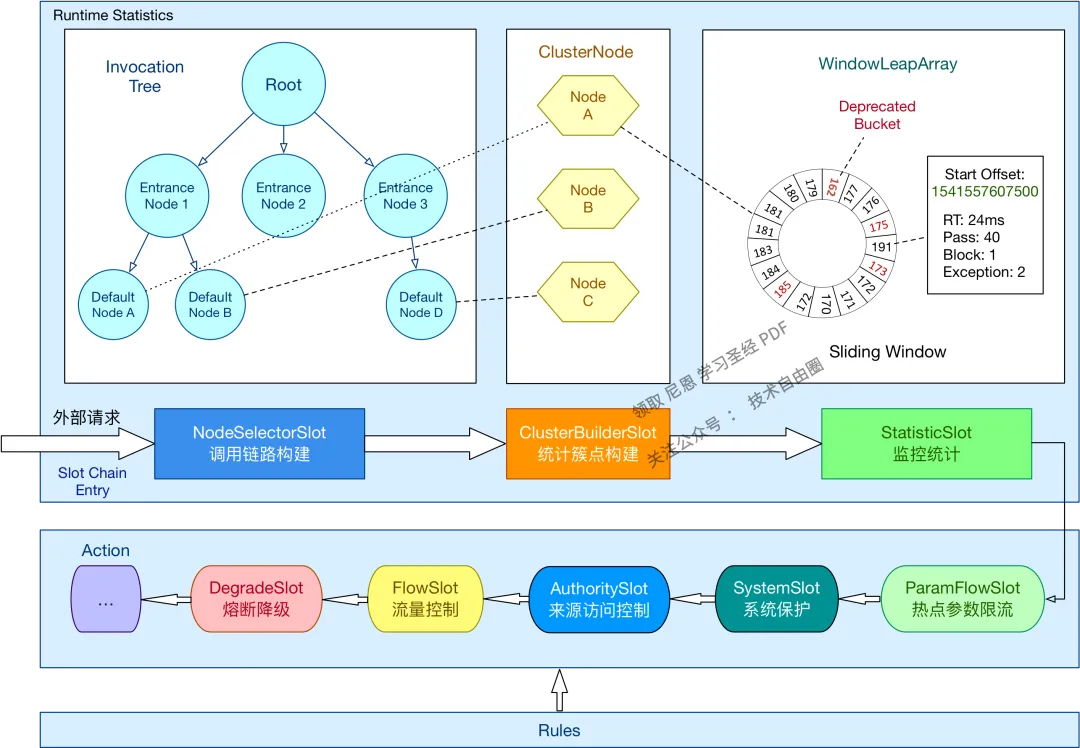
滑动窗口的核心数据结构
-
ArrayMetric:滑动窗口核心实现类。 -
LeapArray:滑动窗口顶层数据结构,包含一个一个的窗口数据。 -
WindowWrap:每一个滑动窗口的包装类,其内部的数据结构用 MetricBucket 表示。 -
MetricBucket:指标桶,例如通过数量、阻塞数量、异常数量、成功数量、响应时间,已通过未来配额(抢占下一个滑动窗口的数量)。 -
MetricEvent:指标类型,例如通过数量、阻塞数量、异常数量、成功数量、响应时间等。
ArrayMetric 源码
public class ArrayMetric implements Metric { private final LeapArray<MetricBucket> data; public ArrayMetric(int sampleCount, int intervalInMs, boolean enableOccupy) { if (enableOccupy) { this.data = new OccupiableBucketLeapArray(sampleCount, intervalInMs); } else { this.data = new BucketLeapArray(sampleCount, intervalInMs); } } }
-
int intervalInMs:表示一个采集的时间间隔,即滑动窗口的总时间,例如 1 分钟。 -
int sampleCount:在一个采集间隔中抽样的个数,默认为 2,即一个采集间隔中会包含两个相等的区间,一个区间就是一个窗口。 -
boolean enableOccupy:是否允许抢占,即当前时间戳已经达到限制后,是否可以占用下一个时间窗口的容量。
LeapArray 源码
array,类型为AtomicReferenceArray<WindowWrap<T>>,保证创建窗口的原子性(CAS)。public abstract class LeapArray<T> { //每一个窗口的时间间隔,单位为毫秒 protected int windowLengthInMs; //抽样个数,就一个统计时间间隔中包含的滑动窗口个数 protected int sampleCount; //一个统计的时间间隔 protected int intervalInMs; //滑动窗口的数组,滑动窗口类型为 WindowWrap<MetricBucket> protected final AtomicReferenceArray<WindowWrap<T>> array; private final ReentrantLock updateLock = new ReentrantLock(); public LeapArray(int sampleCount, int intervalInMs) { this.windowLengthInMs = intervalInMs / sampleCount; this.intervalInMs = intervalInMs; this.sampleCount = sampleCount; this.array = new AtomicReferenceArray<>(sampleCount); } }
MetricBucket 源码
public class MetricBucket { /** * 存储各事件的计数,比如异常总数、请求总数等 */ private final LongAdder[] counters; /** * 这段事件内的最小耗时 */ private volatile long minRt;}
public enum MetricEvent { PASS, BLOCK, EXCEPTION, SUCCESS, RT, OCCUPIED_PASS}
public long get(MetricEvent event) { return counters[event.ordinal()].sum();}
public void add(MetricEvent event, long n) { counters[event.ordinal()].add(n);}
WindowWrap 源码
public class WindowWrap<T> { /** * 单个窗口的时间长度(毫秒) */ private final long windowLengthInMs; /** * 窗口的开始时间戳(毫秒) */ private long windowStart; /** * 统计数据 */ private T value;}
-
WindowWrap 用于包装 Bucket,随着 Bucket 一起创建。 -
WindowWrap 数组实现滑动窗口,Bucket 只负责统计各项指标数据,WindowWrap 用于记录 Bucket 的时间窗口信息。 -
定位 Bucket 实际上是定位 WindowWrap,拿到 WindowWrap 就能拿到 Bucket。
loadbanlancer负载均衡组件的底层原理
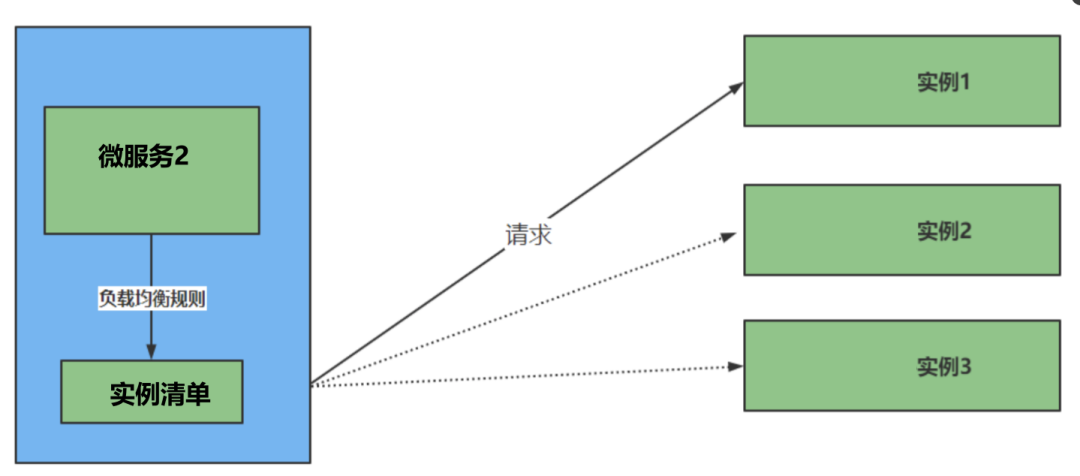
基础原理:负载均衡的类型
-
服务器端负载均衡 -
客户端侧负载均衡
基础原理:常见的负载均衡算法的实现
-
轮询(Round Robin):按照顺序依次将请求分配给每个服务器,循环往复。适用于服务器性能相近的情况。 -
加权轮询(Weighted Round Robin):在轮询的基础上,给每个服务器分配一个权重,根据权重比例分配请求。适用于服务器性能不均匀的情况。 -
随机(Random):随机选择一个服务器来处理请求,不考虑服务器的性能。适用于服务器性能相近且负载不高的情况。 -
最小连接数(Least Connections):选择当前连接数最少的服务器来处理请求。适用于服务器性能差异较大,但负载相对均匀的情况。 -
IP哈希(IP Hash):根据客户端的IP地址进行哈希计算,然后将请求分配给对应的服务器。适用于需要将同一个客户端的请求始终分配给同一台服务器的场景,比如会话保持。 -
一致性哈希(Consistent Hashing):根据请求的键(如URL、客户端ID等)进行哈希计算,然后将请求路由到哈希环上最近的服务器。适用于需要动态扩展和缩减服务器集群的场景。
随机(Random)负载均衡算法的实现
public class RandomLoadBalance { @Data @AllArgsConstructor @NoArgsConstructor public static class Server { private int serverId; private String name; } // 随机算法的核心逻辑 public static Server selectServer(List<Server> serverList) { Random selector = new Random(); int next = selector.nextInt(serverList.size()); return serverList.get(next); } public static void main(String[] args) { List<Server> serverList = new ArrayList<>(); serverList.add(new Server(1, "服务器1")); serverList.add(new Server(2, "服务器2")); serverList.add(new Server(3, "服务器3")); for (int i = 0; i < 10; i++) { Server selectedServer = selectServer(serverList); System.out.format("第%d次请求,选择服务器%sn", i + 1, selectedServer.toString()); } }}
轮询(Round Robin、RR)负载均衡算法的实现
| 服务器 | 权重 |
|
|
|
|
|
|
|
|
|
public class RoundRobin { //计数器:每次轮询一个节点自增1 private static AtomicInteger NEXT_SERVER_COUNTER = new AtomicInteger(0); @Data @AllArgsConstructor @NoArgsConstructor public static class Server { private int serverId; private String name; } /** * 轮询下标 * @param modulo 节点总数 * @return */ private static int select(int modulo) { for (; ; ) { int current = NEXT_SERVER_COUNTER.get(); //NEXT_SERVER_COUNTER + 1 % 节点总数 int next = (current + 1) % modulo; //如果当前NEXT_SERVER_COUNTER为current,CAS更新为next boolean compareAndSet = NEXT_SERVER_COUNTER.compareAndSet(current, next); //CAS更新成功直接返回,否则自旋到当前线程CAS操作成功 if (compareAndSet) { return next; } } } /** * 选举节点 * @param serverList 节点个数 * @return */ public static Server selectServer(List<Server> serverList) { return serverList.get(select(serverList.size())); } public static void main(String[] args) { List<Server> serverList = new ArrayList<>(); serverList.add(new Server(1, "服务器1")); serverList.add(new Server(2, "服务器2")); serverList.add(new Server(3, "服务器3")); for (int i = 0; i < 10; i++) { Server selectedServer = selectServer(serverList); System.out.format("第%d次请求,选择服务器%sn", i + 1, selectedServer.toString()); } }}
加权轮询(WeightedRound-Robin、WRR)负载均衡算法的实现
| 服务器 | 权重 |
|
|
|
|
|
|
|
|
|
public class WeightedRoundRobinSimple { //当前下标 private static Integer index = 0; //节点以及对应权值 private static Map<String, Integer> mapNodes = new HashMap<>(); //节点的权值列表 private static List<String> nodes = new ArrayList<>(); // 准备模拟数据 static { mapNodes.put("192.168.1.101", 1); mapNodes.put("192.168.1.102", 3); mapNodes.put("192.168.1.103", 2); // 关键代码:类似于二维数组 降维成 一维数组,然后使用普通轮询 for (Map.Entry<String, Integer> entry : mapNodes.entrySet()) { String key = entry.getKey(); for (int i = 0; i < entry.getValue(); i++) { nodes.add(key); } } System.out.println("简单版的加权轮询:" + JSON.toJSONString(nodes));//打印所有节点 } public String selectNode() { String ip = null; synchronized (index) { //如果当前下标 >= 节点数,将下标复位 if (index >= nodes.size()) { index = 0; } //获取当前下标节点 ip = nodes.get(index); //当前下标自增 index++; } return ip; } // 并发测试:两个线程循环获取节点 public static void main(String[] args) { WeightedRoundRobinSimple r = new WeightedRoundRobinSimple(); new Thread(() -> { for (int i = 1; i <= 6; i++) { String serverIp = r.selectNode(); System.out.println(Thread.currentThread().getName() + "==第" + i + "次获取节点:" + serverIp); } }).start(); new Thread(() -> { for (int i = 1; i <= 6; i++) { String serverIp = r.selectNode(); System.out.println(Thread.currentThread().getName() + "==第" + i + "次获取节点:" + serverIp); } }).start(); }}
SpringCloud 整合LoadBalancer 负载均衡
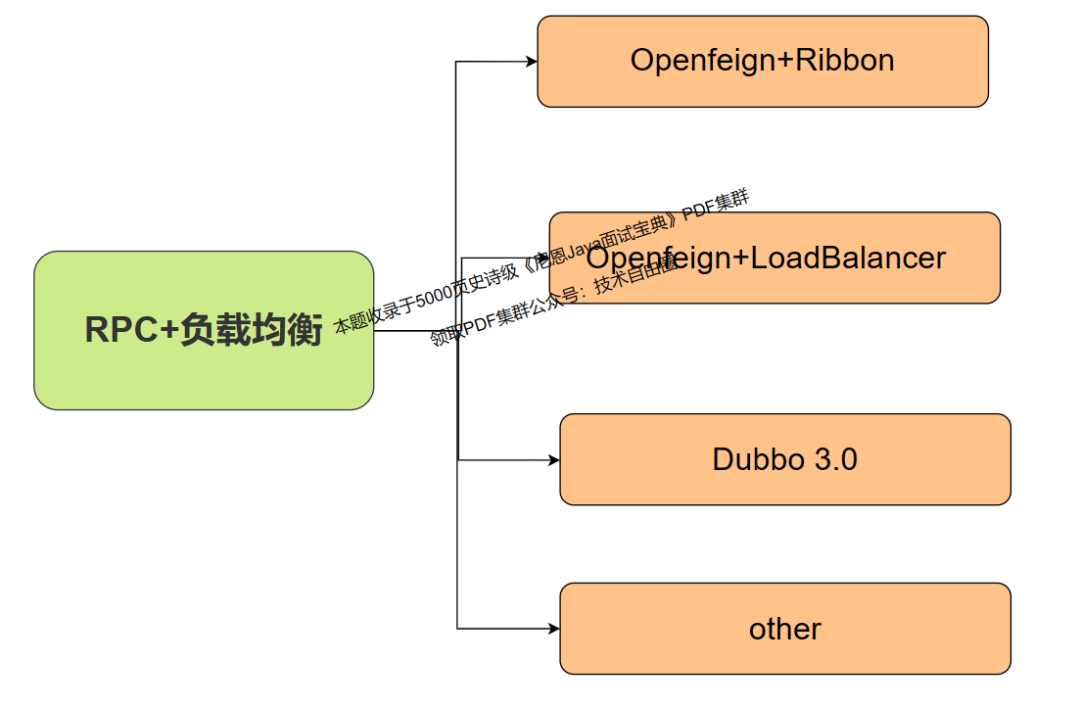
Ribbon负载均衡组件
-
负载均衡:Ribbon可以将请求平均地分配给多个后端服务实例,以实现负载均衡,提高系统的性能和可靠性。 -
容错机制:当某个服务实例发生故障或不可用时,Ribbon能够自动将请求转发给其他健康的实例,提供容错能力。 -
自定义规则:Ribbon提供了丰富的负载均衡策略,用户可以根据实际需求选择合适的负载均衡规则,或者自定义自己的规则。 -
集成性:Ribbon可以与其他Netflix开发的组件(如Eureka、Hystrix等)无缝集成,提供更全面的服务治理和容错能力。 -
动态性:Ribbon支持动态刷新负载均衡规则和服务列表,能够随着系统的变化动态调整负载均衡策略,适应不同的场景和需求。
Ribbon重要接口
| 接口 | 作用 | 默认值 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Ribbon负载均衡规则
| 规则名称 | 特点 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
LoadBalancer 负载均衡组件
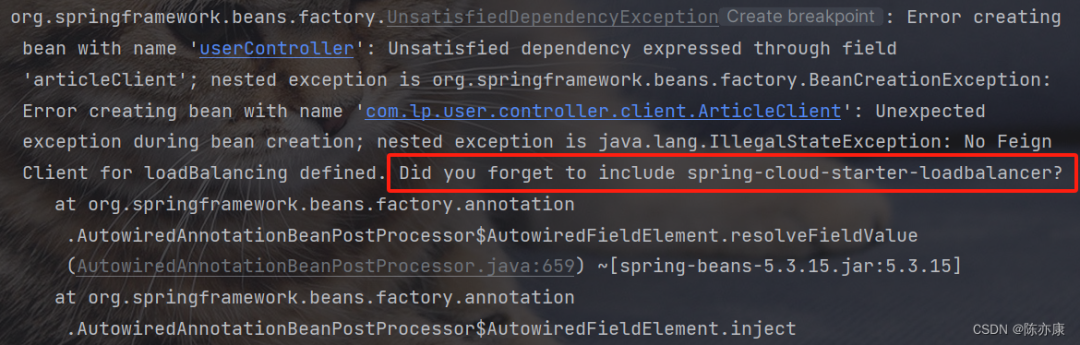
OpenFeign + LoadBalancer所需依赖
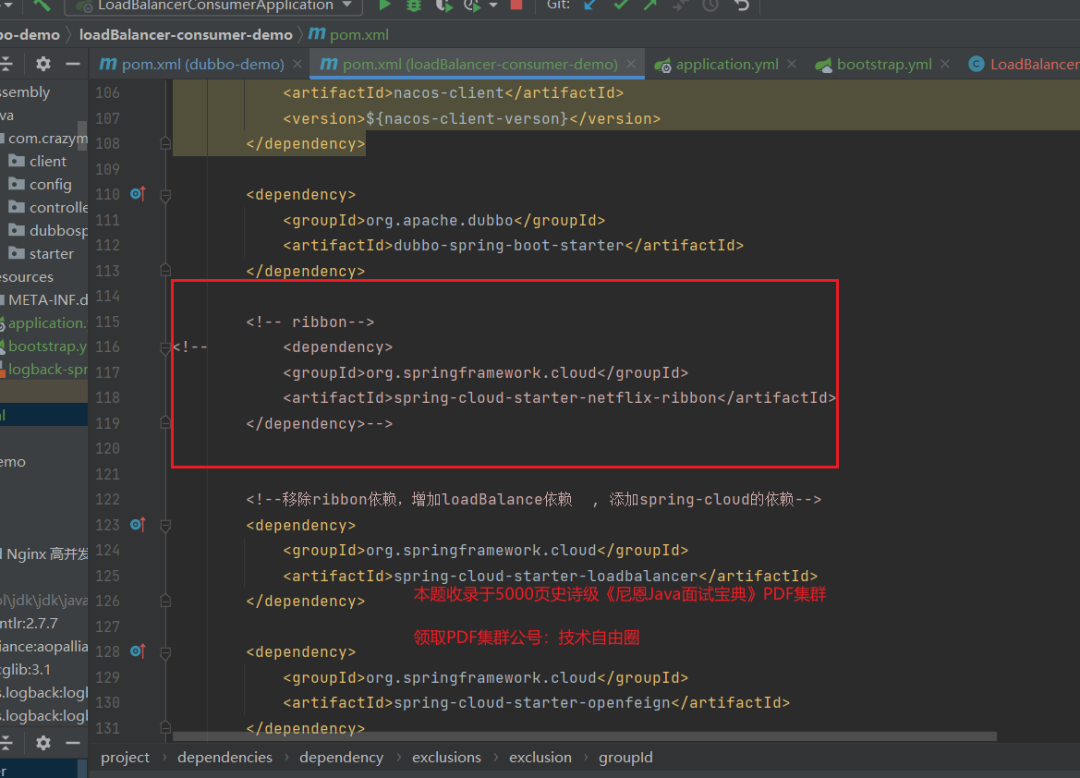
<!--移除ribbon依赖,增加loadBalance依赖 , 添加spring-cloud的依赖--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-loadbalancer</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-openfeign</artifactId> </dependency>
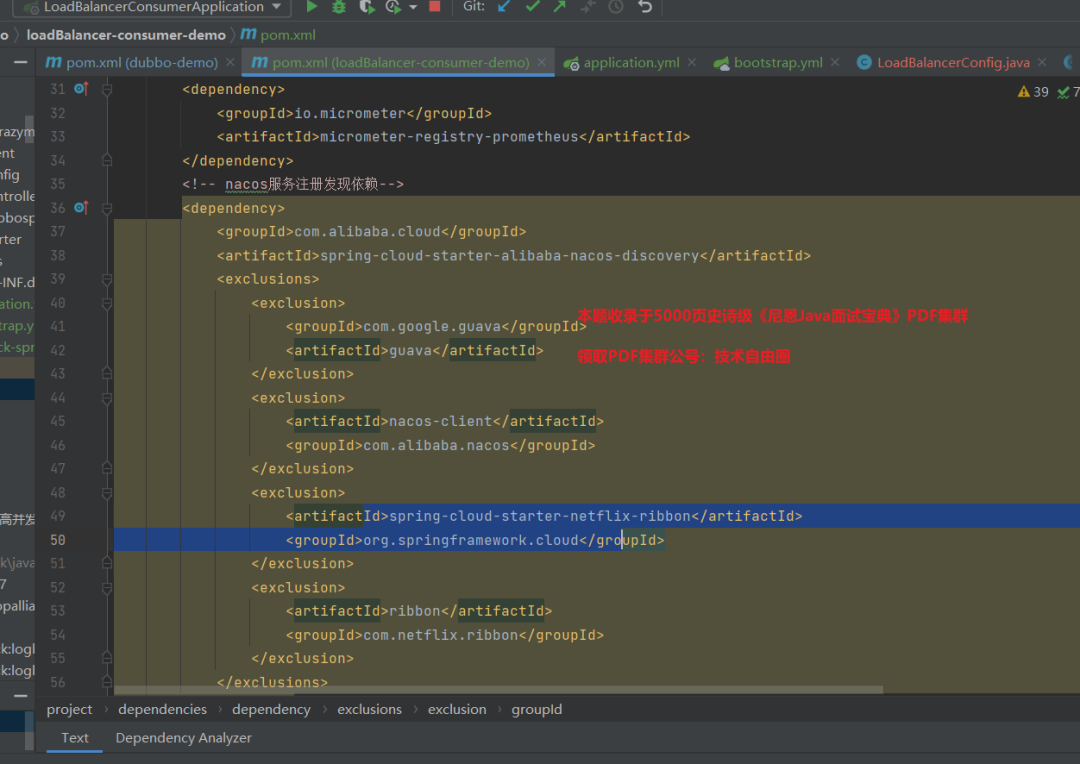
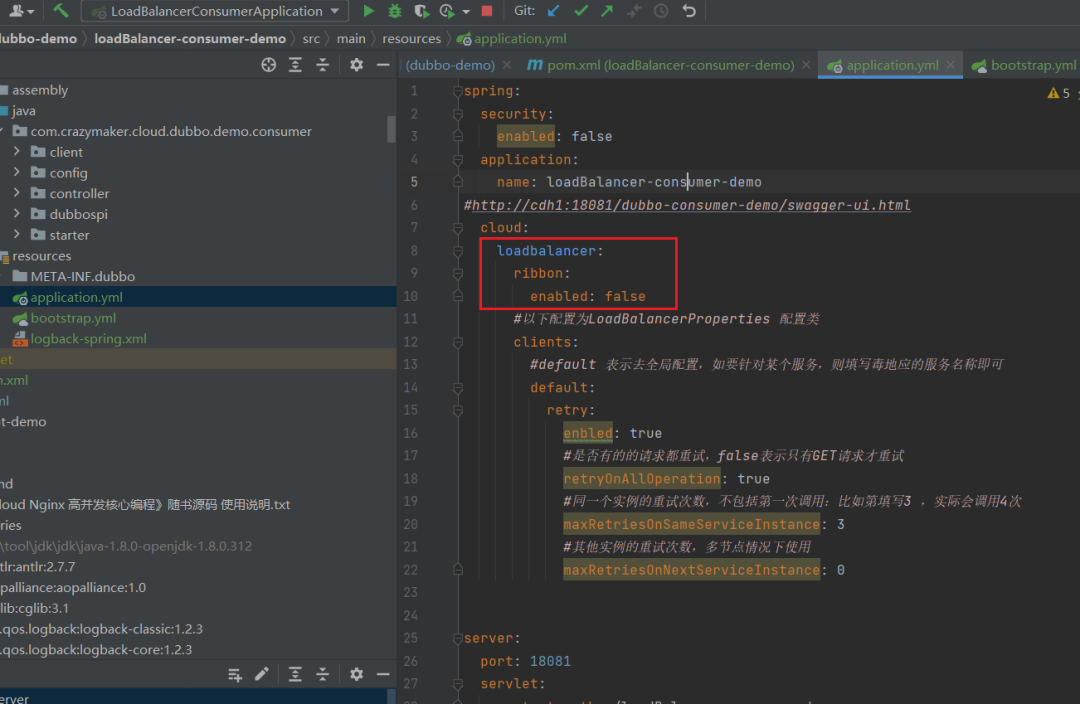
OpenFeign + LoadBalancer所需配置
OpenFeign + LoadBalancer所需注解
@LoadBalancerClients是 Spring Cloud 提供的一个注解,用于配置全局性的负载均衡器属性。比如配置 自定义的负载均衡机制。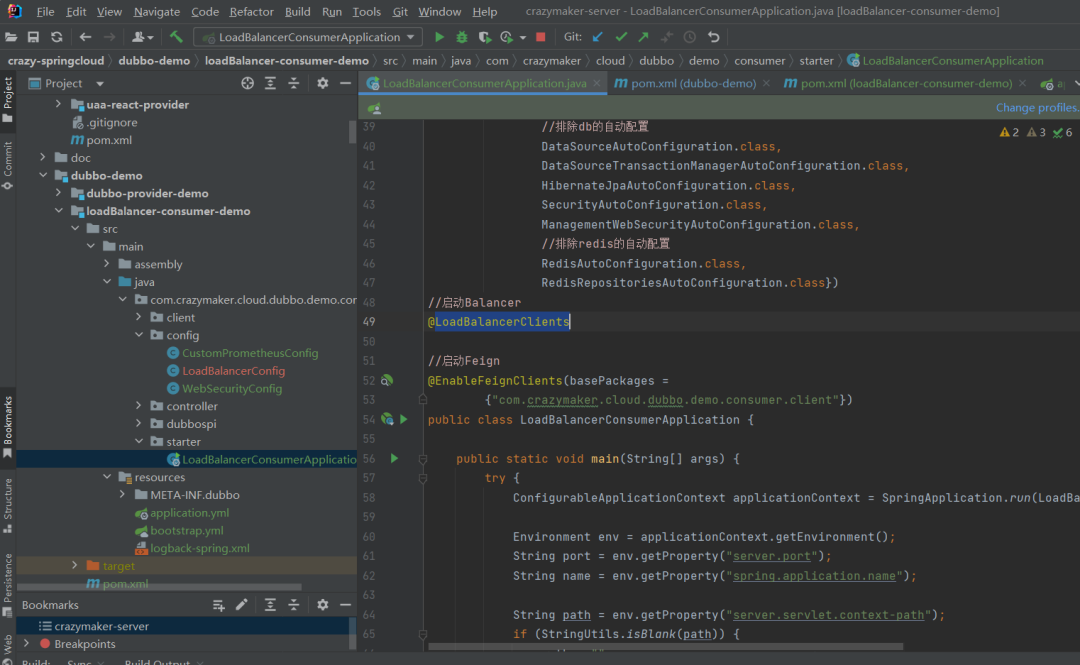
@LoadBalanced是 Spring Cloud 提供的一个注解,用于标记 RestTemplate 或 WebClient 的 Bean,以启用负载均衡功能。@LoadBalanced后,Spring Cloud 将会为其创建一个代理对象,并在发起 HTTP 请求时,自动添加负载均衡的能力。当发起 RPC 请求时,实际上是由负载均衡器选择一个目标服务实例,并将请求发送到该实例上。@LoadBalanced,则可以直接使用服务名作为 URL,而不需要指定具体的 IP 地址和端口号。Spring Cloud 会根据服务名解析出可用的服务实例,并通过负载均衡器选择其中一个来处理请求。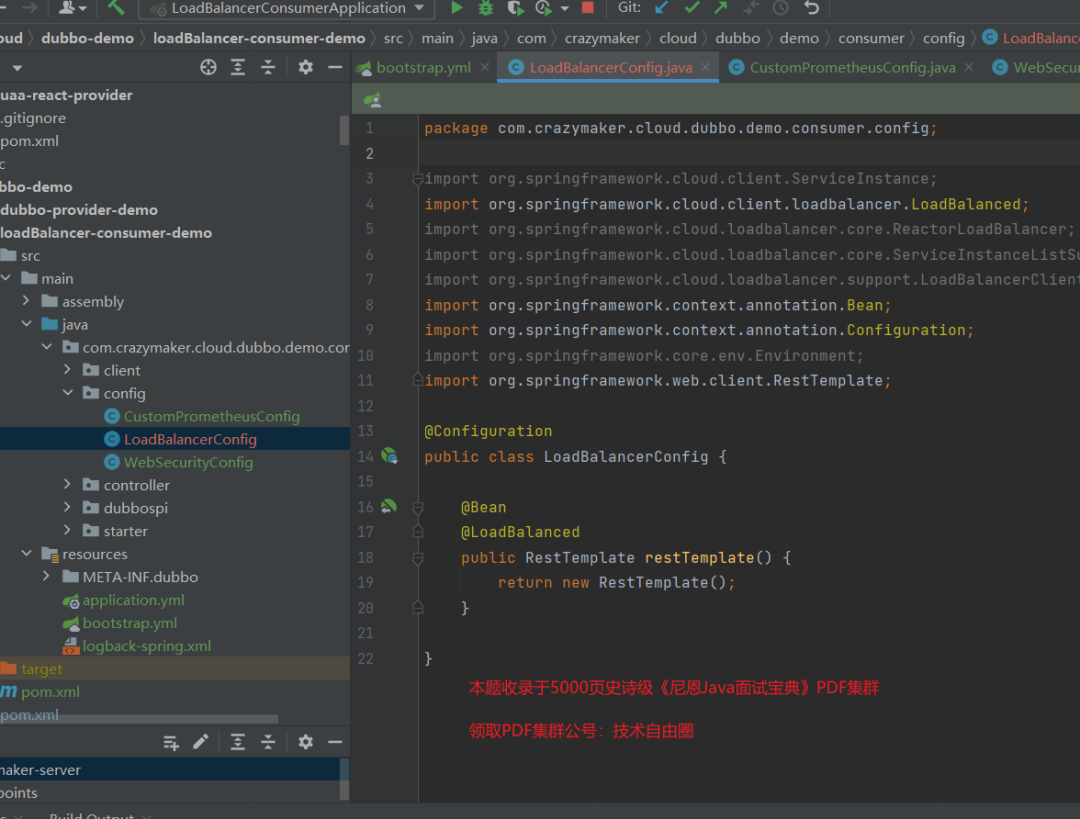
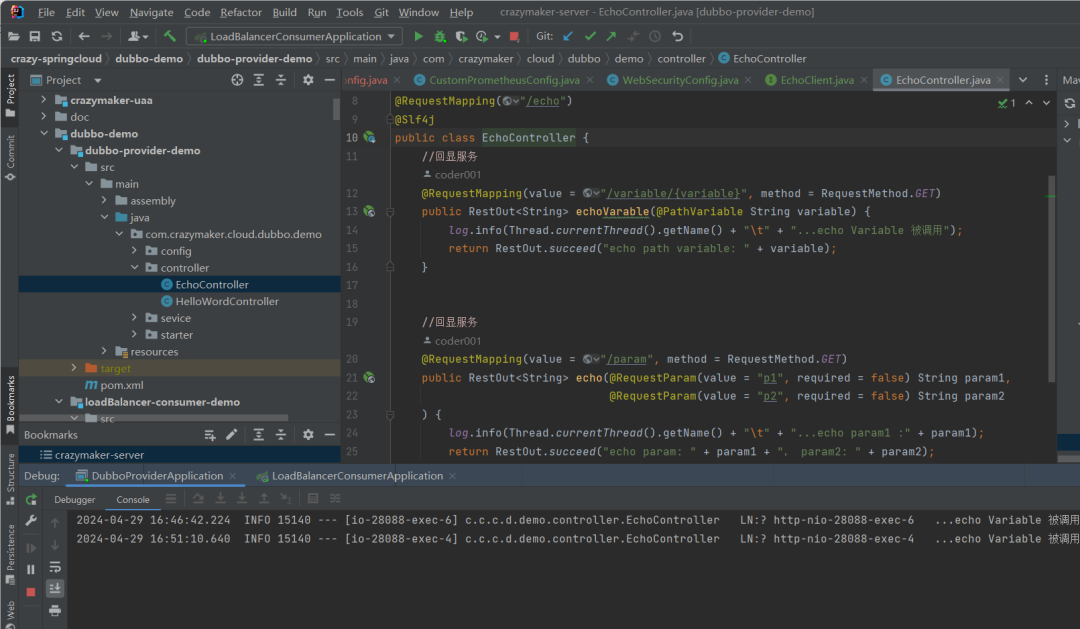
OpenFeign + LoadBalancer 的演示
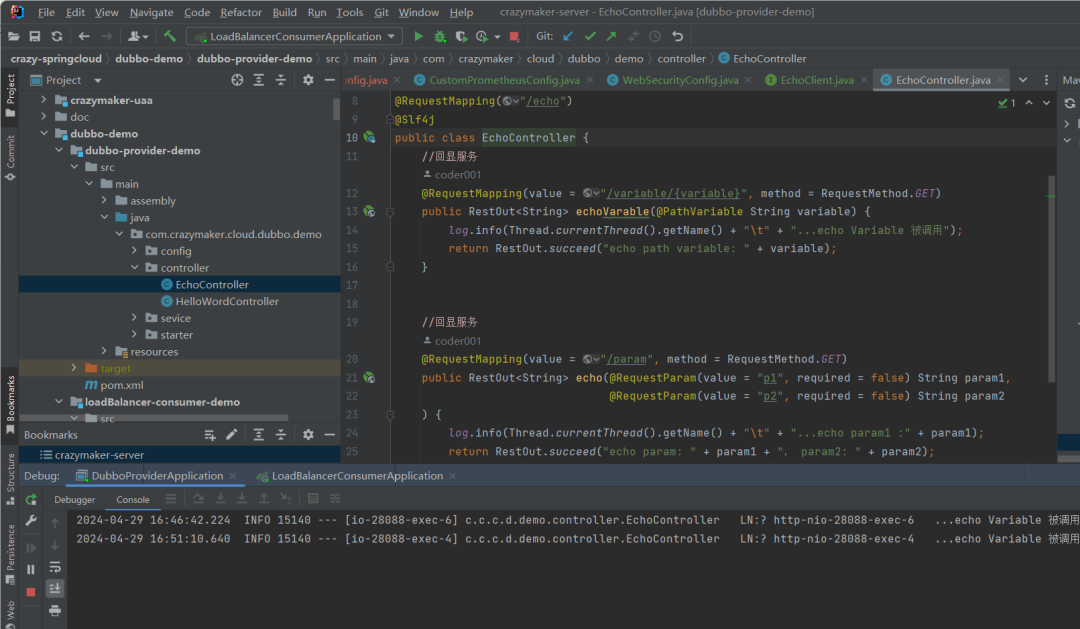
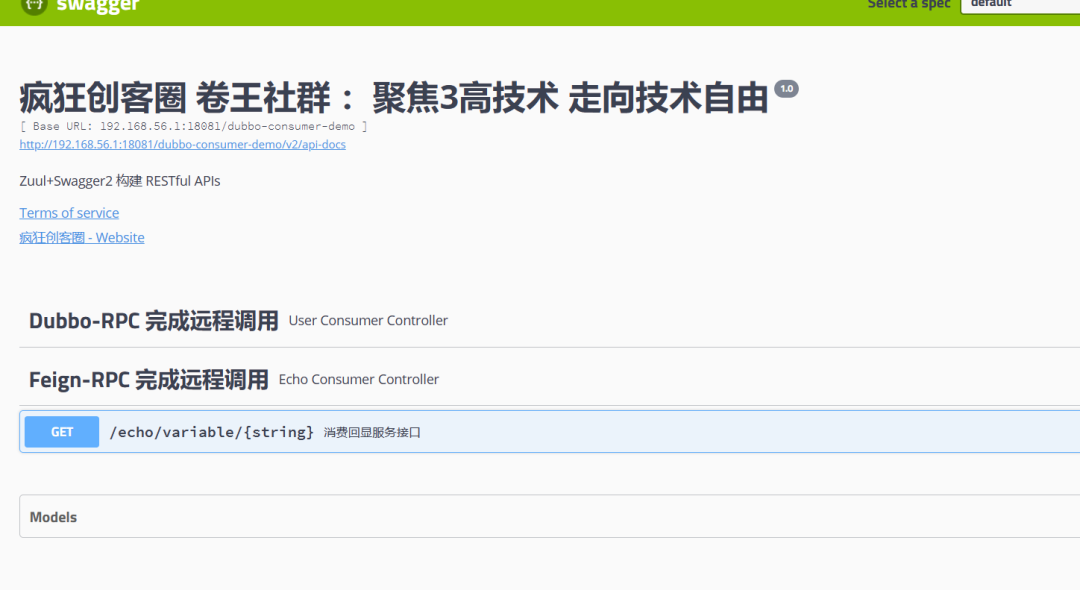
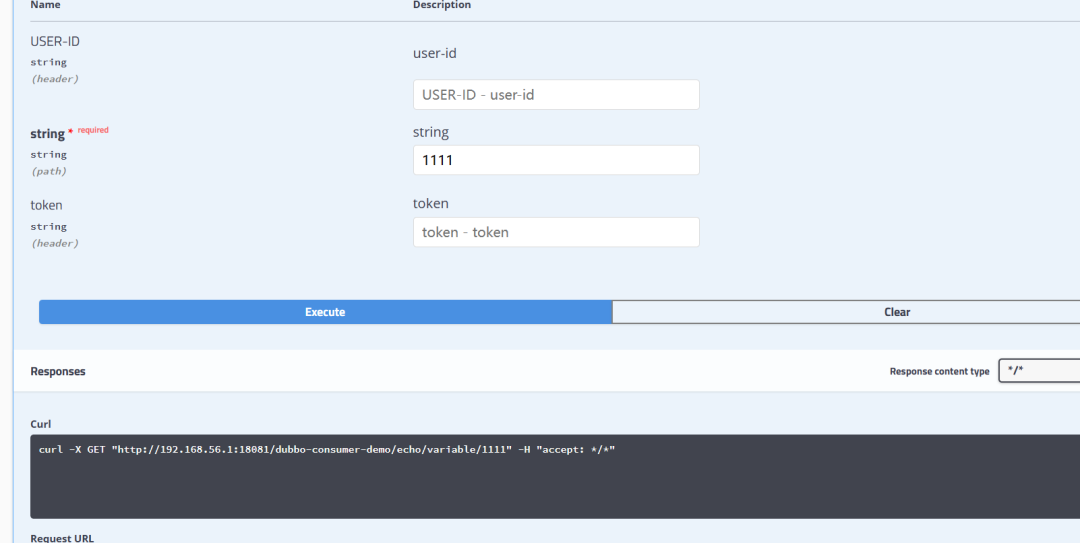
LoadBalancer自定义负载均衡策略
-
(默认)RoundRobinLoadBalancer - 轮询分配策略
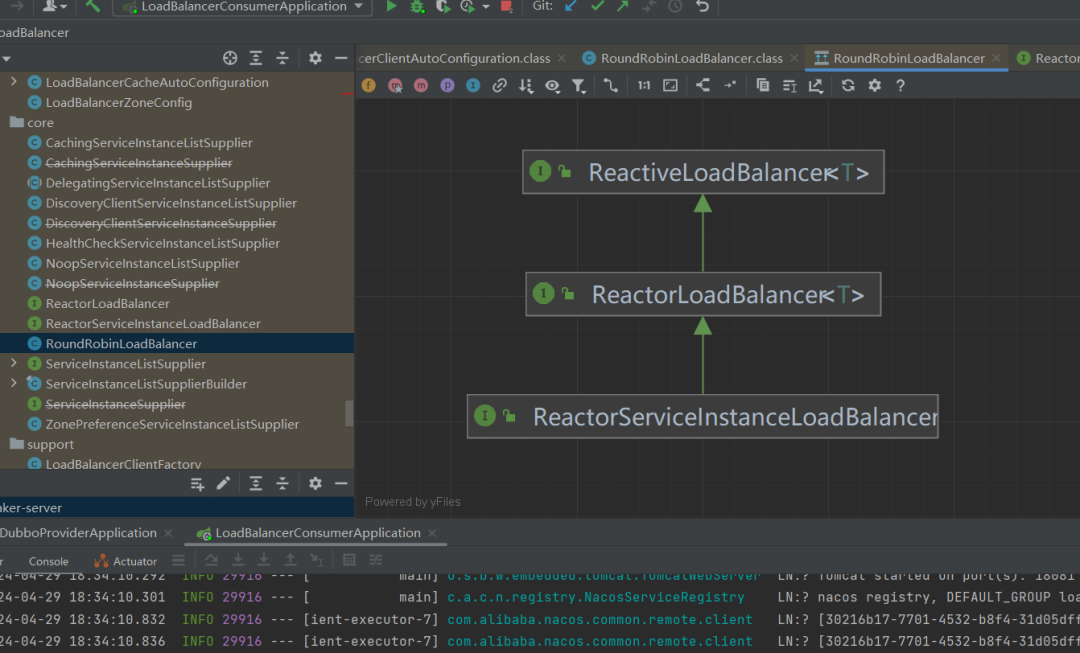
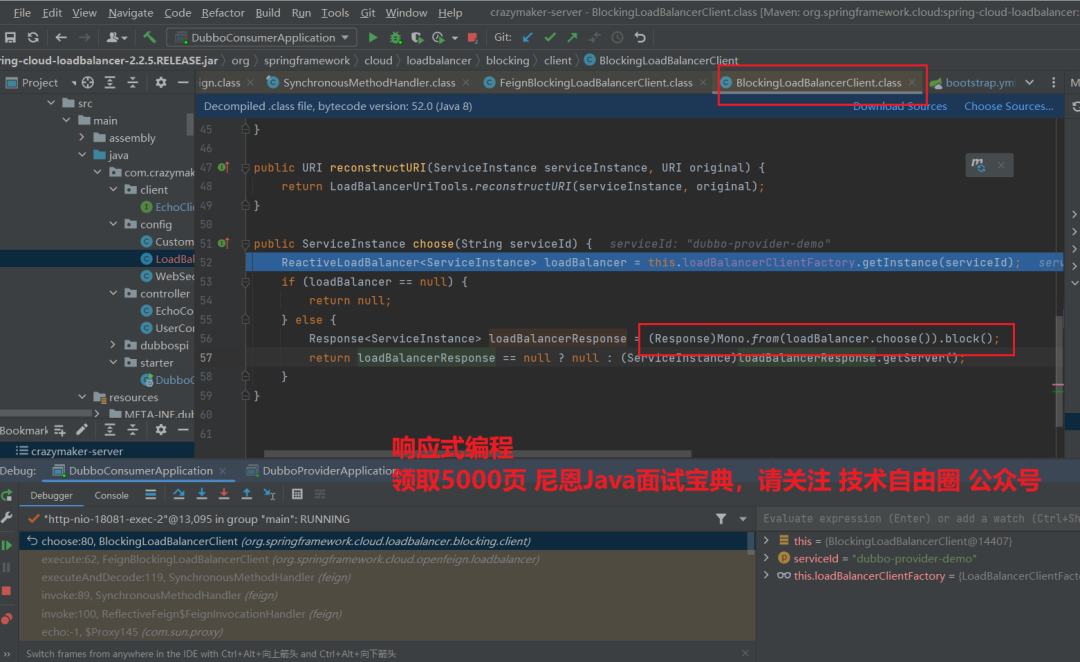
LoadBalancer基于Nacos权重自定义负载算法
choose逻辑,选取对应的节点public interface ReactorLoadBalancer<T> extends ReactiveLoadBalancer<T> { Mono<Response<T>> choose(Request request); default Mono<Response<T>> choose() { return this.choose(REQUEST); }}
通过nacos配置 权重
-
yaml中配置 spirng.cloud.nacos.discovery.weight数值范围从1-100 ,默认为1 -
可以在nacos面板找到该实例信息,并实时配置实例的权重
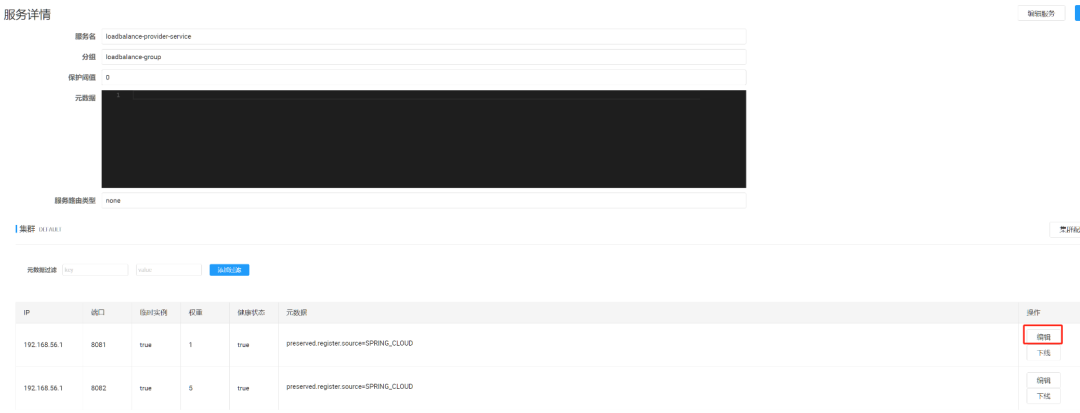
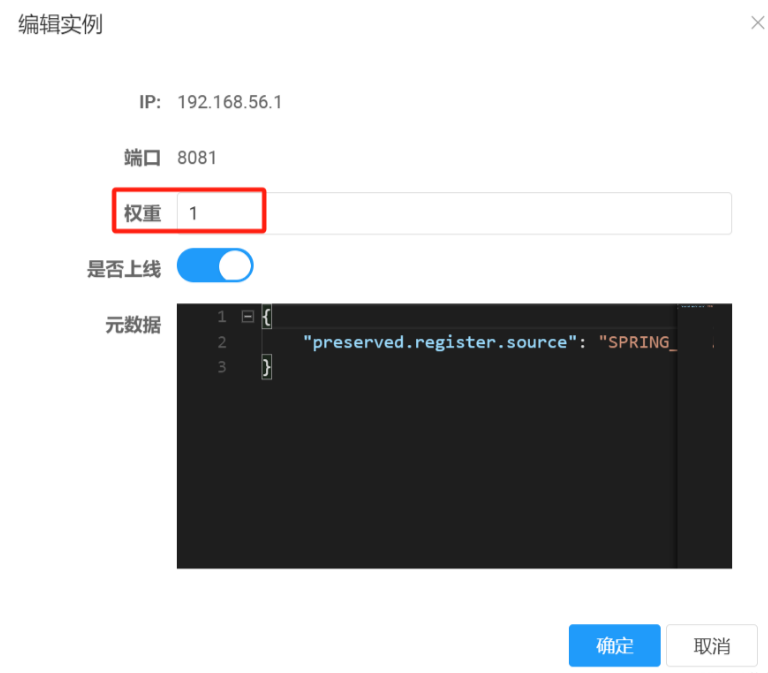
基于nacos权重实现自定义负载
RoundRobin源码,自定义NacosWeightLoadBalancerimport org.apache.commons.logging.Log;import org.apache.commons.logging.LogFactory;import org.springframework.beans.factory.ObjectProvider;import org.springframework.cloud.client.ServiceInstance;import org.springframework.cloud.client.loadbalancer.DefaultResponse;import org.springframework.cloud.client.loadbalancer.EmptyResponse;import org.springframework.cloud.client.loadbalancer.Request;import org.springframework.cloud.client.loadbalancer.Response;import org.springframework.cloud.loadbalancer.core.*;import reactor.core.publisher.Mono;import java.util.*;import java.util.concurrent.ThreadLocalRandom;/** * 基于nacos权重的负载均衡*/public class NacosWeightLoadBalancer implements ReactorServiceInstanceLoadBalancer { private static final Log log = LogFactory.getLog(NacosWeightLoadBalancer.class); private final String serviceId; private ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider; //nacos权重获取名称,在nacos元数据中 private static final String NACOS_WEIGHT_NAME = "nacos.weight"; public NacosWeightLoadBalancer(ObjectProvider<ServiceInstanceListSupplier> serviceInstanceListSupplierProvider, String serviceId) { this.serviceId = serviceId; this.serviceInstanceListSupplierProvider = serviceInstanceListSupplierProvider; } @Override public Mono<Response<ServiceInstance>> choose(Request request) { ServiceInstanceListSupplier supplier = this.serviceInstanceListSupplierProvider.getIfAvailable(NoopServiceInstanceListSupplier::new); return supplier.get(request).next().map((serviceInstances) -> { return this.processInstanceResponse(supplier, serviceInstances); }); } private Response<ServiceInstance> processInstanceResponse(ServiceInstanceListSupplier supplier, List<ServiceInstance> serviceInstances) { Response<ServiceInstance> serviceInstanceResponse = this.getInstanceResponse(serviceInstances); if (supplier instanceof SelectedInstanceCallback && serviceInstanceResponse.hasServer()) { ((SelectedInstanceCallback)supplier).selectedServiceInstance(serviceInstanceResponse.getServer()); } return serviceInstanceResponse; } private Response<ServiceInstance> getInstanceResponse(List<ServiceInstance> instances) { if (instances.isEmpty()) { if (log.isWarnEnabled()) { log.warn("No servers available for service: " + this.serviceId); } } else { //根据权重选择实例,权重高的被选中的概率大 //nacos.weight的值越大,被选中的概率越大 Double totalWeight = 0D; for (ServiceInstance instance : instances) { String s = instance.getMetadata().get(NACOS_WEIGHT_NAME); double weight = Double.parseDouble(s); totalWeight = totalWeight + weight; //放置当前实例的权重区间 instance.getMetadata().put("weight",String.valueOf(totalWeight)); } //随机获取一个区间类的数值,nacos权重越大,区间越大,则随机数值落到相应的区间的概率是由区间的大小来决定的。 double index = ThreadLocalRandom.current().nextDouble(totalWeight); //根据权重区间选择实例 for (ServiceInstance instance : instances) { double weight = Double.parseDouble(instance.getMetadata().get("weight")); if (index <= weight) { return new DefaultResponse(instance); } } } return new EmptyResponse(); }}
配置使用自定义负载均衡器
WeightLoadBalanceConfigurationpublic class WeightLoadBalanceConfiguration { @Bean public ReactorLoadBalancer<ServiceInstance> weightLoadBalancer(Environment environment, LoadBalancerClientFactory loadBalancerClientFactory) { String name = environment.getProperty(LoadBalancerClientFactory.PROPERTY_NAME); return new NacosWeightLoadBalancer(loadBalancerClientFactory .getLazyProvider(name, ServiceInstanceListSupplier.class), name); }}
@LoadBalancerClients({ @LoadBalancerClient(name = "loadbalance-provider-service", configuration = WeightLoadBalanceConfiguration.class)})
说在最后:有问题找老架构取经

部分历史案例
实现职业转型,极速上岸

关注职业救助站公众号,获取每天职业干货助您实现职业转型、职业升级、极速上岸---------------------------------
实现架构转型,再无中年危机

关注技术自由圈公众号,获取每天技术千货一起成为牛逼的未来超级架构师
几十篇架构笔记、5000页面试宝典、20个技术圣经请加尼恩个人微信免费拿走
暗号,请在 公众号后台 发送消息:领电子书
如有收获,请点击底部的"在看"和"赞",谢谢
本篇文章来源于微信公众号: 技术自由圈
微信扫描下方的二维码阅读本文

Comments NOTHING