本篇主要介绍一下 Kafka 的Connect 以及 结合 confluentinc 提供的 kafka-connect-jdbc 实现数据从 mysql 到 kafka 再从kafka到 mysql 的数据流转
Kafka Connect 的基本介绍
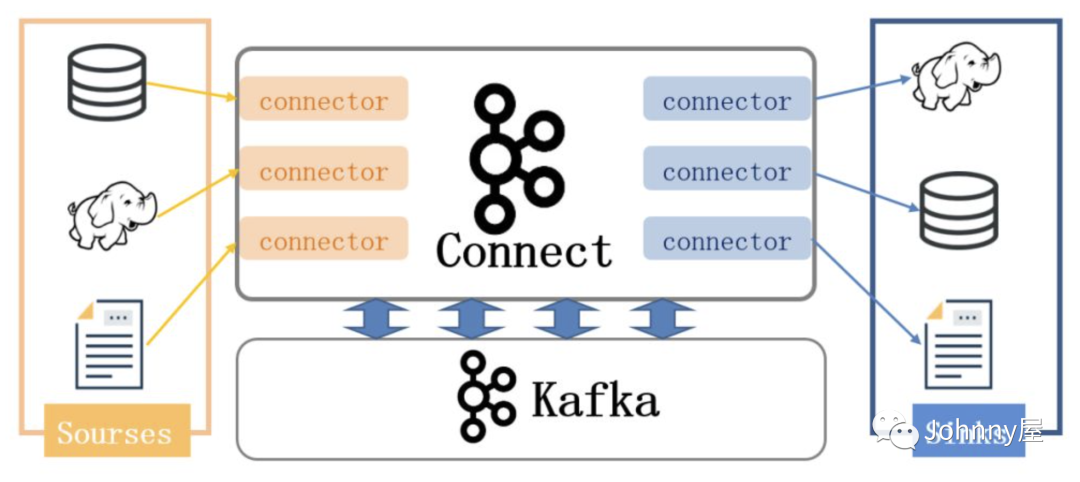
什么是kafka Connect ?
- Kafka Connect 是从 Kafka 0.9+ 版本开始增加了一个新的特性,可以更方便的创建和管理数据流管道。它使得能够快速定义将大量数据集合移入和移出 Kafka 的连接器变得简单。
- Kafka Connect 可以将完整的数据库注入到 Kafka 的 Topic 中,比如将服务器的系统监控指标注入到 Kafka,然后像正常的 Kafka 流处理机制一样进行数据流处理。
- 导出工作则是将数据从 Kafka Topic 中导出到其它数据存储系统、查询系统或者离线分析系统等,比如数据库、Elastic Search、Apache Ignite 等。
kafka Connect 核心概念
kafka Connect 有两个核心概念 Source 和 Sink , Source 负责从外部导入数据到Kafka , Sink 负责从Kafka 导出数据到外部, 它们都被称为 Connector , Kafka 提供了一套通用框架Connector, 实现具体的 导入导出 需要自己实现, 不过已经有很多现成的 Connector , 如本篇要介绍的 jdbc-connector , 你可以在 confluent官网 上搜索可用的Connector
Kafka Connect + Jdbc Mysql 案例准备
下面来通过 kafka connect 结合 jdbc mysql 实现 mysql表中的数据流转到 kafka 并且 再从 kafka 到mysql的另外一个表中
安装kafka
首先安装kafka 不想多说, 首先要启动kafka
下载kafka-jdbc-connector
从这个confluent 官网可以下载 connector confluent官网
配置kafka-jdbc-connector
# 第一步 上传kafka-connect-jdbc后 进行解压 如果没有 unzip 就 yum -y install unzip
unzip -d /opt/plugins/ confluentinc-kafka-connect-jdbc-10.7.1.zip
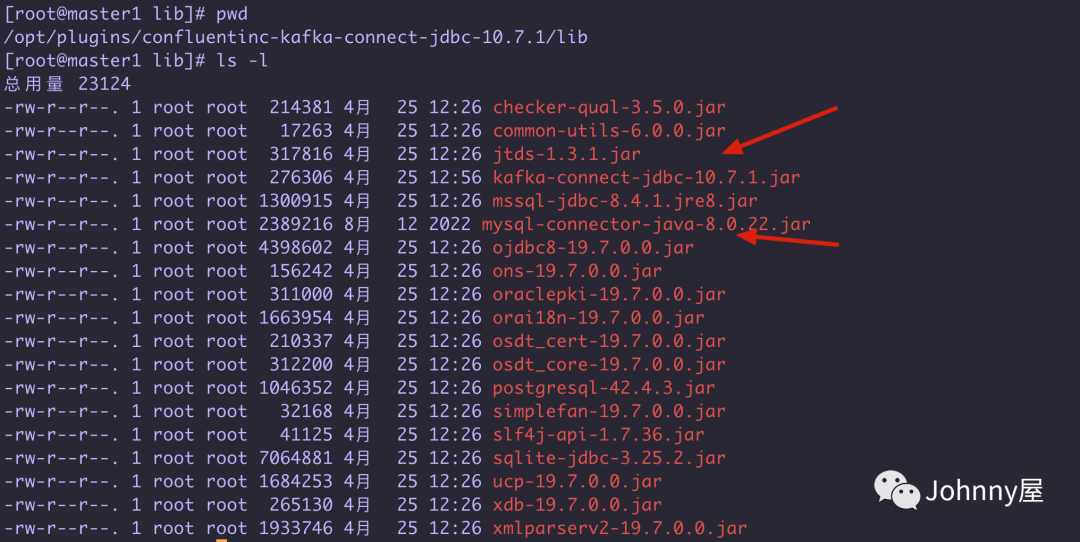
#### 准备mysql 驱动包
由于 kafka-jdbc-connector 里面没有提供 mysql的驱动包 ,所以要自己准备一下
cd /opt/plugins/confluentinc-kafka-connect-jdbc-10.7.1/lib
rz 上传 mysql-connector-java-8.0.22.jar
# 准备 source 和 sink 的mysql 配置文件
cd /opt/plugins/confluentinc-kafka-connect-jdbc-10.7.1/etc
# 把默认的sqlite 配置文件 copy 一份
cp source-quickstart-sqlite.properties source-mysql.properties
cp sink-quickstart-sqlite.properties sink-mysql.properties
standalone 模式
这里模拟 从数据库mysql 中 product_lock表 数据到 kakfa 再到 product_lock_bak 的备份表里
先来看看 standalone 模式启动Kafka Connect
启动 命令如下 , 可以看到指定了connect-standalone.properties 后面要配置 connector 配置文件
bin/connect-standalone.sh config/connect-standalone.properties [connector1.properties connector2.properties ...]配置 connect-standalone.properties
# 找到kafka的安装目录 下的config 里面有一个 standalone 配置文件进行修改
vim $Kafka_HOME/config/connect-standalone.properties配置kafka的地址 和 plugin.path 指定 上面解压的 kafka-connector-jdbc的目录 , 或者你可以把 confluentinc-kafka-connect-jdbc-10.7.1/lib 目录下面的 对应的jar copy到 kafka的lib 目录下也可以 不指定这个插件地址了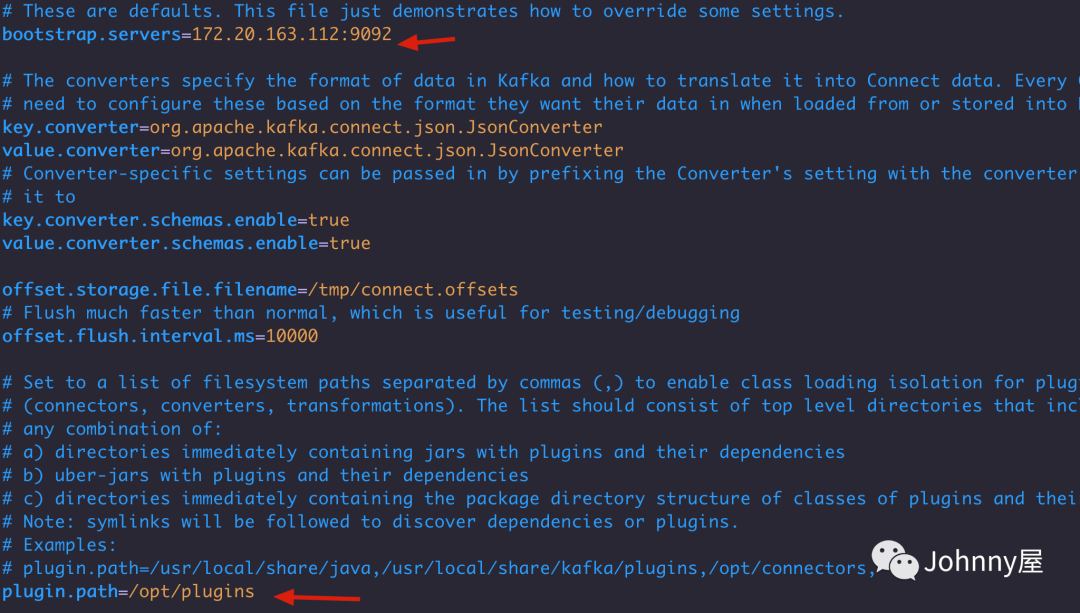
配置Source (source-mysql.properties)
配置 Source ,代表 从 mysql 到 kafka 的数据流转 Connector
上面在解压 kafka-jdbc-connector 后 etc目录下有默认的 sqlite 相关配置, copy 一份作为mysql的配置
# 把默认的sqlite 配置文件 copy 一份
cp source-quickstart-sqlite.properties source-mysql.properties
cp sink-quickstart-sqlite.properties sink-mysql.properties
vim /opt/plugins/confluentinc-kafka-connect-jdbc-10.7.1/etc/source-mysql.propertiessource-mysql.properties
# A simple example that copies all tables from a SQLite database. The first few settings are
# required for all connectors: a name, the connector class to run, and the maximum number of
# tasks to create:
name=test-source-mysql-jdbc-autoincrement
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
# The remaining configs are specific to the JDBC source connector. In this example, we connect to a
# SQLite database stored in the file test.db, use and auto-incrementing column called 'id' to
# detect new rows as they are added, and output to topics prefixed with 'test-sqlite-jdbc-', e.g.
# a table called 'users' will be written to the topic 'test-sqlite-jdbc-users'.
connection.url=jdbc:mysql://172.16.1.224:3306/localdemo?user=root&password=root123456
mode=incrementing
table.whitelist=product_lock
incrementing.column.name=id
topic.prefix=test-mysql-jdbc-
# Define when identifiers should be quoted in DDL and DML statements.
# The default is 'always' to maintain backward compatibility with prior versions.
# Set this to 'never' to avoid quoting fully-qualified or simple table and column names.
#quote.sql.identifiers=always解释: name: 给任务启一个名称 connector.class : 指定Connector的实现 , 这个不用改 connection.url : 指定 mysql的地址 table.whitelist : 指定操作哪些表 incrementing.column.name: 自增的列 topic.prefix: topic 前缀 *最终的topic是 前缀+表明 = test-mysql-jdbc-product_lock *
启动 connect-standalone
bin/connect-standalone.sh config/connect-standalone.properties /opt/plugins/confluentinc-kafka-connect-jdbc-10.7.1/etc/source-mysql.properties
再开启一个终端执行 消费 kafka 数据 topic = test-mysql-jdbc-product_lock
bin/kafka-console-consumer.sh --topic test-mysql-jdbc-product_lock --bootstrap-server 172.20.163.112:9092 --from-beginning

可以看到表里的数据都到了kafka中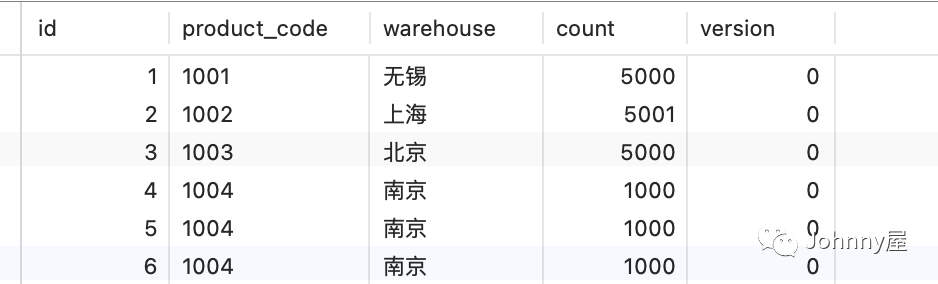
模拟新增数据
这里模拟新增一个数据到mysql中, 可以看到 数据被connector 加载到 kafka 中了

配置Sink (sink-mysql.properties)
配置 Sink ,代表 从 Kafka 到 mysql 的数据流转 Connector ,这里模拟 从product_lock数据到 kakfa 再到 product_lock_bak 的备份表里
# A simple example that copies from a topic to a SQLite database.
# The first few settings are required for all connectors:
# a name, the connector class to run, and the maximum number of tasks to create:
name=test-sink-jdbc
connector.class=io.confluent.connect.jdbc.JdbcSinkConnector
tasks.max=1
# The topics to consume from - required for sink connectors like this one
topics=test-mysql-jdbc-product_lock
# Configuration specific to the JDBC sink connector.
# We want to connect to a SQLite database stored in the file test.db and auto-create tables.
connection.url=jdbc:mysql://172.30.2.49:3306/localdemo?user=root&password=root123456
auto.create=false
# Define when identifiers should be quoted in DDL and DML statements.
# The default is 'always' to maintain backward compatibility with prior versions.
# Set this to 'never' to avoid quoting fully-qualified or simple table and column names.
#quote.sql.identifiers=always
insert.mode=upsert
pk.mode=record_value
pk.fields=id
table.name.format=product_lock_backtopics=test-sink-jdbc-topic : 指定从哪个topic 消费数据 auto.create=false : 指定是否创建表, 如果自动创建表,那么创建表的名称为topic名称。insert.mode=upsert : 代表update 和 insert 都进行操作 pk.mode=record_value
pk.fields=id : 主键的id 和上面pk.mode 要同时存在 table.name.format=product_lock_back : 配置表的名称
启动 connect-standalone
bin/connect-standalone.sh config/connect-standalone.properties /opt/plugins/confluentinc-kafka-connect-jdbc-10.7.1/etc/source-mysql.properties /opt/plugins/confluentinc-kafka-connect-jdbc-10.7.1/etc/sink-mysql.properties
模拟新增数据
可以看到新增到 product_lock 的数据 最后 通过kafka 又转到了 product_lock_bak 备份表中了
distributed 模式
distrubuted 模式 和 standalone 的配置差不多 只不过它支持动态的平衡 Task任务 ,也就是说如果某个Work进程挂了那他的任务Task 会被分配到其他的Work , 这里可以把Work理解为一台机器, 下面来看看实验效果
首先准备2台机器 分别跑 上面的connector , 为了简单 只跑 source-mysql.properties , 并且成功后把 跑Task任务的那台机器上的Work 关闭了, 验证是否能切换到另外一台Work上
distributed 模式注意点
- 可以在一台机器上启动多个 connect-distributed.sh 但是要变更 port 8083 或者不开启
- connect-distributed.sh 后面只跟 connect-distributed.properties , 后面不需要 connector 文件, 不像standalone 那样
准备工作
服务器列表 172.20.163.112 : 安装了kafka 和 zookeeper 和 启动 只启动connector 172.20.163.142 : 只启动connector
2台机器的 connect-distributed.properties 配置文件如下
# A list of host/port pairs to use for establishing the initial connection to the Kafka cluster.
bootstrap.servers=172.20.163.112:9092
# unique name for the cluster, used in forming the Connect cluster group. Note that this must not conflict with consumer group IDs
group.id=connect-cluster
...
rest.port=8083
plugin.path=/opt/plugins172.20.163.142 机器

172.20.163.112 机器
执行后发现Work运行在左边这个机器 172.20.163.112 上
执行Post 接口
可以请求 http://172.20.163.142:8083 或者 http://172.20.163.112:8083 只要打开了8083端口都行, 参数和 前面standalone上面的 source-mysql.properties 基本一样 只是是以json格式, 172.16.1.177:3306是我mac本机的数据库
curl -X POST -H 'Content-Type: application/json' -i 'http://172.20.163.142:8083/connectors'
--data
'{"name":"mysql-distribute-upload","config":{
"connector.class":"io.confluent.connect.jdbc.JdbcSourceConnector",
"connection.url":"jdbc:mysql://172.16.1.177:3306/localdemo?user=root&password=root123456",
"table.whitelist":"product_lock",
"incrementing.column.name": "id",
"mode":"incrementing",
"topic.prefix": "mysql-distribute-2-test"}}'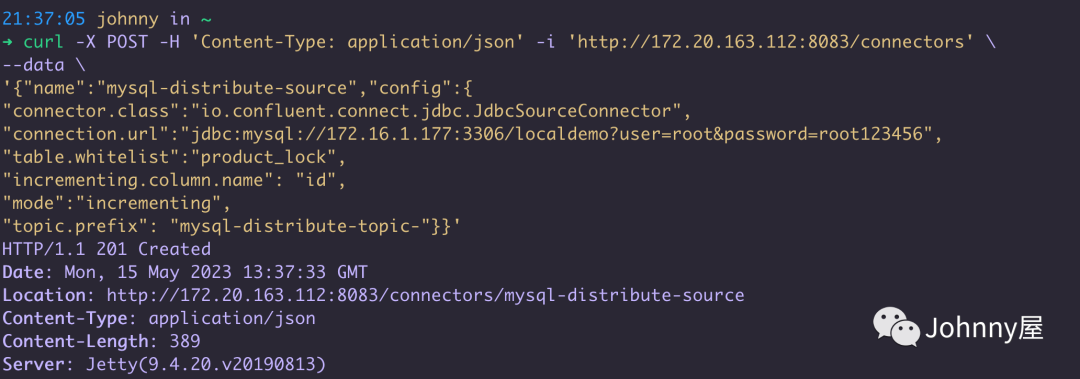
通过 host:8083/ connectors , 也能查询到 创建的 connector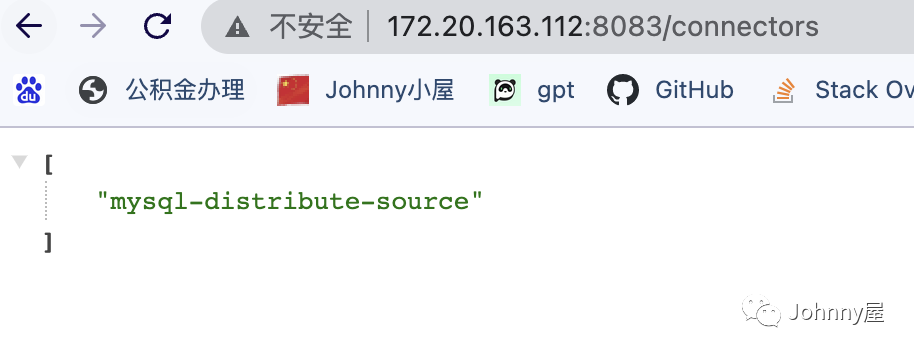
可以看到 当我关闭了 左边 172.20.163.112 的 connector 的时候 Task 会跑到右边 172.20.163.143 机器上运行了,这就是集群模式的好处 ,它有Rebalance再平衡能力!!
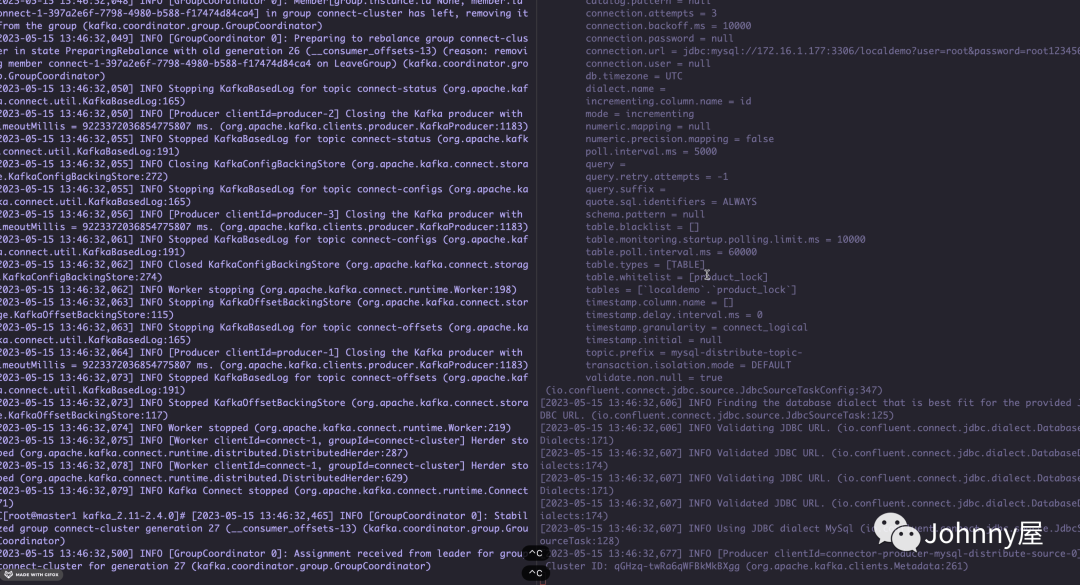
Rest Api
最后再提供一下 关于distributed 模式的Rest API 接口情况
因为kafka connect的意图是以服务的方式去运行,所以它提供了REST API去管理connectors,默认的端口是8083,你也可以在启动kafka connect之前在配置文件中添加rest.port配置。
- GET /connectors – 返回所有正在运行的connector名
- POST /connectors – 新建一个connector; 请求体必须是json格式并且需要包含name字段和config字段,name是connector的名字,config是json格式,必须包含你的connector的配置信息。
- GET /connectors/{name} – 获取指定connetor的信息
- GET /connectors/{name}/config – 获取指定connector的配置信息
- PUT /connectors/{name}/config – 更新指定connector的配置信息
- GET /connectors/{name}/status – 获取指定connector的状态,包括它是否在运行、停止、或者失败,如果发生错误,还会列出错误的具体信息。
- GET /connectors/{name}/tasks – 获取指定connector正在运行的task。
- GET /connectors/{name}/tasks/{taskid}/status – 获取指定connector的task的状态信息
- PUT /connectors/{name}/pause – 暂停connector和它的task,停止数据处理知道它被恢复。
- PUT /connectors/{name}/resume – 恢复一个被暂停的connector
- POST /connectors/{name}/restart – 重启一个connector,尤其是在一个connector运行失败的情况下比较常用
- POST /connectors/{name}/tasks/{taskId}/restart – 重启一个task,一般是因为它运行失败才这样做。
- DELETE /connectors/{name} – 删除一个connector,停止它的所有task并删除配置。
总结
本篇主要介绍了关于 kafka 的Connect 是什么 以及它的核心概念, 并且实际操作了一下 kafka-jdbc-connector ,让mysql 数据库同步到kafka ,再通过 kafka 到mysql 数据的过程, confluent 公司提供了不少关于 kafka的各种connector confluent官网 有 本篇使用的jdbc , 还有 Elasticsearch , Redis RabbitMQ等等... 都可以去操作玩玩

本篇文章来源于微信公众号: Johnny屋
微信扫描下方的二维码阅读本文

Comments NOTHING