在上一篇文章面试官:Redis如何实现分布式锁?直击灵魂的连环七问你接得住么?中,我们探讨了分布式锁的使用场景和Redis实现分布式锁的基本方法。然而,面试官的追问可能并不会止步于此,这些也还不足以支持我们实现一个生产可用的分布式锁。今天我们就来继续探讨下关于分布式锁更高阶的一些话题。
从文章中我们了解到,Redis分布式锁的一般流程是:
1、获取锁,并设置过期时间
2、执行业务逻辑,操作资源
3、释放锁
这就存在一个关键问题:过期时间到底设置多长合适?
面试官:业务逻辑没执行完,锁就过期释放了,如何解决呢?
最直接的解决方案就是给锁续期,我们可以启动一个守护线程去检测锁是否即将过期,如果即将过期,则自动进行续期,重新设置过期时间。
这也确实是一种比较好的方案,Redission是一个优秀的Redis SDK客户端(Java语言实现),在实现分布式锁时,也是采用了自动续期的方案来避免锁过期,这个守护线程一般称作「看门狗」线程。如下图所示:
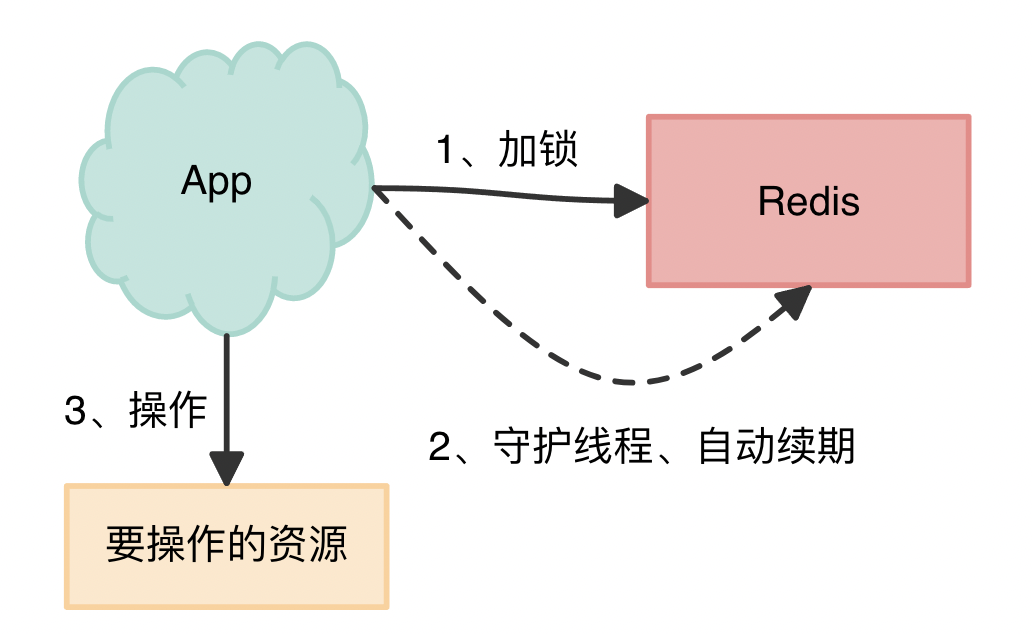
面试官:如何实现Redis分布式锁的高可用呢?
我们首先想到的还是Redis的单点故障问题,如果Redis挂了,分布式锁就不能正常工作了,因此我们可以引入Redis主从模式。如下图所示:
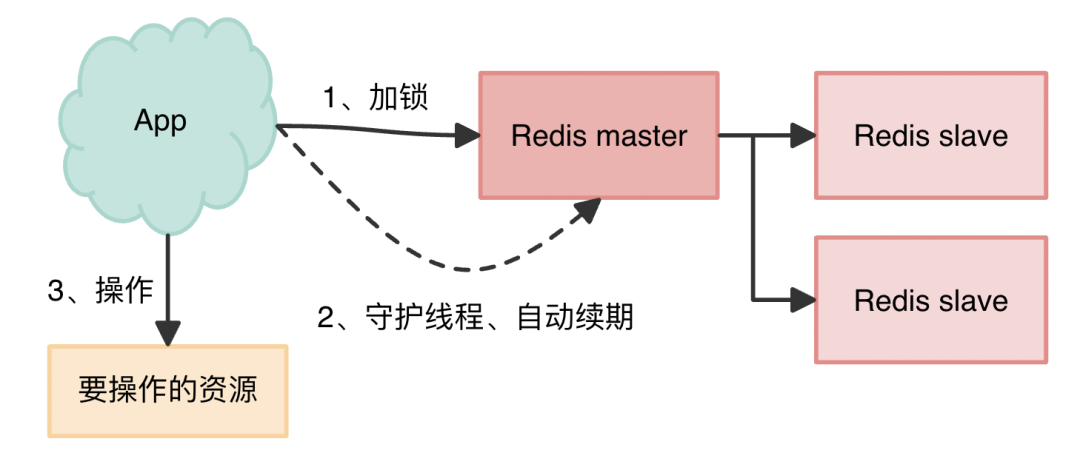
但是,如果我们在Redis集群的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。但是此时分布式锁也已经失效了。
怎么解决这个问题呢?为此,Redis 的作者提出一种解决方案,就是我们经常听到的Redlock(红锁)。为此,我们需要部署5个单独的Redis,Redlock的实现步骤如下:
1、向5个Redis master节点请求加锁;
2、根据设置的超时时间来判断(加锁的总耗时要小于锁设置的过期时间),是不是要跳过该master节点;
3、如果大于等于3个节点加锁成功,并且使用的时间小于锁的有效期,即可认定加锁成功啦;
4、释放锁,向全部节点发起释放锁请求。
关于Redlock还有这么一段趣事:
Redis作者把这个方案一经提出,就马上受到业界著名的分布式系统专家Martin的质疑[2]。Martin指出了分布式系统的三类异常场景(NPC):
N:Network Delay,网络延迟
P:Process Pause,进程暂停(GC)
C:Clock Drift,时钟漂移
Martin 用一个进程暂停(GC)的例子,指出了 Redlock 安全性问题,由于GC问题会导致分布式锁的正确性出现问题,如下图所示:
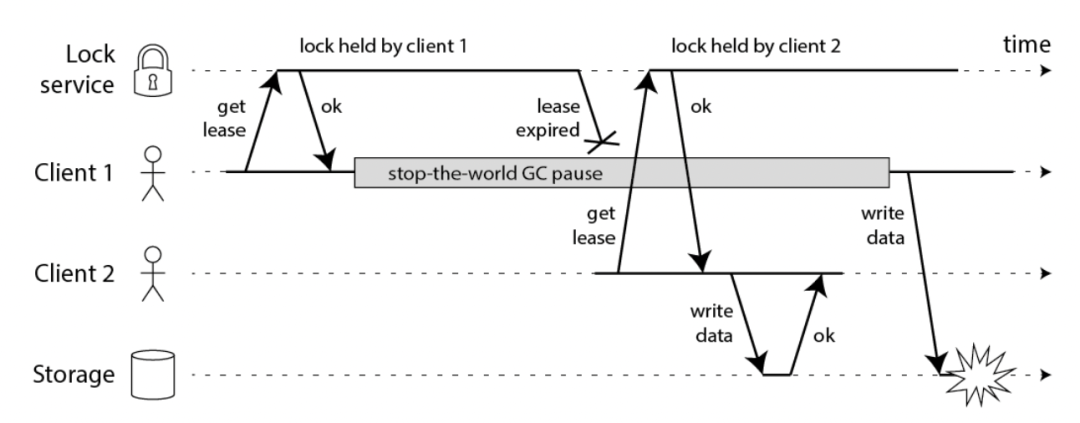
之后Redis作者毫不客气地进行了回怼[3],Redis 作者同意对方关于时钟跳跃对Redlock的影响,但认为通过运维手段是可以避免的。Redlock中有超时时间判断的机制,可以有效避免NPC问题,但是如果Redlock 步骤3(成功拿到锁)之后发生GC,不止是 Redlock 有问题,其它分布式锁服务同样也有问题,所以不在讨论范畴内。如果对这段趣事感兴趣,详细的过程与分析可以查看参考文章[4][5]。
面试官:那么,一个功能全面的分布式锁一般都包含哪些特征呢?
结合上面提到的,分布式锁应包含以下特征:
1、互斥性:任意时刻,只有一个客户端能持有锁;
2、锁超时释放:持有锁超时,可以释放,防止死锁;
3、锁释放安全:锁只能被持有的客户端删除,不能被其他客户端删除;
4、高性能、高可用:加锁、解锁效率高,同时要保证高可用;
类比Java等语言中的本地锁实现,一些分布式锁框架也大多实现了可重入、公平锁等特性,即:
5、可重入:一个线程获得锁之后,可以再次对其请求加锁,也可以支持设置可重入的次数;
6、公平性:先来的先拿到锁,还是采用抢占的方式争抢锁。
这些也都可以参考Redission等优秀客户端中的具体实现。
面试官:除了Redis,还有哪些实现分布式锁的方案?
方案一:基于MySQL
了解了Redis实现分布式锁的方案,相信我们同样可以把方案迁移到MySQL中,阻塞等机制我们可以借助MySQL的事务和锁机制(select...forupdate)[6]。
缺点:性能较低,不适合高并发场景。实现比较繁琐,实际上很少有人拿MySQL去实现分布式锁。
方案二:基于ZooKeeper或Etcd实现
除了Redis实现分布式锁,相信最多的方案就是基于ZooKeeper或Etcd实现了。ZooKeeper或Etcd实现分布式锁的优势在于:
1、两者就是分布式的,天然具备高可用能力;
2、都有临时节点的能力,能够很好支持锁超时释放等机制的实现;
3、基于顺序节点、Revision 机制等,更方便实现可重入、公平性等特性;
4、基于Watch、Revision 机制更容易避免分布式锁争抢中的「惊群效应」问题(抢占分布式锁时被频繁唤醒和重新休眠,造成浪费)。解决方案为:分布式锁释放后,只唤醒满足条件的下一个节点。
ZK实现分布式锁的基本原理是:以某个资源为目录,然后这个目录下面的节点就是我们需要获取锁的客户端,未获取到锁的客户端注册需要注册Watcher到上一个客户端。如下图所示[6]:
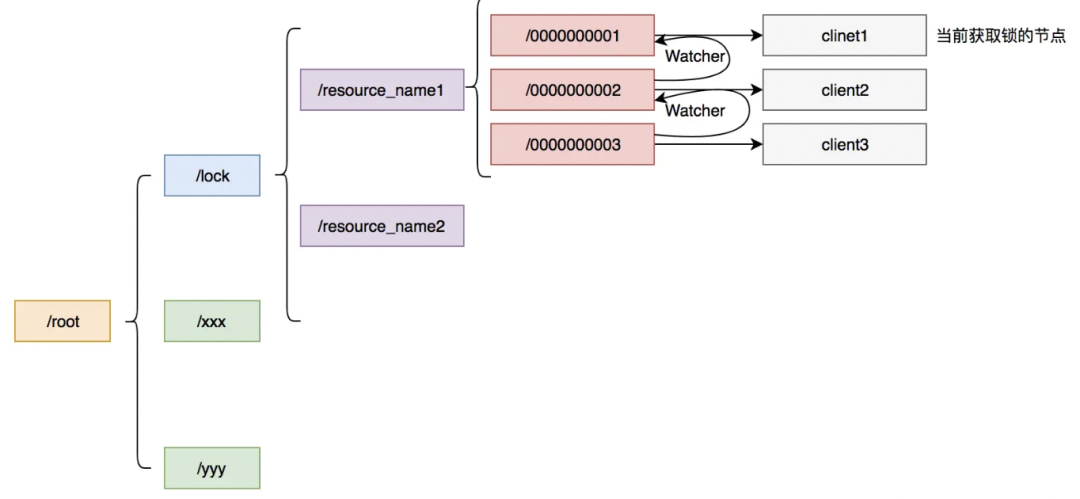
Curator[7]封装了ZooKeeper底层的Api,使我们更加容易方便的对ZooKeeper进行操作,并且它封装了分布式锁的功能。
Etcd实现分布式锁的原理与ZK大致相同,对比大致如下[8][9]:
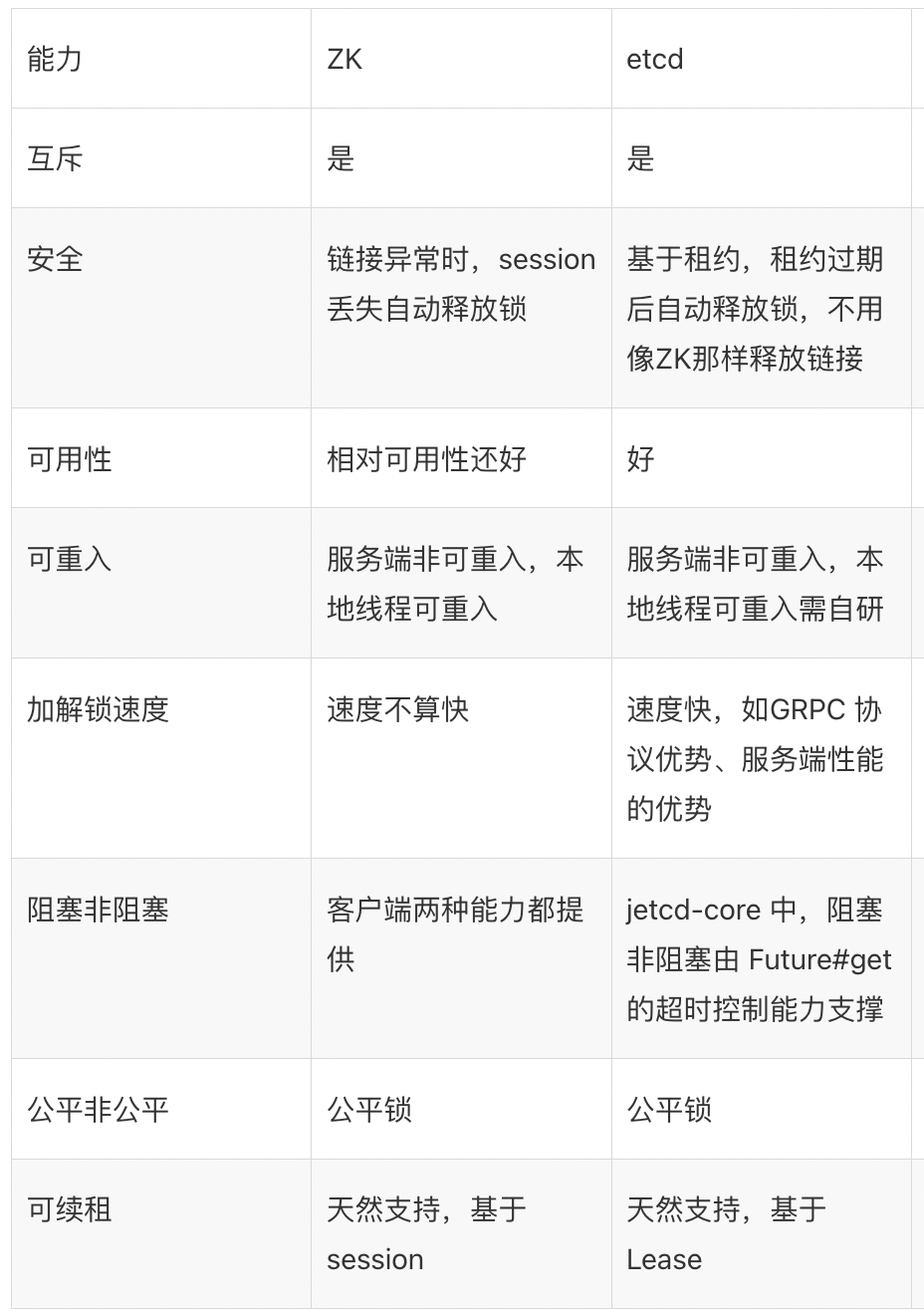
Etcd实现分布式锁,也可以基于自带的concurrency包[10]实现。
面试官:你觉得哪种分布式锁方案是最优的?
根据上面的分析,考虑网络延迟、GC、时钟等因素后,没有一种分布式锁方案是能完美保证分布式锁的正确性(互斥性)的。
但是,对于分布式锁来说,在上层完成互斥,虽然极端情况下锁会失效,但是它可以最大程度把并发请求阻挡在外,减轻操作资源层的压力。
对于要求数据绝对正确的业务,在资源层一定要做好兜底,比如先拿到标记位,在修改共享资源之前,先校验标记位是否和之前拿到的一致,类似CAS的操作实现:
UPDATE table_name SET data = #{new_data} WHERE id = #{id} AND current_token = #{current_lock_token}
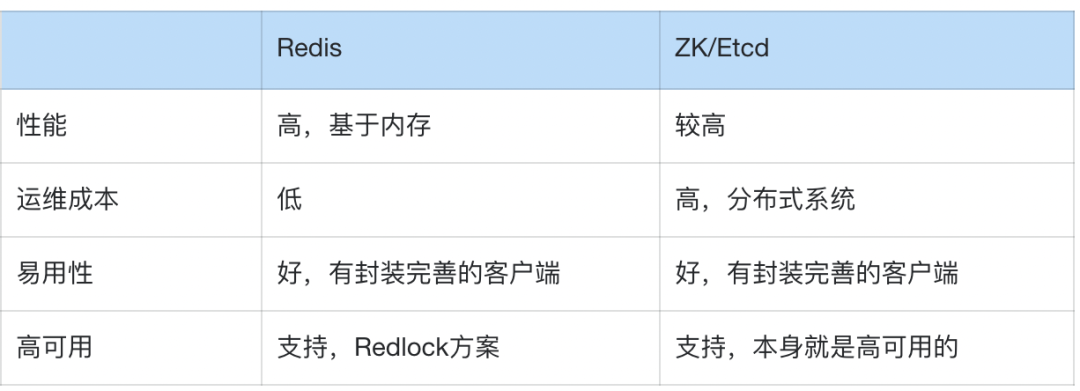
明白了这点,我们再来说下Redis与ZK/Etcd的方案主要异同点:
(1)性能:Redis基于内存,读写性能高,适合高并发。ZK/Etcd相对弱一些。
(2)运维成本:Redis更常用、是基础组件,运维也更简单。ZK/Etcd都是分布式系统,运维相对复杂一些。
(3)易用性:都有较成熟的客户端封装,差别不大。
(4)高可用:均支持,Redis采用Redlock方案,ZK/Etcd本身就是高可用的。
如下图所示:
了解了优缺点后,可根据实际场景灵活选取,脱离场景,没法说有明显的优劣之分。
结语
Martin和Redis作者Antirez关于Redlock的话题,引起了各方激烈的争论。Martin在这件事过去之后,写下了自己的感悟:
我并不在乎在这场辩论中谁对谁错——我只关心从其他人的工作中学到的东西,以便我们能够避免重蹈覆辙,并让未来更加美好。前人已经为我们创造出了许多伟大的成果:站在巨人的肩膀上,我们得以构建更棒的软件。
……
对于任何想法,务必要详加检验,通过论证以及检查它们是否经得住别人的详细审查。那是学习过程的一部分。但目标应该是为了获得知识,而不应该是为了说服别人相信你自己是对的。有时候,那只不过意味着停下来,好好地想一想。
共勉!
参考:
[1]https://github.com/redisson/redisson
[2]https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
[3]http://antirez.com/news/101
[4]https://www.zhihu.com/question/300767410/answer/1931519430
[5]http://zhangtielei.com/posts/blog-redlock-reasoning-part2.html
[6]https://juejin.cn/post/6844903688088059912
[7]https://github.com/apache/curator
[8]https://www.51cto.com/article/721408.html
[9]https://www.51cto.com/article/722138.html
[10]https://github.com/etcd-io/etcd/tree/v3.4.9/clientv3/concurrency
[11]https://time.geekbang.org/column/article/350285
笔者刚创建了一个面试互助&技术交流群,微服务框架开源大牛助阵,有问必答,欢迎大家扫码加入,一起学习交流!

本篇文章来源于微信公众号: 程序员Aike
微信扫描下方的二维码阅读本文

Comments NOTHING