回答了Redis通过RDB、AOF日志可以保障数据不丢失后,面试官觉得你对Redis的基本原理了解得还不错,决定进一步探探你的“底”,直接抛出Redis如何保障高可用的问题,想考查下你对分布式系统的掌握怎么样。
面试官:Redis是如何保障高可用的?
你想了想,给出如下回答:
Redis一般通过主从复制机制保障Redis始终处于可用状态,可以部署一主一从或者一主多从来保障主节点故障时,从节点可以提升为新的主节点,继续提供服务。
为了自动实现这一过程,Redis提供了哨兵模式,通过哨兵检测主节点的健康状况,一旦主节点出现故障,哨兵会根据预设规则选举出新的主节点,继续向外提供服务。
Redis还提供了集群模式采用数据分片(Sharding)策略,将数据均匀分布到多个节点上,每个节点独立处理一部分数据。这样既分散了单节点的压力,也降低了单点故障对整体系统的影响。
面试官:好的,能具体介绍下Redis的主从复制机制吗?
主从复制(Replication):
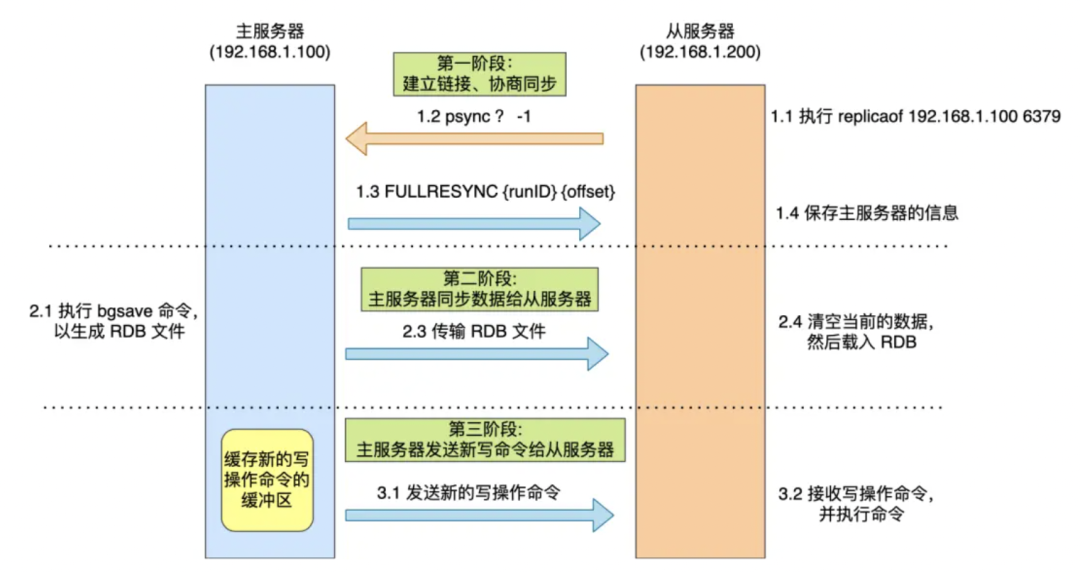
(1)基础原理:Redis通过主从复制机制实现数据的备份与同步。在一个Redis集群中,存在一个主节点(Master)和至少一个从节点(Slave)。主节点负责处理客户端写请求并将其操作日志(即RDB快照或AOF日志)发送给从节点。从节点接收并执行这些日志,从而保证自身数据与主节点一致,实现数据的实时备份。主从复制的数据首次同步流程如下图[1]:
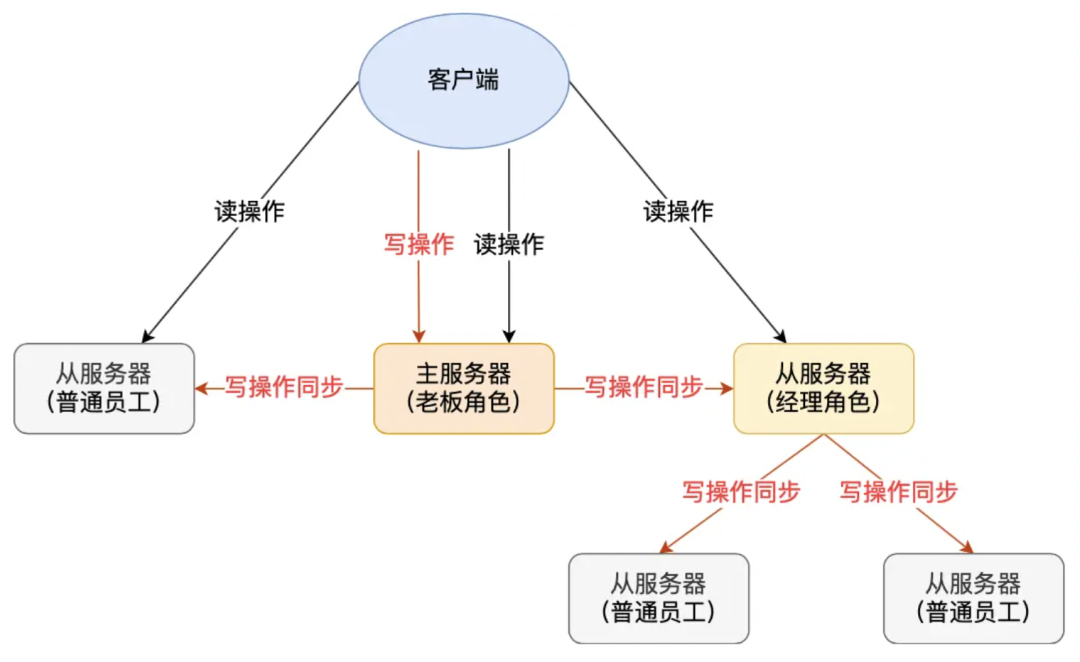
如果从节点都跟随主节点,那么主节点的压力会比较大,所以推荐需要部署更多的从节点分摊读请求压力时,从节点跟随上游的从节点即可,如下图所示[1]:
(2)故障切换:当主节点发生故障时,从节点可被提升为新的主节点,继续提供服务。这种机制确保了即使单点故障,系统仍能保持对外服务,保障了数据的高可用性。但是需要手工操作。
面试官:那哨兵又是怎么一回事呢?
哨兵模式(Sentinel):
Redis 在 2.8 版本以后提供的哨兵(Sentinel)机制,它的作用是实现主从节点故障转移。Sentinel是一个独立的进程,用于监控Redis主从集群的运行状态,包括节点存活、主从关系、数据同步等。它提供了自动故障检测、故障转移、配置通知等功能,极大地提升了Redis集群的自动化运维能力[2]。
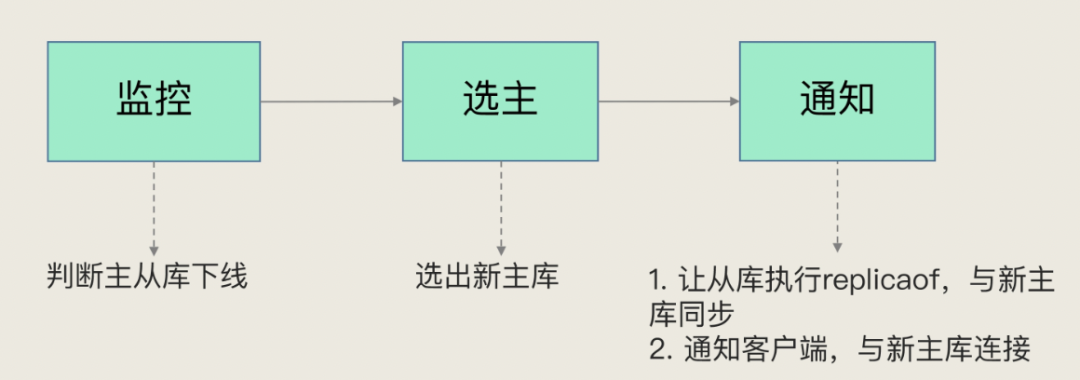
Sentinel主要负责的就是三个任务:
1、监控:监控主库运行状态,并判断主库是否客观下线;
2、选主(选择主库):在主库客观下线后,选取新主库;
3、通知。选出新主库后,通知从库(从库执行replicaof命令,与新主库同步)和客户端(通知客户端与新主库连接)。
如何判断主节点真的故障了?
哨兵会每隔 1 秒给所有主从节点发送 PING 命令,当主从节点收到 PING 命令后,会发送一个响应命令给哨兵,这样就可以判断它们是否在正常运行。如果在规定时间内没有响应,哨兵就会标记主节点「主观下线」,如果询问其他哨兵得到半数以上的反馈为主节点下线,就会标记主节点「客观下线」。
如何选出主节点?
哨兵自己先确定谁是leader来执行选主,即:投票自己为leader,半数以上节点同意。之后从从节点中选出新的主节点,规则如下:
1、第一轮考察:优先级最高的从节点胜出
2、第二轮考察:复制进度最靠前的从节点胜出
3、第二轮考察:复制进度最靠前的从节点胜出
面试官:那为什么还需要Redis Cluster呢?集群模式的作用是什么?
当 Redis 缓存数据量大到一台服务器无法缓存时,就需要使用 Redis 切片集群(Redis Cluster )方案,它将数据分布在不同的服务器上,以此来降低系统对单主节点的依赖,从而提高 Redis 服务的读写性能。
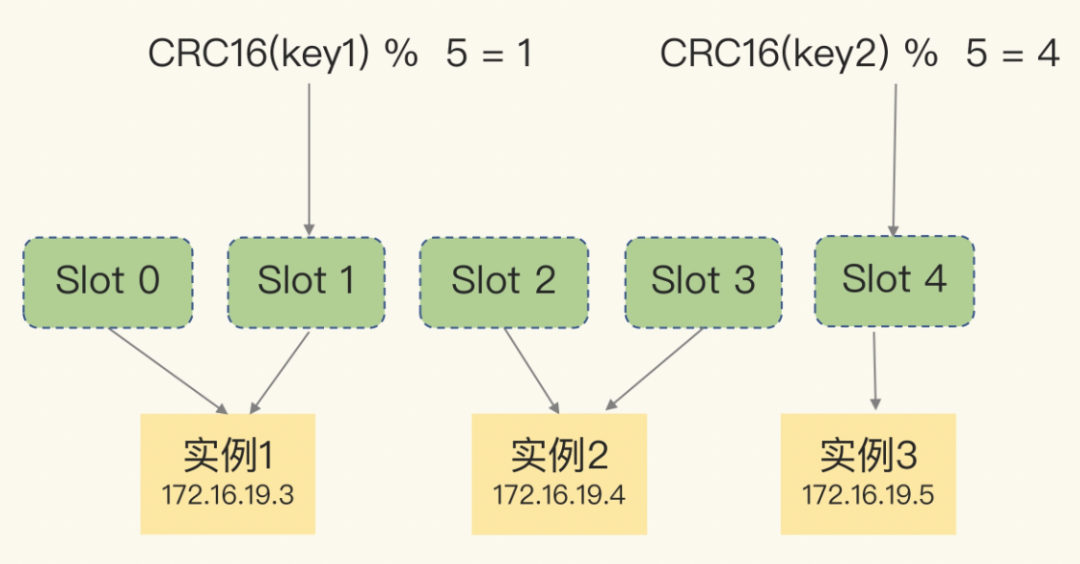
Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和节点之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中,具体执行过程分为两大步:
1、根据键值对的 key,按照 CRC16 算法(opens new window)计算一个 16 bit 的值。
2、再用 16bit 值对 16384 取模,得到0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
Redis Cluster采用数据分片(Sharding)策略,将数据均匀分布到多个节点上,每个节点独立处理一部分数据。这样既分散了单节点的压力,也降低了单点故障对整体系统的影响。客户端通过哈希槽(Hash Slot)机制透明地寻址到正确的节点进行读写操作。如下图[3]:
对于客户端如何找到数据,RedisCluster方案提供了一种重定向机制,所谓的“重定向”,就是指,客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令[3]。
如果 Slot 正在迁移,则客户端会收到一条 ASK 报错信息,告诉客户端正在迁移(ASK 命令并不会更新客户端缓存的哈希槽分配信息),此时,客户端需要先给 Slot 所在的实例发送一个 ASKING 命令,表示让这个实例运行执行客户端接下来发送的命令,然后客户端再向这个实例发送对应的操作命令。
Cluster节点间通过Gossip协议进行通信,共享集群状态信息,包括节点新增、移除、主从切换等。当某个主节点故障时,其对应的从节点会发起选举成为新主节点,同时其他节点及客户端会收到更新通知,自动调整连接。此过程无需人工干预,实现了自动化的故障恢复。
面试官:那你知道什么是脑裂吗?
还好这个你也了解过:
由于网络问题,集群节点之间失去联系。主从数据不同步;重新平衡选举,产生两个主服务。等网络恢复,旧主节点会降级为从节点,再与新主节点进行同步复制的时候,由于会从节点会清空自己的缓冲区,所以导致之前客户端写入的数据丢失了[4]。
解决方案是:
当主节点发现从节点下线或者通信超时的总数量小于阈值时,那么禁止主节点进行写数据,直接把错误返回给客户端。在 Redis 的配置文件中有两个参数我们可以设置:
1、min-slaves-to-write x,主节点必须要有至少 x 个从节点连接,如果小于这个数,主节点会禁止写数据。
2、min-slaves-max-lag x,主从数据复制和同步的延迟不能超过 x 秒,如果超过,主节点会禁止写数据。
我们可以把 min-slaves-to-write 和 min-slaves-max-lag 这两个配置项搭配起来使用,分别给它们设置一定的阈值,假设为 N 和 T。
这两个配置项组合后的要求是,主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的写请求了。
等到新主库上线时,就只有新主库能接收和处理客户端请求,此时,新写的数据会被直接写到新主库中。而原主库会被哨兵降为从库,即使它的数据被清空了,也不会有新数据丢失。
结语
Redis通过主从复制、哨兵模式、集群模式等多维度构建了强大的高可用体系:
1、主从复制与哨兵模式,实现了节点间的实时数据同步与自动故障转移,确保在单点故障时服务连续性;
2、集群模式通过数据分片与节点间通信,有效分散系统压力,降低单点故障风险,提供水平扩展能力。
面对面试官关于Redis如何保障高可用性的提问,我们可以自信地阐述上述策略与技术手段,展现对Redis高可用特性的深入理解和掌握。
参考:
[1]https://xiaolincoding.com/redis/cluster/master_slave_replication.html
[2]https://xiaolincoding.com/redis/cluster/sentinel.html
[3]https://time.geekbang.org/column/article/276545
[4]https://xiaolincoding.com/redis/base/redis_interview.html
点击关注我,交个朋友吧!
本篇文章来源于微信公众号: 程序员Aike
微信扫描下方的二维码阅读本文

Comments NOTHING