前言
作为一名后端开发,我们经常需要设计数据库表,以下是我整理的一些MySQL表的经验,希望可以给大家一点参考和帮助
1.命名规范
数据库表名、字段名、索引名等都需要命名规范
-
表名、字段名必须使用小写字母或数字(不推荐) 禁止使用数字开头,禁止使用拼音,并且一般不使用英文缩写
-
主键索引名为
pk_字段名; 唯一索引名为uk_字段名; 普通索引名为idx_字段名
看个反例
CREATETABLEuser_info_tab(`id`int(11)NOTNULLAUTO_INCREMENT,`user_id`int(11)NOTNULL,`age`int(11)DEFAULTNULL,`name`varchar(255)NOTNULL,`create_time`datetimeNOTNULL,`modifed_time`datetimeNOTNULL,PRIMARYKEY(`id`),KEY`idx_name`(`name`)USINGBTREE,UNIQUEKEYun_user_id(user_id))ENGINE=InnoDBDEFAULTCHARSET=utf8;9.不需要严格遵守3NF,通过业务字段冗余来减少表关联
什么是数据库三范式(3NF),大家是否还有印象吗?
-
第一范式: 对属性的原子性,要求属性具有原子性,不可再分解;
-
第二范式: 对记录的唯一性,要求记录有唯一标识,即实体的唯一性,即不存在部分依赖;
-
第三方式: 对字段的冗余性,要求任何字段不能由其他字段派生出来,它要求字段没有冗余,即不存在传递依赖;
我们设计表及其字段之间的关系, 应尽量满足第三范式。但是有时候,可以适当冗余,来提高效率。比如以下这张表

以上这张存放商品信息的基本表。总金额这个字段的存在,表明该表的设计不满足第三范式,因为总金额可以由单价*数量得到,说明总金额是冗余字段。
但是,增加总金额这个冗余字段,可以提高查询统计的速度,这就是以空间换时间的作法。
10.不使用外键,都在代码层维护
阿里的Java开发规范也明确规定了
“
【强制】不得使用外键与级联,一切外键概念必须在应用层解决。
我们为什么不推荐使用外键呢?
使用外键存在性能问题、并发死锁问题、使用起来不方便等等。每次做DELETE或者UPDATE都必须考虑外键约束会导致开发的时候很难受,测试数据造数据也不方便。
还有一个场景不能使用外键,就是分库分表。
11.没有特殊场景一般都选择INNODB存储引擎
建表是需要选择 存储引擎 的,我们一般都选择 INNODB 存储引擎,除非读写比率小于1%,才会考虑使用MyISAM(也就是基本上都是读的场景)
12.时间类型的选择
我们设计表的时候,一般都需要加通用时间的字段,如 create_time、update_time 等等,那对于时间的类型,我们应该如何选择呢?
对于MySQL来说,主要有 date、datetime、time、timestamp 和 year
-
date : 表示的日期值, 格式
yyyy-mm-dd,范围1000-01-01到9999-12-31,3字节 -
time : 表示的时间值,格式
hh:mm:ss,范围-838:59:59到838:59:59,3字节 -
datetime: 表示的日期时间值,格式
yyyy-mm-dd hh:mm:ss,范围1000-01-01 00:00:00到9999-12-31 23:59:59,8字节,跟时区无关 -
timestamp: 表示的时间戳值,格式为
yyyymmddhhmmss,范围1970-01-01 00:00:01到2038-01-19 03:14:07,4字节,跟时区有关 -
year: 年份值,格式为yyyy。范围1901到2155,1字节
看那么多,眼睛都累了。
“
直接总结一下:推荐优先使用datetime类型来保存日期和时间,因为存储范围更大,且跟时区无关
13.不建议在数据表中使用Text数据类型,而要单独开一张表放Text类型的数据呢?
从BufferPool的角度考虑一下,大家认为BufferPool有什么关系呢?
一开始我是这样考虑的,Text字段一般来说会很大,如果要加载到BufferPool里面,会把内存撑爆?
我一开始是从这个角度去想的,但是后来想想,无论要不要将Text类型的字段的数据单独放到一张表,都不影响加载到BufferPool,所以撑爆内存的这个角度想不太对
换个角度,换到索引的角度去想一下
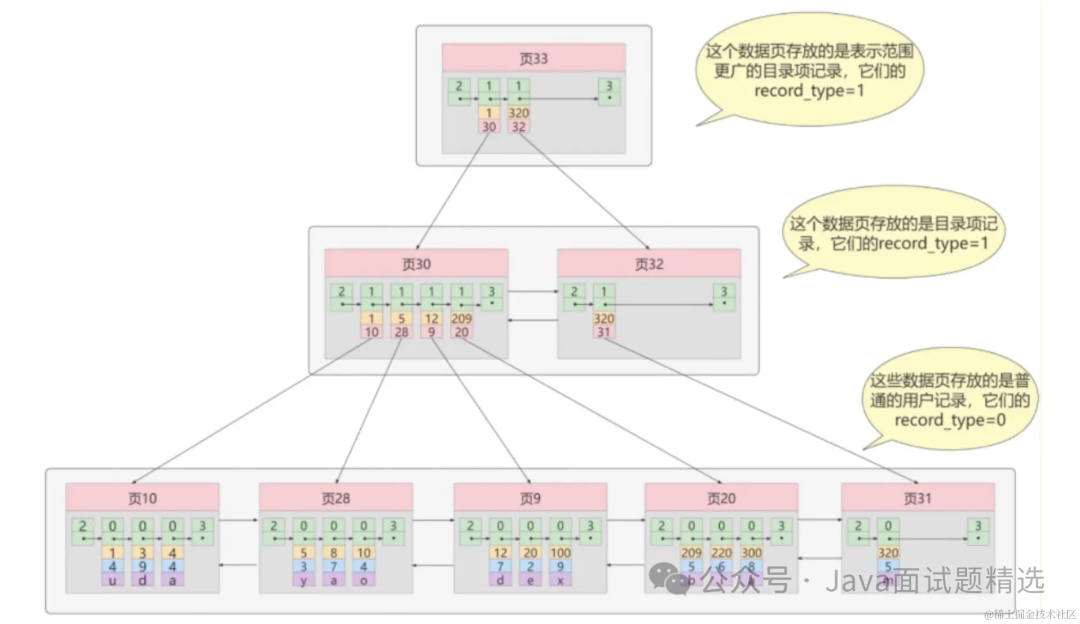
在MySQL的InnoDB引擎下,我们是通过B+树去存储索引结构的,在B+树中真正存储数据的都是叶子节点
而且我们一页只能存放16KB大小的数据,如果说你把Text数据和其他数据同时放在一张表,那么一条记录会比没放Text的时候要大很多,导致一个索引页存放的数据条数大大的减少
14.考虑是否需要分库分表
什么是分库分表呢?
-
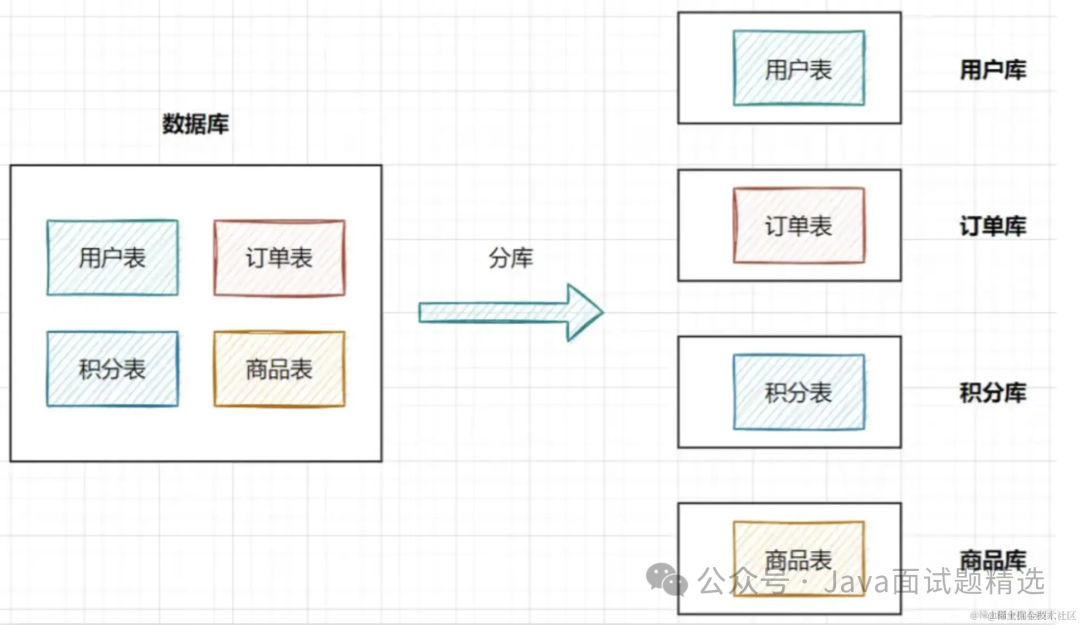
分库:就是一个数据库分成多个数据库,部署到不同机器。
-
分表:就是一个数据库表分成多个表。
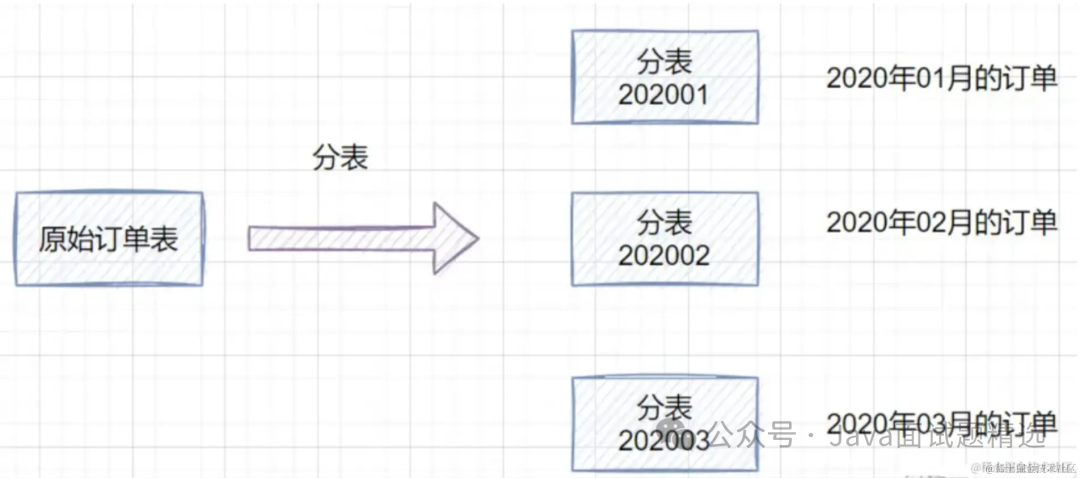
我们在设计表的时候,其实可以提前估算一下,是否需要做分库分表。比如一些用户信息,未来可能数据量到达百万设置千万的话,就可以提前考虑分库分表。
为什么需要分库分表?
1.数据量太大的话,SQL的查询就会变慢。
2.如果一个查询SQL没命中索引,千百万数据量级别的表可能会拖垮整个数据库。
3.即使SQL命中了索引,如果表的数据量超过一千万的话,查询也是会明显变慢的。这是因为索引一般是B+树结构,数据千万级别的话,B+树的高度会增高,查询就变慢了,因为磁盘IO次数变多了
15.sql编写的一些优化经验
-
查询SQL不要使用
select *,而是select(具体字段) -
避免在where子句中使用or来连接条件(可能会导致索引失效,因为or要两个条件都有索引)、
-
避免在索引列上使用mysql的内置函数
-
避免在where子句中对字段进行表达式操作,还有隐式转换
-
避免在where子句中使用
!=或<>操作符 -
使用联合索引时,注意索引列的顺序,一般遵循最左匹配原则。
-
对查询进行优化,应考虑在where及order by涉及的列上建立索引
-
如果插入数据过多,考虑批量插入
-
在适当的时候,使用覆盖索引
-
使用explain 分析你SQL的计划
16.总结
以上就是我对MySQL表设计的一些经验,在优化上面可能还有很多优化的经验,希望大家可以在评论区多交流下sql优化的经验
来源:juejin.cn/post/7350936959060541480
构建高质量的技术交流社群,欢迎从事编程开发、技术招聘HR进群,也欢迎大家分享自己公司的内推信息,相互帮助,一起进步!
文明发言,以
交流技术、职位内推、行业探讨为主
广告人士勿入,切勿轻信私聊,防止被骗

加我好友,拉你进群

本篇文章来源于微信公众号: Java面试题精选
微信扫描下方的二维码阅读本文

Comments NOTHING